原生浮点的延迟考虑
HDL Coder™原生浮点技术可以从您的浮点设计生成HDL代码。原生浮点运算符有延迟。当您生成HDL代码时,代码生成器会计算出这种延迟,并添加匹配的延迟来平衡并行路径。
查看浮点运算符的延迟时间
打开hdlcoder_nfp_delay_allocation金宝app仿真软件®模型。该模型使用单数据类型并计算平方根。该模型有一个并行路径来说明代码生成器如何平衡延迟。
load_system (“hdlcoder_nfp_delay_allocation”) open_system (“hdlcoder_nfp_delay_allocation / DUT”)

生成HDL代码:
右键单击
DUT子系统和选择HDL代码>为子系统生成HDL.要查看生成HDL代码后生成的模型,在命令行上输入
gm_hdlcoder_nfp_delay_allocation.
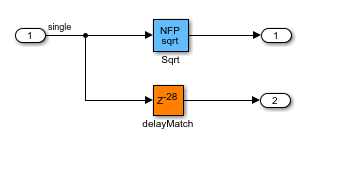
的NFP√6block是与模型中的根号块对应的浮点运算符,其延迟为28.代码生成器确定这个延迟,并添加一个长度匹配的延迟28在平行路径上。要查看平方根操作的延迟时间,双击NFP√6块。的延迟的长度的Sqrt_pd1块对应于操作符延迟。

您可以自定义设计的延迟。使用自定义延迟设置来设计延迟和吞吐量之间的权衡。然后,您可以优化目标FPGA设备上的设计实现,以获得面积和速度。使用以下命令自定义延迟:
延迟策略设置:指定将整个Simulink模型或模型中的单个块映射为浮点运算符的最大、最小或零延迟。金宝app
自定义延迟:您可以为您在Simulink模型中使用的某些块指定自定义延迟。金宝app自定义延迟设置可以从零到浮点运算符的最大延迟。
过采样系数:增加过采样因子以更快的时钟速率运行设计,并利用浮点运算符的延迟吸收时钟速率管道。
模型中的延迟块:如果您的Simulink模型有延迟,HDL Coder金宝app可以用本机浮点实现吸收部分或全部延迟。
模型的延迟策略设置
您可以为整个模型或模型中的单个块指定延迟策略设置。
为模型指定此设置:
在
hdlcoder_nfp_delay_allocation模型,右键单击DUT子系统和选择HDL代码> HDL编码器属性.在HDL代码生成>浮点数,因为图书馆中,选择本机浮点数,然后是延迟策略中,选择马克斯,最小值,或零.

从命令行指定此设置:
创建一个
hdlcoder。FloatingPointTargetConfig对象来获取本机浮点数hdlcoder.createFloatingPointTargetConfig函数。
nfpconfig = hdlcode . createfloatingpointtargetconfig (“NATIVEFLOATINGPOINT”);hdlset_param (“hdlcoder_nfp_delay_allocation”,“FloatingPointTargetConfiguration”, nfpconfig);
属性指定延迟策略
LatencyStrategy财产的nfpconfig对象。
nfpconfig.LibrarySettings.LatencyStrategy =“马克斯”
nfpconfig = FloatingPointTargetConfig属性:Library: 'NativeFloatingPoint' LibrarySettings: [1x1 fpconfig. txt]NFPLatencyDrivenMode] IPConfig: [1x1 hdlcode . floatingpointtargetconfig .IPConfig]
要查看延迟信息,请生成HDL代码,然后打开生成的模型。要打开生成的模型,输入命令gm_hdlcoder_nfp_delay_allocation.
块的自定义延迟策略
对于Simulink模型中的块,您可以金宝app有选择地自定义延迟策略。默认情况下,这些块继承您为模型指定的延迟策略设置。对于某些块,可以指定一个自定义延迟值,该值介于0和浮点运算符的最大延迟之间。
通过指定一个自定义延迟,你可以自定义你的设计,在以下方面进行权衡:
时钟频率和功耗:延迟值越高,最大时钟频率Fmax (maximum Clock frequency)越高,动态功耗越高。
过采样因子和采样频率:较高的延迟值和较高的过采样因子的组合增加了您可以实现的Fmax,但降低了采样频率。
有关此设置以及如何为块指定延迟策略的详细信息,请参见LatencyStrategy.
例如,如果您在模型的并行路径中有一个Add块,您可以指定一个自定义的延迟值2为Add块输入这些命令。
load_system (“hdlcoder_nfp_delay_allocation_custom”) open_system (“hdlcoder_nfp_delay_allocation_custom”) hdlset_param (“hdlcoder_nfp_delay_allocation_custom / DUT /添加”,“LatencyStrategy”,“自定义”) hdlset_param (“hdlcoder_nfp_delay_allocation_custom / DUT /添加”,“NFPCustomLatency”, 2)

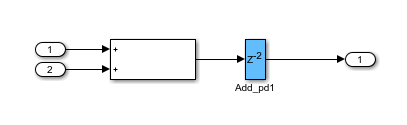
要查看延迟信息,请生成HDL代码,然后打开生成的模型。要打开生成的模型,输入命令gm_hdlcoder_nfp_delay_allocation_custom.在生成的模型中,可以看到NFP添加块的延迟为2.
本地浮点ip的自定义延迟设置
对于具有大量浮点运算符的模型,您可以通过设置NFP运算符的全局自定义延迟来自定义本机浮点ip的延迟。自定义适用于模型中的所有操作符。
例如,如果您有一个具有多个添加和产品块的模型,默认情况下,该块继承为模型指定的延迟策略设置。通过执行这些命令,可以自定义所有时延NFP添加块4所有的NFP mul块3..
load_system (“hdlcoder_nfp_delay_allocation_global_custom”) open_system (“hdlcoder_nfp_delay_allocation_global_custom / Sample_DUT”);hdlset_param (“hdlcoder_nfp_delay_allocation_global_custom”,“FloatingPointTargetConfiguration”,...hdlcoder.createFloatingPointTargetConfig (“NativeFloatingPoint”,“IPConfig”,...{{“ADDSUB”,“单一”,“CustomLatency”4}...,{“ADDSUB”,“双”,“CustomLatency”4}...,{“MUL”,“单一”,“CustomLatency”3}...,{“MUL”,“双”,“CustomLatency”3}}))
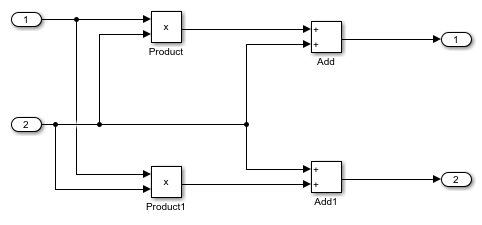
要查看延迟信息,请生成HDL代码,然后打开生成的模型。要打开生成的模型,输入命令gm_hdlcoder_nfp_delay_allocation_global_custom.在生成的模型中,您可以看到所有的NFP添加块的延迟为4所有的NFP mulblock的延迟为3..
有关该命令中的API中用于本机浮点ip的关键字列表,请参阅浮点运算符的延迟值.
过采样因子
在以数据速率设计Simulink模型中的块时,请指定金宝app过采样因子大于1。的过采样因子以更快的时钟速率插入管道寄存器,从而提高时钟频率并减少区域使用。要了解有关时钟速率流水线的更多信息,请参见时钟频率流水线.
来看看效果过采样因子在模型上,在hdlcoder_nfp_delay_allocation模型:
添加一个延迟块延迟的长度
1在Sqrt块的输出。右键单击DUT并选择HDL代码> HDL编码器属性.
在HDL代码生成>全局设置窗格中,输入值为
40为过采样因子.

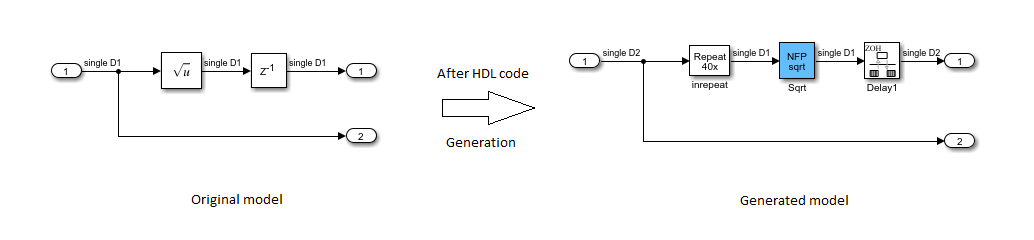
生成HDL代码后,生成的模型显示NFP√6块以比你模型中的根号块快40倍的时钟速率运行。的NFP√6block吸收了Simulink模型中的Delay块。金宝app延迟块现在以时钟速率运行。这种实现通过吸收额外的延迟来节省面积,并通过以更快的时钟速率运行来改善时间。
模型中的延迟吸收
如果您的Simu金宝applink模型有足够的延迟块延迟的长度与操作符相邻,HDL Coder吸收延迟作为操作符延迟的一部分。
如果延迟的长度等于浮点运算符的延迟,HDL Coder吸收延迟而不引入任何额外的延迟。
在hdlcoder_nfp_delay_allocation模型:
双击根号块输出处的延迟块,并更改延迟的长度来
28.生成的HDL代码
DUT子系统。在生成HDL代码之后,在命令行输入
gm_hdlcoder_nfp_delay_allocation打开生成的模型。

在生成的模型中,可以看到NFP√6块吸收了原始模型中与根号块相邻的延迟块。发生这种延迟吸收是因为操作符延迟等于延迟的长度.因此,代码生成器避免了模型中的额外延迟。
如果延迟的长度, HDL Coder吸收可用的延迟,并通过添加匹配的延迟来平衡并行路径。
在hdlcoder_nfp_delay_allocation模型:
双击根号块输出处的延迟块,并更改延迟的长度来
21.生成的HDL代码
DUT子系统。在生成HDL代码之后,在命令行输入
gm_hdlcoder_nfp_delay_allocation打开生成的模型。

你可以看到NFP√6块吸收了长度延迟21并添加了匹配的长度延迟7因为平方根运算需要28延迟。
如果延迟长度大于操作符延迟,代码生成器将吸收与延迟相等的一定数量的延迟,并且多余的延迟出现在操作符之外。
在hdlcoder_nfp_delay_allocation模型:
双击根号块输出处的延迟块,并更改延迟的长度来
34.生成的HDL代码
DUT子系统。在生成HDL代码之后,在命令行输入
gm_hdlcoder_nfp_delay_allocation打开生成的模型。
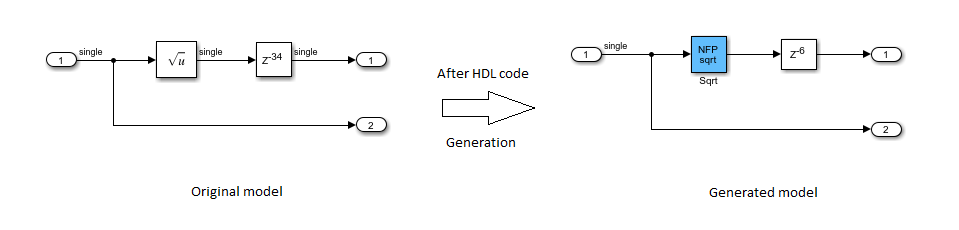
的NFP√6块吸收了28个延迟,因为平方根操作的延迟为28.的额外延迟6在运算符之外。
另请参阅
建模指南
功能
相关的例子
更多关于
您也可以从以下列表中选择一个网站: