上覆盖数据操作
这个例子说明了如何使用重载运算符+,*,以及 - 覆盖结果结合成集,交集或组结果的差异。
示例模型
打开一个简单的模型有两个相互排斥的启动子系统。
open_system (“slvnvdemo_cv_mutual_exclusion”)
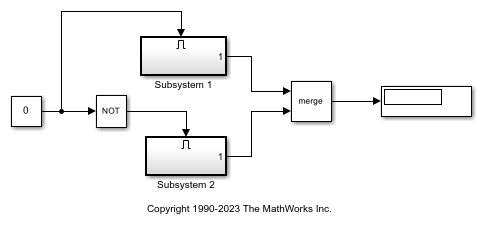
使用的命令cvtest和cvsim开始仿真。最初,常量块的值为0,这迫使子系统2执行。
TEST1 = cvtest(“slvnvdemo_cv_mutual_exclusion”);DATA1 = cvsim(TEST1)
data1 =…checksum: [1x1 struct] modelinfo: [1x1 struct] startTime: 28-Feb-2020 23:30:48 stopTime: 28-Feb-2020 23:30:49 intervalStartTime: 0 intervalStopTime: 0 simulationStartTime: 0 simulationStopTime: 10 metrics: [1x1 struct] filter: simMode: Normal
下面的命令运行所述第二模拟之前改变恒定块的1的值。这迫使子系统1执行。
set_param (“slvnvdemo_cv_mutual_exclusion /常数”,'值','1');TEST2 = cvtest(“slvnvdemo_cv_mutual_exclusion”);DATA2 = cvsim(TEST2)
DATA2 = ... cvdata ID:704类型:TEST_DATA测试:cvtest对象rootID:651校验和:[1x1的结构] modelinfo:[1x1的结构]开始时间:28-FEB-2020 23时30分49秒停止时间:28-FEB-202023点30分四十九秒intervalStartTime:0 intervalStopTime:0 simulationStartTime:0 simulationStopTime:10项指标:[1x1的结构]过滤器:simMode:正常
我们使用decisioninfo命令从每个测试中提取的决定覆盖率和将其列为一个百分比。
注:虽然这两个测试有50%的判定覆盖,无论它们是否覆盖相同的50%是未知的。
cov1 = decisioninfo (data1、“slvnvdemo_cv_mutual_exclusion”);percent1 = 100 *(COV1(1)/ COV1(2))= COV2 decisioninfo(DATA2,“slvnvdemo_cv_mutual_exclusion”);percent2 = 100 *(COV2(1)/ COV2(2))
percent1 = 50 percent2 = 50
查找范围的联盟
使用+操作符派生第三个cvdata对象,该对象表示data1和data2 cvdata对象的联合。
注意:组合其他模拟结果创建的cvdata新对象被标记为type属性设置为DERIVED_DATA。
dataUnion = DATA1 + DATA2
dataUnion = ... cvdata ID:0类型:DERIVED_DATA试验:[] rootID:651校验和:[1x1的结构] modelinfo:[1x1的结构]开始时间:28-FEB-2020二十三时30分48秒停止时间:28-FEB-2020二十三时30分49秒intervalStartTime:0 intervalStopTime:0指标:[1x1的结构]过滤器:simMode:正常
请注意,覆盖的工会是100%,因为有两个集合之间的覆盖范围没有重叠。
covU = decisioninfo (dataUnion,“slvnvdemo_cv_mutual_exclusion”);percentU = 100 *(covU(1)/ covU(2))
percentU = 100
查找范围的交集
通过使用*操作符交叉data1和data2,确认两个测试之间的覆盖没有重叠。正如预期的那样,在交集中有0%的决策覆盖率。
dataIntersection = DATA1 * DATA2 COVI = decisioninfo(dataIntersection,“slvnvdemo_cv_mutual_exclusion”);percentI = 100 * (covI (1) / covI (2))
dataIntersection = ... cvdata ID:0类型:DERIVED_DATA试验:[] rootID:651校验和:[1x1的结构] modelinfo:[1x1的结构]开始时间:28-FEB-2020 23时30分48秒停止时间:28-FEB-202023点三十○分49秒intervalStartTime:0 intervalStopTime:0指标:[1x1的结构]过滤器:simMode:正常percentI = 0
使用派生覆盖数据对象
衍生cvdata对象可以在所有的报告和分析的命令被使用,并且作为输入提供给后续操作。作为一个例子,产生从派生dataIntersection对象的覆盖报告。
cvhtml(“intersect_cov”,dataIntersection);%输入到另一个操作newUnion = dataUnion + dataIntersection
newUnion =…cvdata id: 0 type: DERIVED_DATA test: [] rootID: 651 checksum: [1x1 struct] modelinfo: [1x1 struct] startTime: 28-Feb-2020 23:30:48 stopTime: 28-Feb-2020 23:30:49 intervalStartTime: 0 intervalStopTime: 0 metrics: [1x1 struct] filter: simMode: Normal

计算覆盖率(设置)差异
- 运算符被用来形成代表左和右操作数之间的差集一个cvdata对象。该操作的结果包含了满足了左操作数,但在正确的操作不满意的覆盖点。此操作是确定多少额外的覆盖范围是如何归因于特定的测试非常有用。
在下面的例子中,第一和第二测试覆盖的工会和第一测试覆盖率之间的差异应说明第二测试多少额外提供保障。正如已经显示的,因为没有重叠的判定覆盖点,从测试2的新的决策覆盖率为50%。
newCov2 = dataUnion - data1 covN = decisioninfo(“slvnvdemo_cv_mutual_exclusion”);percentN = 100 *(covN(1)/ covN(2))
newCov2 =…cvdata id: 0 type: DERIVED_DATA test: [] rootID: 651 checksum: [1x1 struct] modelinfo: [1x1 struct] startTime: 28-Feb-2020 23:30:48 stopTime: 28-Feb-2020 23:30:49 intervalStartTime: 0 intervalStopTime: 0 metrics: [1x1 struct] filter: simMode: Normal percentN = 50
您也可以从以下列表中选择一个网站: