基于LMS算法的FIR滤波器系统辨识
系统辨识是用自适应滤波器辨识未知系统的系数的过程。该过程的总体概况显示在系统识别——使用自适应滤波器识别未知系统.涉及的主要组成部分有:
自适应滤波算法。在本例中,设置
方法的属性dsp。LMSFilter来“LMS”选择LMS自适应滤波算法。要适应的未知系统或过程。在本例中,由
fircband是未知的系统。适当的输入数据来练习适应过程。对于一般的LMS模型,这些是所需的信号 输入信号 .
自适应滤波器的目标是使自适应滤波器输出之间的误差信号最小 和未知系统(或待识别系统)的输出 .一旦错误信号最小化,自适应滤波器就与未知系统相似。两个滤波器的系数匹配得很好。
请注意如果你正在使用R2016a或更早的版本,用等价的步骤语法替换每个对象调用。例如,obj (x)就变成了步骤(obj, x).
未知的系统
创建一个dsp。FIRFilter对象,该对象表示要标识的系统。使用fircband函数设计滤波系数。设计的滤波器为阻带波纹限制在0.2的低通滤波器。
filt = dsp.FIRFilter;filt。分子= fircband(12,[0 0.4 0.5 1],[1 10 0 0],[1 0.2],...{' w '“c”});
通过信号x到FIR滤波器。所需的信号d是未知系统(FIR滤波器)输出和加性噪声信号的和吗n.
x = 0.1 * randn (250 1);n = 0.01 * randn (250 1);D = filt(x) + n;
自适应滤波器
在未知滤波器设计和期望信号到位后,创建并应用自适应LMS滤波器对象来识别未知滤波器。
准备自适应滤波器对象需要估计滤波器系数和LMS步长的初始值(μ).您可以从一些非零值作为过滤器系数的估计值开始。本例使用0表示13个初始过滤器权重。设置InitialConditions的属性dsp。LMSFilter到期望的滤波器权重的初始值。对于步长而言,0.8是一个很好的折中方案,既要足够大,可以在250次迭代(250个输入样本点)内很好地收敛,又要足够小,可以对未知滤波器进行准确的估计。
创建一个dsp。LMSFilter对象表示使用LMS自适应算法的自适应滤波器。设置自适应过滤器的长度为13点,步长为0.8。
μ= 0.8;lms = dsp。LMSFilter(13,“StepSize”μ)
lms = dsp。LMSFilterwith properties: Method: 'LMS' Length: 13 StepSizeSource: 'Property' StepSize: 0.8000 LeakageFactor: 1 InitialConditions: 0 AdaptInputPort: false WeightsResetInputPort: false WeightsOutput: 'Last' Show all properties
传递一次输入信号x和期望的信号d到LMS滤波器。运行自适应过滤器确定未知系统。输出y自适应滤波器的特征是信号收敛到期望信号d从而最小化误差e在两个信号之间。
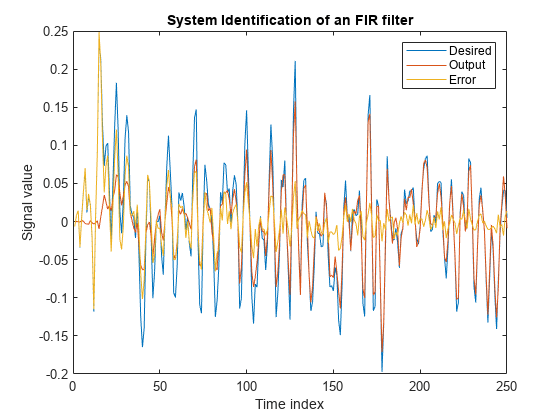
策划的结果。输出信号与期望的信号不匹配,使得两者之间的误差非常大。
[y, e, w] = lms (x, d);情节(摘要[d, y, e])标题(“FIR滤波器的系统识别”)传说(“想要的”,“输出”,“错误”)包含(“时间指数”) ylabel (的信号值)
比较权重
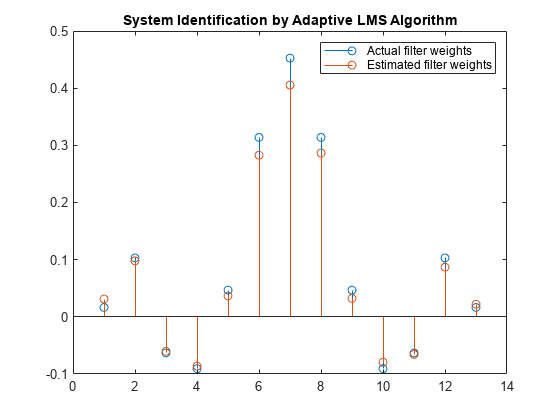
权重向量w表示适应于类似于未知系统的LMS滤波器(FIR滤波器)的系数。为了确定收敛性,将FIR滤波器的分子与自适应滤波器的估计权值进行比较。
估计的滤波器权值与实际的滤波器权值并不密切匹配,这证实了在前面信号图中看到的结果。
茎([(filt.Numerator)。' w])标题(“自适应LMS算法识别系统”)传说(实际滤波器权重的,“估计滤波器权重”,...“位置”,“东北”)
更改步长
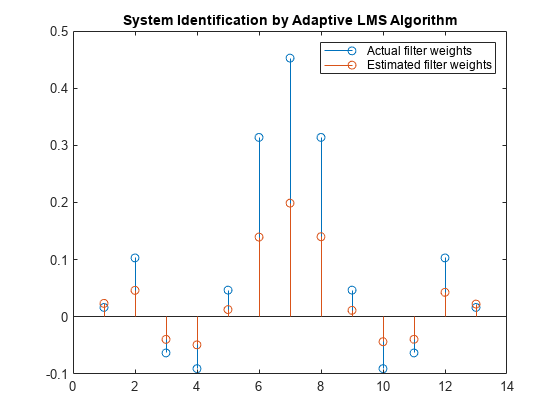
作为实验,将步长更改为0.2。重复这个例子μ= 0.2结果如下茎图。滤波器不收敛,估计的权值不是实际权值的很好近似。
μ= 0.2;lms = dsp。LMSFilter(13,“StepSize”μ);(~ ~ w) = lms (x, d);茎([(filt.Numerator)。' w])标题(“自适应LMS算法识别系统”)传说(实际滤波器权重的,“估计滤波器权重”,...“位置”,“东北”)
增加数据样本的数量
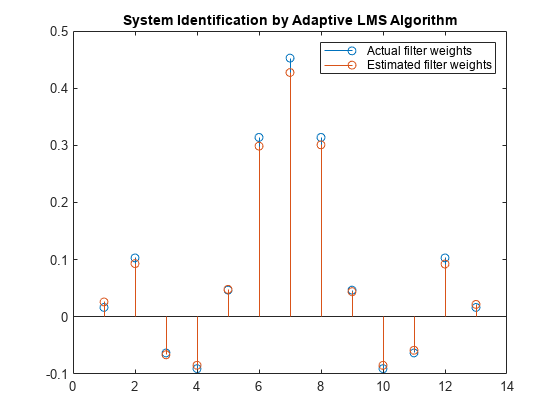
增加所需信号的帧大小。尽管这增加了所涉及的计算量,但LMS算法现在有更多的数据可以用于适应。在1000个样本的信号数据,步长为0.2的情况下,系数排列比之前更接近,收敛性得到了改善。
释放(filt);x = 0.1 * randn (1000 1);n = 0.01 * randn (1000 1);D = filt(x) + n;[y, e, w] = lms (x, d);茎([(filt.Numerator)。' w])标题(“自适应LMS算法识别系统”)传说(实际滤波器权重的,“估计滤波器权重”,...“位置”,“东北”)
通过迭代输入数据,进一步增加数据样本的数量。在4000个样本数据上运行算法,这些数据在4次迭代中以1000个样本分批传递给LMS算法。
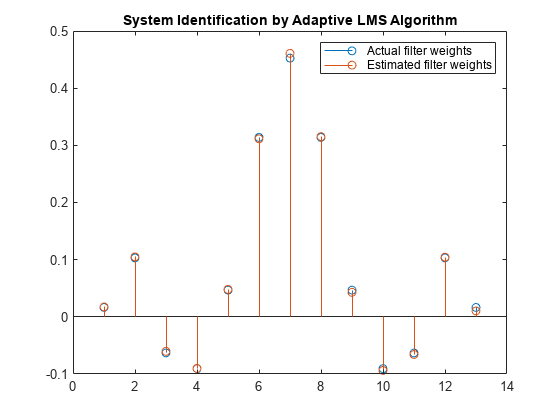
比较过滤器权重。LMS滤波器的权值与FIR滤波器的权值非常接近,具有很好的收敛性。
释放(filt);n = 0.01 * randn (1000 1);为Index = 1:4 x = 0.1*randn(1000,1);D = filt(x) + n;[y, e, w] = lms (x, d);结束茎([(filt.Numerator)。' w])标题(“自适应LMS算法识别系统”)传说(实际滤波器权重的,“估计滤波器权重”,...“位置”,“东北”)
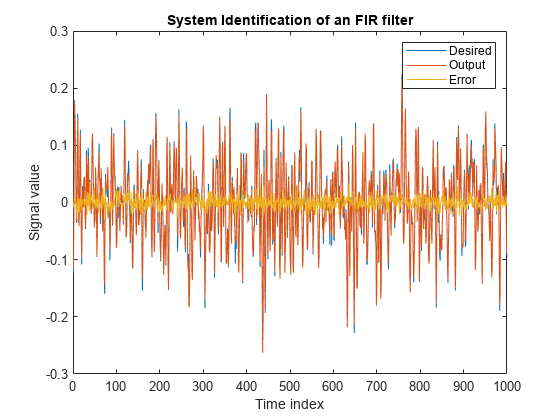
输出信号与所需信号非常匹配,使得两者之间的误差接近于零。
情节(1:1000 [d, y, e])标题(“FIR滤波器的系统识别”)传说(“想要的”,“输出”,“错误”)包含(“时间指数”) ylabel (的信号值)
另请参阅
对象
相关的话题
参考文献
海耶斯(Monson H. Hayes)统计数字信号处理与建模.霍博肯:John Wiley & Sons, 1996,第493 - 552页。
[2]微积分,西门,自适应滤波器理论.上鞍河,新泽西州:Prentice-Hall, Inc., 1996。
你也可以从以下列表中选择一个网站: