用于状态监测和预测性维护的数据集成
数据分析是任何状态监视和预测性维护活动的核心。预测性维护工具箱™提供的工具称为集成数据存储用于创建、标记和管理预测性维护算法设计所需的大型复杂数据集。
数据可以来自使用传感器(如加速计、压力表、温度计、高度表、电压表和转速表)的系统测量。例如,您可以从以下位置访问测量数据:
系统正常运行
系统处于故障状态
系统运行的生命周期记录(run-to-failure数据)
对于算法设计,还可以使用通过运行Simulink生成的模拟数据金宝app®在各种操作和故障条件下对系统进行建模。
无论是使用测量数据、生成数据,还是两者都使用,您经常会有许多信号,范围跨越一个或多个时间跨度。您可能还会收到来自许多机器的信号(例如,100个不同的发动机的测量,它们都是按照相同的规格制造的)。您可能拥有表示正常操作和故障条件的数据。在任何情况下,设计用于预测性维护的算法都需要组织和分析大量数据,同时跟踪数据所代表的系统和条件。
集成数据存储可以帮助您处理这些数据,无论它是存储在本地还是远程位置,例如使用Amazon S3™(简单存储服务)的云存储,Windows Azure®Blob Storage和Hadoop®分布式文件系统(HDFS)™).
数据集成
预测性维护工具箱中组织和管理多方面数据集的主要单元是数据集成。一个合奏是通过测量或模拟不同条件下的系统而创建的数据集的集合。
例如,考虑一个变速箱系统,其中有一个测量振动的加速度计和一个转速计来测量发动机轴的旋转。假设您运行发动机五分钟,并记录测量的信号作为时间的函数。您还可以记录发动机使用年限,以行驶英里为单位。这些测量产生以下数据集。

现在假设您有一个由许多相同的引擎组成的车队,并记录所有引擎的数据。这样做会产生一系列数据集。
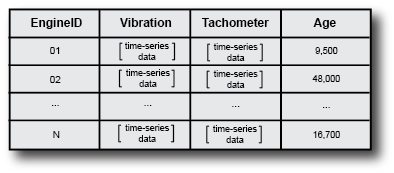
这个数据集家族是合奏,集合中的每一行都是成员乐队的成员。
集合中的成员相互关联,因为它们包含相同的数据变量。例如,在图示的集合中,所有成员都包含相同的四个变量:发动机标识符、振动和转速表信号以及发动机寿命。在该示例中,每个成员对应于不同的机器。您的集合还可能包括在不同时间从同一台机器记录的一组数据变量。例如,下图显示了一个集成,该集成包括来自同一发动机的多个数据集,这些数据集是在发动机老化时记录的。

实际上,每个集成成员的数据通常存储在一个单独的数据文件中。因此,例如,您可能有一个文件包含引擎01在9500英里处的数据,另一个文件包含引擎01在21250英里处的数据,以此类推。
模拟集合数据
在许多情况下,您没有来自系统的实际故障数据,或者只有在故障情况下来自系统的有限数据。如果您有一个模拟实际系统行为金宝app的Simulink模型,您可以通过在各种条件下重复模拟模型并记录模拟数据来生成数据集成。例如,你可以:
改变反映是否存在故障的参数值。例如,使用非常低的电阻值来模拟短路。
注入信号故障。测量信号中的传感器漂移和干扰会影响测量数据值。您可以通过向模型添加适当的信号来模拟这种变化。例如,您可以向传感器添加偏移以表示漂移,或者通过在模型中的某个位置注入信号来建模干扰。
系统动力学变化。控制组件行为的方程可能因正常和错误的操作而改变。在这种情况下,可以将不同的动态实现为相同组件的变体。
例如,假设您有一个描述齿轮箱系统的Simulink模型。该模型包含一个表示金宝app振动传感器漂移的参数。您可以在不同的传感器漂移值下模拟此模型,并将模型配置为记录每次模拟的振动和转速表信号。这些模拟生成一个覆盖一系列操作条件的集合。每个集合成员对应一个模拟,并在一组特定条件下记录相同的数据变量。
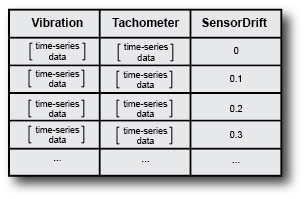
的generateSimulationEnsemble命令可以帮助您从一个模型生成此类数据集,在该模型中,您可以通过改变模型的某些方面来模拟故障条件。
系综变量
集合中的变量有不同的用途,因此可以分为几种类型:
数据变量-集成成员的主要内容,包括用于分析和开发预测性维护算法的测量数据和衍生数据。例如,在图示的齿轮箱组合中,
振动和转速表为数据变量。数据变量还可以包括导出的值,如信号的平均值,或信号频谱中峰值幅度的频率。自变量—标识或排序集合中成员的变量,如时间戳、操作小时数或机器标识符。在测量的齿轮箱数据中,
年龄为自变量。条件变量—用于描述集成电路成员故障或运行状态的变量。条件变量可以记录故障状态的存在或不存在,或其他运行条件,如环境温度。在模拟变速箱数据中,
SensorDrift是条件变量。条件变量也可以是派生值,例如编码多个故障和操作条件的单个标量值。
实际上,数据变量、自变量和条件变量都是不同的变量集。
整体的数据预测性维护工具箱
使用预测性维护工具箱,您可以管理集成数据并与之交互整体数据存储对象。在MATLAB中®,时间序列数据通常存储为向量或时间表. 其他数据可能存储为标量值(如引擎寿命)、逻辑值(如故障是否存在)、字符串(如标识符)或表。您的集合可以包含对您的应用程序记录有用的任何数据类型。在集成中,通常将每个成员的数据存储在单独的文件中。集成数据存储对象可帮助您组织、标记和处理集成数据。使用哪个集成数据存储对象取决于您是使用磁盘上的测量数据,还是从Simulink模型生成模拟数据。金宝app
simulationEnsembleDatastore使用。objects管理由Simulink模型生成的数据金宝appgenerateSimulationEnsemble.fileEnsembleDatastoreobjects—管理存储在磁盘上的任何其他集成数据,如测量数据。
集成数据存储对象包含有关存储在磁盘上的数据的信息,并允许您与数据交互。您可以使用以下命令执行此操作:阅读,将数据从集成中提取到MATLAB工作空间中writeToLastMemberRead,它将数据写入集合。
最后一位议员宣读
当您使用集成时,软件会跟踪它最近读取的集成成员。当您调用阅读,软件将选择下一个要读取的成员并更新LastMemberRead属性来反映该成员。下次调用时writeToLastMemberRead,软件会给该成员写信。
例如,考虑模拟齿轮箱数据的集合。当您使用generateSimulationEnsemble,每次模拟运行的数据将被记录到磁盘上的单独文件中。然后创建一个simulationEnsembleDatastore对象,该对象指向这些文件中的数据。可以设置集合对象的属性,以将变量分成组,例如自变量或条件变量。
假设您现在从集合对象中读取一些数据,合奏.
data =阅读(套装);
你第一次打电话的时候阅读在一个集合上,软件指定集合中的某个成员作为第一个要读取的成员。该软件从该成员读取选定的变量到MATLAB工作空间,到表格被称为数据(所选变量是您在中指定的变量选定变量性质合奏.)软件更新属性合奏。LastMemberRead使用该成员的文件名。

直到你打电话阅读再一次,最后一位议员宣读名称保留在软件分配给它的集合成员中。因此,例如,假设您处理数据为了计算一些导出的变量,如振动信号频谱中峰值的频率,VibPeak.您可以将派生值附加到它所对应的集成成员,该集成成员仍然是最后读取的成员。为此,首先展开中的数据变量列表合奏以包含新变量。
合奏。DataVariables = [ensemble.DataVariables;“VibPeak”]
这个操作相当于向集合中添加一个新列,如下图所示。在每个集合中,新变量最初由缺失的值填充。(见丢失的有关更多信息。)

现在,使用writeToLastMemberRead为最后一次成员读取填充新变量的值。
newdata =表(VibPeak,“VariableNames”,{“毒蛇”}); WriteLastMemberRead(集成,新数据);
在集合中,出现了新值,并且最后一个成员读指定仍然在相同的成员上。
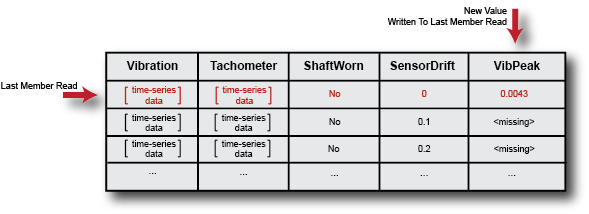
下次你再打电话来阅读在集合上,它确定要读取的下一个成员,并从该成员返回选定的变量。“最后读取”的成员将被指定为该成员。

的hasdata命令告诉您是否已读取集合的所有成员重置命令清除所有成员的“读”指定,以便下一次调用阅读对集合的第一个成员进行操作。重置操作将清除LastMemberRead属性,但它不会更改其他集合属性,例如数据变量或选定变量.它也不会更改您已写回集成的任何数据。有关显示与生成数据集成的更多交互的示例,请参见生成和使用模拟数据集成.
读取测量数据
尽管前面的讨论使用了模拟集合作为示例,但最后一个成员读取指定在您管理的测量数据集合中的行为方式相同fileEnsembleDatastore.然而,当你使用测量数据时,你必须提供信息来告诉阅读和writeToLastMemberRead命令您的数据如何存储和组织在磁盘上。
您可以通过设置fileEnsembleDatastore对象来创建您编写的函数。设定ReadFcn属性设置为函数的句柄,该函数描述如何从数据文件读取数据变量。当你打电话阅读,它使用此函数访问下一个集成文件,并从中读取选定变量集合数据存储的属性。同样,您使用WriteToMemberFcn财产fileEnsembleDatastore对象提供描述如何将数据写入集合成员的函数。
有关显示这些与磁盘上测量数据集合交互的示例,请参阅:
合奏和MATLAB数据存储
预测性维护工具箱中的集合是一种专门的MATLAB数据存储(参见数据存储入门).的阅读和writeToLastMemberRead命令具有特定于集成数据存储的行为。此外,以下MATLAB数据存储命令与集成数据存储的工作方式与其他MATLAB数据存储的工作方式相同。
hasdata—判断集群数据存储中是否存在未读成员。重置—将集成数据存储恢复到没有成员被读取的状态。在此状态下,没有当前成员。使用此命令重新读取已从集合中读取的数据。高的—将集成数据存储转换为高表。(见用于内存不足数据的高数组).进步-确定已读取集成数据存储的百分比。分区-将集成数据存储划分为多个集成数据存储以进行并行计算。(对于集成数据存储,请使用分区(ds、n、索引)语法。)numpartitions—确定数据存储分区个数。
阅读多个合奏成员
默认情况下阅读命令每次从一个集成成员返回数据。若要一次处理来自多个集成成员的数据,请设置可读大小集合数据存储对象的值大于1。例如,如果你设置可读大小到3,然后每个调用到阅读返回一个包含三行的表,并指定三个集合成员作为最后读取的成员。有关详细信息,请参阅fileEnsembleDatastore和simulationEnsembleDatastore参考页面。
将集合数据转换为高表
有些函数(例如许多统计分析函数)可以操作高表中的数据,这使您能够处理由数据存储支持的内存不足的数据。属性将数据从集成数据存储转换为一个高表,以便与此类分析命令一起使用高的命令。
处理大型集合数据(例如长时间序列信号)时,通常使用阅读和writeToLastMemberRead.处理数据以计算数据的某些特性,这些特性可以作为集成成员的有用条件指示符。
通常情况下,条件指示器是一个标量值或占用内存空间小于原始未处理信号的其他值。因此,一旦将这些值写入数据存储,就可以使用高的和聚集将条件指标提取到记忆中进行进一步的统计处理,如训练分类器。
例如,假设集合中的每个成员都包含时间序列振动数据。对于每个成员,读取集合数据并计算一个条件指示符,该指示符是从信号分析过程导出的标量值。将派生值写回成员。假设派生值位于名为指示器包含集成成员信息(例如故障条件)的标签位于一个名为标签.为了对整体进行进一步的分析,可以将状态指示器和标签读入内存,而不需要读入较大的振动数据。为此,设置选定变量要读取的变量集合的属性。然后使用高的创建一个包含所选变量的高表聚集将值读入内存。
合奏。选择edVariables = [“指标”,“标签”]; 特征表=高(整体);featureTable=聚集(featureTable);
结果变量featureTable是驻留在MATLAB工作区中的普通表。您可以使用支持MATLAB表格数据类型的任何函数来处理它。金宝app
举例说明使用高的和聚集要对集成数据进行预测维护分析,请参见:
处理总体数据
将数据组织成一个集合后,预测性维护算法设计的下一步是对数据进行预处理以清理或转换。然后进一步处理数据以提取条件指标,这些指标是可用于区分正常运行和故障运行的数据特征。有关更多信息,请参阅:
另见
fileEnsembleDatastore|simulationEnsembleDatastore|阅读|generateSimulationEnsemble
相关话题
您还可以从以下列表中选择网站:
