使用回归学习器应用程序训练回归树
此示例演示如何使用回归学习器应用程序创建和比较各种回归树,并将经过训练的模型导出到工作区以对新数据进行预测。
您可以训练回归树以预测对给定输入数据的响应。若要预测回归树的响应,请从根开始跟踪该树(开始)节点向下移动到叶节点。在每个节点上,使用与该节点关联的规则确定要遵循的分支。继续,直到到达叶节点。预测的响应是与该叶节点关联的值。
统计和机器学习工具箱™ 树是二进制的。预测中的每个步骤都涉及检查一个预测变量的值。例如,下面是一个简单的回归树:

这棵树根据两个预测器来预测反应,x1和x2.要预测,从最上面的节点开始。在每个节点上,检查预测器的值,以决定遵循哪个分支。当分支到达叶节点时,响应被设置为对应于该节点的值。
本示例使用carbig数据集。该数据集包含了从1970年到1982年生产的不同车型的特征,包括:
加速
气缸数
发动机排量
发动机功率(马力)
模型一年
重量
原产国
每加仑英里数(MPG)
将其他变量作为输入,训练回归树以预测汽车模型的燃油经济性(以英里/加仑为单位)。
在MATLAB®,加载
carbig数据集并创建一个包含不同变量的表:负载carbig可移动=工作台(加速度、气缸、排量、,...马力,Model_Year、重量、起源、MPG);
在应用程序选项卡,在机器学习与深度学习组中,单击回归学习者.
在回归学习者选项卡,在文件部分中,选择新会话>从工作区.
下数据集变量在“从工作区新建会话”对话框中,选择
cartable从工作区中的表和矩阵列表中获取。观察应用程序有预先选择的响应和预测变量。
英里/加仑作为响应,而所有其他变量作为预测器。对于本例,不要更改选择。
要接受默认验证方案并继续,请单击开始会话.默认的验证选项是交叉验证,以防止过拟合。
回归学习器创建响应图,记录号在x设在。
使用响应图来研究哪些变量对预测响应有用。为了可视化不同预测因素和反应之间的关系,选择中不同的变量X列表下轴.
观察哪些变量与响应最明显相关。
位移,马力,及重量所有这些都对反应有清晰可见的影响,并且都与反应呈负相关。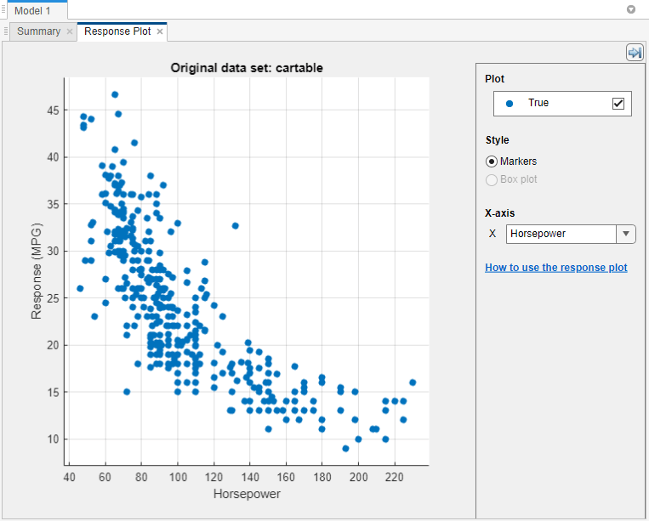
选择变量
起源下轴. 将自动显示方框图。方框图显示了响应的典型值和任何可能的异常值。当打印标记导致多个点重叠时,长方体打印非常有用。当变量位于x-axis很少有唯一的值,在风格中,选择箱线图.
创建一个回归树的选择。在回归学习者选项卡,在模型类型部分中,点击所有树木
 .
.然后单击火车
 .
.提示
如果你有并行计算工具箱™, 你可以训练所有的模特(所有树木)同时选择使用并行按钮培训节之前点击火车.你点击后火车,打开并行池对话框将打开并保持打开状态,而应用程序将打开一个并行工作人员池。在此期间,您无法与软件交互。池打开后,应用程序将同时训练模型。
回归学习者创建并训练三棵回归树好树,一个中树和一个粗树.
这三个模型出现在模型窗格。检查RMSE(验证)(验证均方根误差)。最好的分数在方框中高亮显示。
的好树和中树有类似的rmse,而粗树不太准确的。
回归学习者绘制第一个模型(模型1.1)的真实训练反应和预测反应。

请注意
如果您正在使用验证,则结果包含一些随机性。因此,您的模型验证得分可能与显示的结果不同。
选择一个模型模型窗格以查看该模型的结果。例如,选择中树模型(1.2)。在回归学习者选项卡,在情节段,单击箭头以打开图库,然后单击回应在验证结果组。下轴中,选择
马力并检查响应图。真实的和预测的反应现在都画出来了。显示预测误差,在预测和真实响应之间画成竖线,通过选择错误复选框。查看当前选择模型的详细信息当前模型的总结窗格。检查并比较其他模型特征,如R平方(确定系数)、MAE(平均绝对误差)和预测速度。要了解更多信息,请参阅查看和比较模型统计.在当前模型的总结窗格中,还可以找到有关当前选定模型类型的详细信息,例如用于训练模型的选项。
绘制预测反应和真实反应的曲线。在回归学习者选项卡,在情节段,单击箭头以打开图库,然后单击预测与实际(验证)在验证结果组。使用这个图来理解回归模型对不同响应值的预测有多好。

一个完美的回归模型预测的响应等于真实响应,所以所有的点都位于一条对角线上。从直线到任意点的垂直距离是该点的预测误差。一个好的模型误差很小,所以预测结果分散在直线附近。通常,一个好的模型具有围绕对角线大致对称分布的点。如果您可以在绘图中看到任何清晰的模式,则很可能可以改进您的模型。
中选择其他模型模型窗格,打开每个模型的预测与实际图,然后比较结果。重新安排情节的布局,以便更好地比较情节。单击Document Actions箭头
 位于模型绘图选项卡的最右侧。选择
位于模型绘图选项卡的最右侧。选择瓷砖都选项并指定一个1乘3的布局。单击隐藏情节选项按钮 在图的右上角给图留出更多的空间。
在图的右上角给图留出更多的空间。
要返回原始布局,您可以单击布局按钮情节部分并选择单一模式(默认).
在模型类型画廊,选择所有树木一次。为了改进模型,尝试在模型中加入不同的特性。看看是否可以通过删除预测能力低的特征来改进模型。在回归学习者选项卡,在特性部分中,点击特征选择
 .
.在“特性选择”对话框中,清除加速和气缸把他们排除在预测之外。点击好 啊.
点击火车使用新的预测器设置来训练新的回归树。
在中观察新车型模型窗格。这些模型与之前的回归树相同,但只使用了7个预测器中的5个。该应用程序显示使用了多少预测器。要检查使用了哪些预测器,请单击模型窗格,并观察“功能选择”对话框中的复选框。
去掉这两个特征的模型与使用所有预测器的模型表现相当。使用所有预测器的模型预测效果并不比仅使用其中一部分预测器更好。如果数据收集非常昂贵或困难,您可能更喜欢无需一些预测器就能令人满意地执行的模型。
训练三个回归树预设只用
马力作为一个预测。在“特性选择”对话框中更改选择,然后单击好 啊.然后单击火车.仅使用发动机功率作为预测因素会导致模型精度较低。然而,这些模型的表现很好,因为它们只使用了一个预测器。有了这个简单的一维预测空间,粗树现在的表现与中等树和细树一样好。
在列表中选择最佳模型模型窗格并查看残差图。在回归学习者选项卡,在情节段,单击箭头以打开图库,然后单击残差(验证)在验证结果组。残差图显示预测和真实响应之间的差异。要将残差显示为折线图,请在风格部分中,选择行.
下轴,选择要在上面绘图的变量x-选择真实响应、预测响应、记录编号或一个预测值。

通常一个好的模型的残差大致对称地散布在0附近。如果您能在残差中看到任何清晰的模式,那么您就有可能改进您的模型。
要了解模型设置,请选择最佳模型模型窗格并查看高级设置。中不可优化的模型选项模型类型图库是预置的起点,您可以更改其他设置。在回归学习者选项卡,在模型类型部分中,点击先进的。比较中的不同回归树模型模型窗格,并在“高级回归树选项”对话框中观察差异。的最小叶片尺寸设置控制树叶的大小,并通过树叶控制回归树的大小和深度。
为了进一步改进模型,改变最小叶片尺寸设置为8并单击好 啊.然后通过点击训练一个新模型火车.
控件中的选定训练模型的设置当前模型的总结窗格或“高级回归树选项”对话框中。
要了解更多关于回归树设置的信息,请参见回归树.
您可以将所选模型的完整或紧凑版本导出到工作区。在回归学习者选项卡,在出口部分中,点击出口模式和选择出口模式或出口紧凑的模型。在“导出模型”对话框中,单击好 啊接受默认变量名的步骤
trainedModel.要查看有关结果的信息,请查看命令窗口。
使用导出的模型对新数据进行预测。例如,预测
cartable在工作区中输入数据:输出yfit = trainedModel.predictFcn (cartable)
yfit包含每个数据点的预测响应。如果你想用新数据自动训练相同的模型,或者学习如何以编程方式训练回归模型,你可以从应用程序中生成代码回归学习者选项卡,在出口部分中,点击生成函数.
该应用程序从模型生成代码,并在MATLAB编辑器中显示该文件。想要了解更多,请看生成MATLAB代码训练模型与新数据.








提示
使用与本例相同的工作流来评估和比较您可以在回归学习者中训练的其他回归模型类型。
训练所有可用的非最优回归模型预置:
在最右边模型类型部分中,单击箭头以展开回归模型列表。
点击全部
 ,然后单击火车.
,然后单击火车.

要了解其他回归模型类型,请参见在回归学习应用程序中训练回归模型.
相关话题
您还可以从以下列表中选择网站:
