估计滤波器简介
背景
评估系统
对于许多自治系统来说,了解系统状态是设计任何应用程序的先决条件。然而,在现实中,这种状态往往是不能直接获得的。系统状态通常是根据某些仪器(如传感器)测量的系统输出和由动态或运动模型控制的状态流来推断或估计的。一些简单的技术,如最小二乘估计或批估计,足以解决静态或离线估计问题。对于在线和实时(顺序)估计问题,通常采用更复杂的估计滤波器。
一个估计系统由描述状态流动的动态或运动模型和描述如何获得测量的测量模型组成。数学上,这两个模型可以用一个运动方程和一个测量方程来表示。例如,一般非线性离散估计系统的运动方程和测量方程可表示为:
在哪里k为时间步长,xk系统状态在时间步长吗k,f(xk)是与状态相关的运动方程,h(xk)为与状态相关的测量方程,且yk是输出。
噪声分布
在大多数情况下,建立一个完美的模型来捕捉所有的动态现象是不可能的。例如,在自动驾驶汽车的运动模型中包含所有摩擦力是不可能的。为了补偿这些未建模的动态,处理噪声(w)常常被添加到动态模型中。此外,在进行测量时,不可避免地会包含多个误差源,如校准误差。为了解释这些误差,必须在测量模型中加入适当的测量噪声。包含这些随机噪声和误差的估计系统称为随机估计系统,可以表示为:
在哪里wk和vk分别表示过程噪声和测量噪声。
对于大多数工程应用,过程噪声和测量噪声被假定为服从零均值高斯分布或正态分布,或至少近似为高斯分布。此外,由于确切的状态是未知的,状态估计是一个随机变量,通常假定服从高斯分布。假设这些变量的高斯分布极大地简化了估计滤波器的设计,并形成了卡尔曼滤波器族的基础。
随机变量的高斯分布(x)被一个平均值参数化μ还有协方差矩阵P,写成x∼N(μ,P).给定一个高斯分布,均值,也是最可能的值x,由期望(E):
平均数也称为第一矩x关于原点。描述不确定性的协方差x定义为期望(E):
协方差也称为二阶矩x对其的意思。
如果x是1,P只是一个标量。在这种情况下,值P通常表示为σ2和方差。的平方根,σ,称为标准偏差x.标准差具有重要的物理意义。例如,下图显示了概率密度函数(描述了……的可能性)x取某一特定值)对于均值为的一维高斯分布μ标准差等于σ.约68%的数据在1以内σ边界的x, 95%的数据属于2σ99.7%的数据在3σ边界。
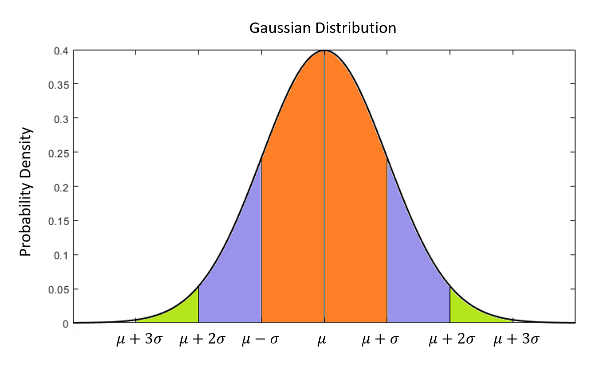
尽管高斯分布假设在工程应用中占主导地位,但也存在一些系统的状态不能用高斯分布近似表示。在这种情况下,需要使用非卡尔曼滤波器(如粒子滤波器)来准确估计系统状态。
滤波器的设计
设计滤波器的目的是利用测量和系统动力学估计系统的状态。由于测量通常是在离散时间步骤,滤波过程通常分为两个步骤:
预测:传播离散测量时间步长的状态和协方差(k= 1, 2, 3,…N)使用动态模型。此步骤也称为流更新。
修正:使用测量值修正离散时间步长的状态估计和协方差。这个步骤也称为测量更新。
表示不同步骤中的状态估计和协方差状态,xk|k和Pk|k表示时间步校正后的状态估计和协方差k,而xk+ 1 |k和Pk+ 1 |k表示从前一个时间步骤预测的状态估计和协方差k到当前时间步长k+1.
预测
在预测步骤中,状态传播很简单。过滤器只需要将状态估计代入到动态模型中,并将其及时转发为xk+ 1 |k=f(xk|k).
协方差传播更复杂。如果估计系统是线性的,那么协方差可以传播(Pk|k→Pk+ 1 |k)在一个基于系统性质的标准方程中。对于非线性系统,精确的协方差传播是一个挑战。不同过滤器之间的主要区别是它们如何传播系统协方差。例如:
线性卡尔曼滤波器使用线性方程精确传播协方差。
扩展卡尔曼滤波器在线性近似的基础上传播协方差,当系统高度非线性时产生较大的误差。
无迹卡尔曼滤波器使用无迹变换对协方差分布进行采样并在时间上传播。
状态和协方差的传播方式也极大地影响了滤波器的计算复杂度。例如:
线性卡尔曼滤波器使用线性方程精确传播协方差,这通常是计算效率高的。
扩展卡尔曼滤波器采用线性逼近,需要计算雅可比矩阵,需要更多的计算资源。
无迹卡尔曼滤波器需要对协方差分布进行采样,因此需要多个采样点的传播,这对于高维系统来说代价很高。
修正
在校正步骤中,滤波器通过测量反馈来校正状态估计。基本上,真实测量和预测测量之间的差被加到状态估计中,然后乘以一个反馈增益矩阵。例如,在扩展卡尔曼滤波器中,状态估计的校正为:
正如前面提到的,xk+ 1 |k状态估计前(先验)校正和xk+ 1 |k+1为(后验)修正后的状态估计。Kk为最优准则控制的卡尔曼增益,yk真正的测量,和h(xk+ 1 |k)是预测的测量值。
在校正步骤中,滤波器还校正了估计误差协方差。其基本思想是修正概率分布x使用分布信息yk + 1.这被称为后验概率密度x鉴于y.在过滤器中,预测和校正步骤是递归处理的。流程图显示了卡尔曼滤波器的一般算法。
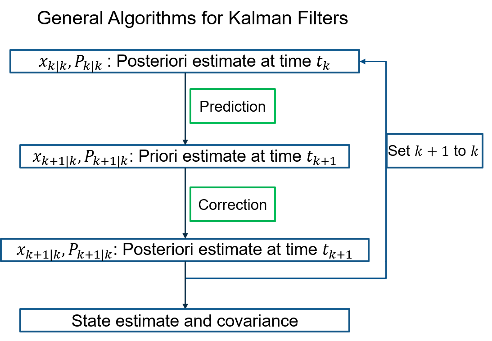
传感器融合与跟踪工具箱中的估计滤波器
传感器融合和跟踪工具箱™提供多个估计滤波器,您可以使用估计和跟踪动态系统的状态。
卡尔曼滤波器
经典卡尔曼滤波器(trackingkf.)是具有高斯过程和测量噪声的线性系统的最优滤波器。线性估计系统可表示为:
过程噪声和测量噪声均假定为高斯噪声,即:
因此协方差矩阵可以通过线性代数方程在测量步骤之间直接传播,如下所示:
测量更新的修正方程为:
计算卡尔曼增益矩阵(Kk)在每个更新中,过滤器需要计算矩阵的倒数:
由于逆矩阵的维数等于估计状态的维数,这种计算需要高维系统的一些计算工作。有关详细信息,请参见线性卡尔曼滤波器.
α-β滤波器
alpha-beta过滤器(trackingABF)是应用于线性系统的次最优滤波器。该滤波器可以看作是简化的卡尔曼滤波器。在卡尔曼滤波中,每一步都动态计算并更新卡尔曼增益和协方差矩阵。然而,在alpha-beta滤波器中,这些矩阵是常数。这种处理牺牲了卡尔曼滤波器的最优性,但提高了计算效率。由于这个原因,当计算资源有限时,alpha-beta过滤器可能是首选。
扩展卡尔曼滤波器
最流行的扩展卡尔曼滤波器(trackingEKF)是对经典卡尔曼滤波器的改进,以适应非线性模型。它的工作原理是将状态估计的非线性系统线性化,忽略二阶和高阶非线性项。它的公式与线性卡尔曼滤波器的公式基本相同,除了一个k和Hk的雅可比矩阵代替卡尔曼滤波中的矩阵f(xk),h(xk):
如果估计系统的真实动态接近线性化的动态,那么使用这种线性近似在短时间内不会产生显著的误差。因此,对于更新间隔较短的轻度非线性估计系统,EKF可以产生相对准确的状态估计。然而,由于EKF忽略了高阶项,对于高度非线性系统(例如四旋翼机),特别是具有较大更新间隔的系统,它可能会发散。
与KF相比,EKF需要导出雅可比矩阵,这要求系统动力学是可微的,并且需要计算雅可比矩阵来线性化系统,这需要更多的计算资产。
注意,对于用球坐标表示状态的估计系统,可以使用trackingMSCEKF.
无味卡尔曼滤波
无迹卡尔曼滤波器(trackingUKF)采用无迹变换(unscented transformation, UT)近似传播非线性模型的协方差分布。UT方法对当前时间的协方差高斯分布进行采样,使用非线性模型传播样本点(称为sigma点),并通过评估这些传播的sigma点来近似假设为高斯的协方差分布。图中显示了不确定性协方差的实际传播、线性传播和UT传播之间的区别。
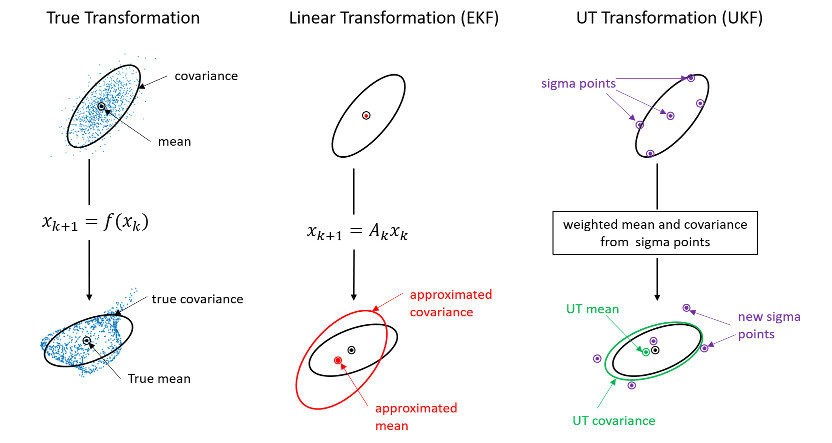
与EKF的线性化方法相比,UT方法能更准确地传播协方差,并能更准确地估计状态,特别是对于高度非线性的系统。UKF不需要雅可比矩阵的推导和计算。然而,UKF需要2的传播n+1 σ指向非线性模型,其中n是估计状态的维度。对于高维系统来说,这在计算上是很昂贵的。
容积卡尔曼滤波
容积卡尔曼滤波器(trackingCKF)采用与UKF略有不同的方法生成2n用于传播协方差分布的样本点,其中n是估计状态的维度。这种交替的样本点集通常会产生更好的统计稳定性,并避免可能在UKF中发生的发散,特别是在单精度平台上运行时。注意,当UKF参数设置为时,CKF本质上等同于UKFα= 1,β= 0,κ= 0。看到trackingUKF这些参数的定义。
高斯和滤波
高斯和滤波器(trackingGSF)使用多个高斯分布的加权和来近似估计状态的分布。估计状态由高斯状态的加权和给出:
在哪里N滤波器中的高斯状态数是否保持不变ck我为对应高斯状态的权值,在每次更新时根据测量值进行修改。多个高斯状态遵循相同的动态模型:
该滤波器可以有效地估计非完全可观测估计系统的状态。例如,当只有距离测量可用时,该滤波器可以使用多个角度参数化扩展卡尔曼滤波器来估计系统状态。看到只用距离测量进行跟踪了一个例子。
交互式多模型滤波器
交互式多模型筛选器(trackingIMM)使用多个高斯滤波器来跟踪目标的位置。在高机动性系统中,系统动力学可以在多个模型之间切换(例如恒定速度、恒定加速度和恒定转弯)。仅使用一个运动模型来建模目标的运动是困难的。多模型估计系统可以描述为:
在哪里我= 1, 2,…米,米为动态模型的总数。该滤波器利用机动目标的多个模型来解决目标运动的不确定性。该过滤器同时处理所有模型,并将总体估计表示为来自这些模型的估计的加权和,其中权重是每个模型的概率。看到机动目标跟踪了一个例子。
粒子滤波
粒子过滤器(trackingPF)不同于卡尔曼滤波器家族(例如EKF和UKF),因为它不依赖于高斯分布假设,对应于使用均值和方差的不确定性参数描述。相反,粒子过滤器创建多个加权样本(粒子)的模拟系统的运行时间,然后分析这些粒子作为一个未知的真实分布的代理。粒子滤波算法的简单介绍如图所示。
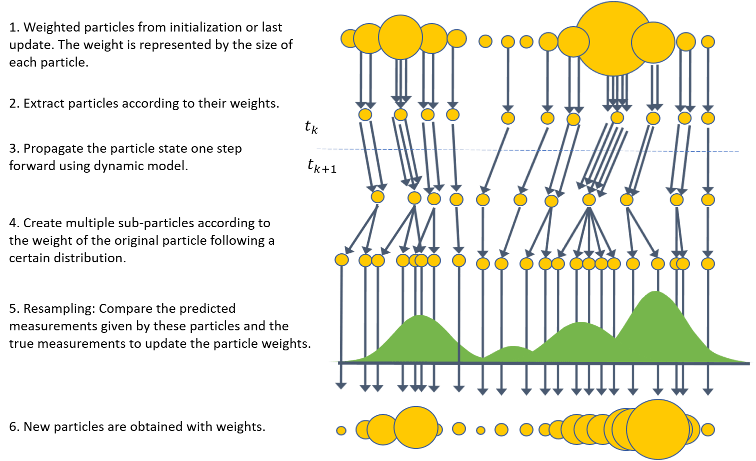
这种方法背后的动机是一个大数定律——当粒子的数量变大时,它们的经验分布接近真实分布。粒子滤波器相对于各种卡尔曼滤波器的主要优点是它可以应用于非高斯分布。该滤波器不受系统动力学的限制,可用于高非线性系统。过滤器的另一个优点是它固有的能力,可以表示关于当前状态的多个假设。由于每个粒子都代表一个带有一定关联可能性的状态假设,粒子滤波器在状态存在模糊的情况下是有用的。
伴随这些吸引人的特性的是粒子滤波器的高计算复杂度。例如,UKF需要传播13个样本点来估计物体的三维位置和速度。然而,一个粒子过滤器可能需要数千个粒子来获得一个合理的估计。此外,实现良好估计所需的粒子数量随状态维数快速增长,并可能导致高维空间中的粒子剥夺问题。因此,粒子过滤器大多应用于具有合理的低维数的系统(例如机器人)。
如何选择跟踪过滤器
下表列出了传感器融合和跟踪工具箱中所有可用的跟踪滤波器,以及在给定系统非线性、状态分布和计算复杂度的约束条件下如何选择它们。
| 过滤器的名字 | 金宝app支持非线性模型 | 高斯状态 | 计算复杂度 | 注释 |
| α-β | 低 | 非最优滤波器。 | ||
| 卡尔曼 | ✓ | 介质低 | 线性系统的最优。 | |
| 扩展卡尔曼 | ✓ | ✓ | 媒介 | 使用线性化模型传播不确定性协方差。 |
| 无味卡尔曼 | ✓ | ✓ | 中等高 | 对不确定度协方差进行抽样,以传播抽样点。在单精度平台上可能会变得数值不稳定。 |
| 容积卡尔曼 | ✓ | ✓ | 中等高 | 对不确定度协方差进行抽样,以传播抽样点。数值稳定。 |
| 高斯和 | ✓ | ✓ (假设分布的加权和) |
高 | 适用于部分可观察的情况(例如仅角度跟踪)。 |
| 交互多模型(IMM) | ✓ 多个模型 |
✓ (假设分布的加权和) |
高 | 操纵物体(例如加速或转弯) |
| 粒子 | ✓ | 很高 | 用加权粒子对不确定度分布进行采样。 |
参考
Wang, E.A,和R. Van Der Merwe。“用于非线性估计的无迹卡尔曼滤波器”。信号处理、通信和控制的自适应系统研讨会。No. 00EX373, 2000, pp. 153-158。
方鸿,田南,王颖,周敏,海乐。非线性贝叶斯估计:从卡尔曼滤波到更广阔的视野。自动化学报。卷。5,第2,2018页,第401-417页。
I. Arasaratnam和S. Haykin。“容积卡尔曼滤波器”。自动控制学报。第54卷第6期,2009年,1254-1269页。
Konatowski, S., P. Kaniewski, J. Matuszewski。EKF、UKF和PF滤波器估计精度的比较年度的导航。第23卷第1期,2016年,69-87页。
[5]达科,J。《对象跟踪:轻松的粒子过滤》https://www.codeproject.com/Articles/865934/Object-Tracking-Particle-Filter-with-Ease。
你也可以从以下列表中选择一个网站: