匹配的追求
匹配追踪字典创建和可视化
这个例子展示了如何创建和可视化一个由Haar小波到第2级组成的字典。
[mpdict, ~, ~,多头]= wmpdictionary(100年“lstcpt”{{“哈雾”, 2}});
使用多头输出参数将小波字典按级别和函数类型划分(缩放或小波)。逐级通过翻译的尺度函数和小波的图。
为nn = 1:尺寸(mpdict, 2)如果(nn <= long {1}(1))“k”,“线宽”, 2)网格在包含(“翻译”)标题(“哈尔缩放函数-第2级”)elseif(nn >多头{1}(1)& & nn < =多头{1}(1)+多头{1}(2))的阴谋(mpdict (:, nn),“r”,“线宽”, 2)网格在包含(“翻译”)标题(“哈尔小波- 2级”)其他的情节(mpdict (:, nn),“b”,“线宽”, 2)网格在包含(“翻译”)标题(“哈尔小波- 1级”)结束暂停(0.2)结束

这个动画无限循环的所有情节生成。

一维信号的正交匹配追踪
这个示例演示了如何对包含尖点的一维输入信号执行正交匹配追踪。
加载cuspamax信号。构造由4级Daubechies最小不对称小波包、2级Daubechies极值相位小波、DCT-II基、sin基和移位Kronecker基组成的字典。
负载cuspamax;dict = {{“wpsym4”1}, {“db4”2},“dct”,“罪”,“RnIdent”};mpdict = wmpdictionary(长度(cuspamax),“lstcpt”、dict);
使用正交匹配追踪在过完备字典mpdict中获得信号的近似,迭代25次。将结果绘制成电影,每5次迭代更新一次。
[yfit, r,多项式系数,iopt战]= wmpalg (“经济”cuspamax mpdict,“typeplot”,...“电影”,“stepplot”5);

用匹配追踪法分析电力消耗
这个例子展示了如何比较匹配追踪与非线性逼近在离散傅里叶变换基。这些数据是24小时内收集的用电量数据。该示例表明,通过从字典中选择原子,匹配追踪通常能够更有效地用M个向量逼近向量,而不是任何单个基。
使用DCT,正弦和小波字典的匹配追踪
加载数据集并绘制数据。数据集包含35天的用电量。选择第32天进行进一步分析。数据是集中的和可伸缩的,所以实际的使用单位并不相关。
负载elec35_norx =信号(32岁);情节(x)包含(“分钟”) ylabel (“使用”)
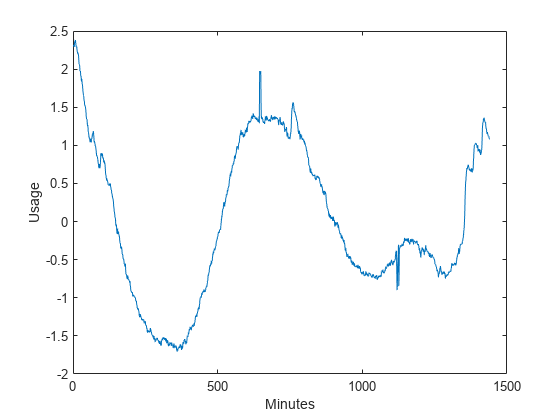
电力消耗数据包含平滑的振荡,并被使用量的突然增加和减少打断。
放大从500分钟到1200分钟的时间间隔。
xlim(1200年[500])
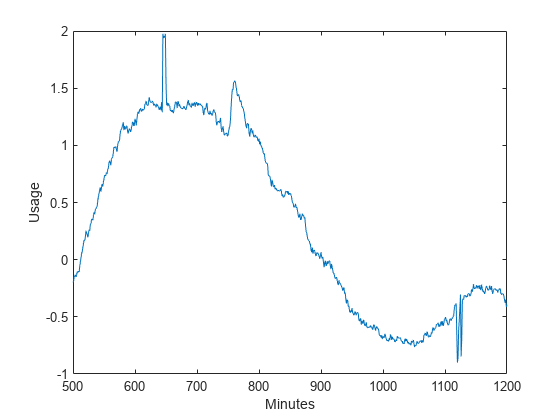
在大约650,760和1120分钟时,你可以看到缓慢变化的信号的突变。在许多真实世界的信号中,像这些数据,有趣和重要的信息包含在瞬态中。对这些瞬态现象进行建模是很重要的。
使用从具有正交匹配追踪(OMP)的字典中选择的35个向量构建一个信号近似。该字典由2级的Daubechies极值相位小波和标度向量、离散余弦变换基、正弦基、Kronecker基以及1级和4级的具有4个消失矩的Daubechies最小不对称相位小波和标度向量组成。然后,利用OMP方法求出电耗数据的最佳35项贪婪近似。策划的结果。
字典= {{“db1”2}, {“db1”3},“dct”,“罪”,“RnIdent”, {“sym4”4}};[mpdict, nbvect] = wmpdictionary(长度(x),“lstcpt”,字典);[y, ~, ~, iopt] = wmpalg (“经济”, x, mpdict);情节(x)在情节(y)从包含(“分钟”) ylabel (“使用”)传说(原始信号的,“经济”)
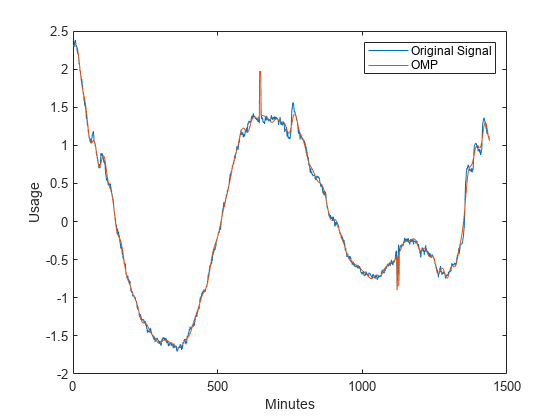
你可以看到,在35个系数下,正交匹配追踪近似于信号的平滑振荡部分和用电的突然变化。
确定OMP算法从每个子字典中选择了多少向量。
basez = cumsum (nbvect);k = 1;为nn = 1:长度(basez)如果(nn == 1) baszind {nn} = 1:basez(nn);其他的basezind {nn} = basez (nn-1) + 1: basez (nn);结束结束dictvectors = cellfun (@ (x)相交(iopt x), basezind,...“UniformOutput”、假);
大多数(60%)的向量来自DCT和sin基。考虑到电力消耗数据的整体缓慢变化性质,这是预期的行为。小波子字典中额外的14个向量捕获了信号突变变化。每种类型的向量个数为:
3 Daubechies小波(db4) 2级向量
16离散余弦变换向量
5正弦向量
2 Daubechies最小不对称小波(sym4) 1级向量
9 Daubechies最小不对称小波(sym4) 4级向量
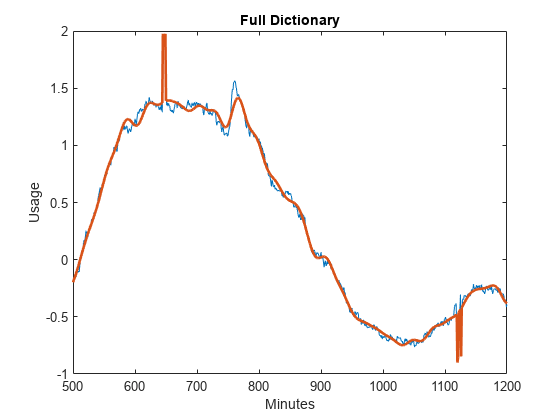
使用DCT和正弦字典匹配追踪与全字典
只对DCT和sin子字典重复OMP。设置OMP以从dct -sin字典中选择35个最佳向量。构造字典并执行OMP。将带有dct -sin字典的OMP与带有附加小波子字典的OMP进行比较。注意,添加小波子字典可以更准确地显示用电量的突然变化。包括小波基的好处是特别明显的,特别是在大约650分钟和1120分钟的使用中,向上和向下的尖峰。
dictionary2 = {“dct”,“罪”};[mpdict2, nbvect2] = wmpdictionary(长度(x),“lstcpt”, dictionary2);y2 = wmpalg (“经济”, x, mpdict2“itermax”35);情节(x)在情节(y2,“线宽”, 2)从标题(DCT和正弦字典)包含(“分钟”) ylabel (“使用”) xlim(1200年[500])
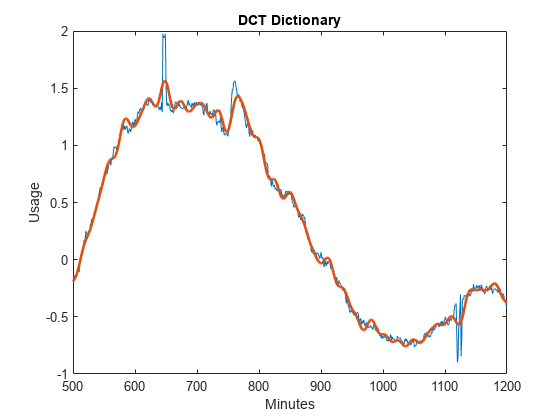
图绘制(x)在情节(y,“线宽”, 2)从标题(“完整的字典”)包含(“分钟”) ylabel (“使用”) xlim(1200年[500])
在离散傅里叶基中获得信号的最佳35项非线性近似。得到数据的DFT,对DFT系数进行排序,选择最大的35个系数。实值信号的DFT是共轭对称的,所以只考虑从0 (DC)到Nyquist(1/2周期/分钟)的频率。
xdft = fft (x);[~,我]=排序(xdft(1:长度(x) / 2 + 1),“下”);印第安纳州=我(1时35)抵达;
检查向量印第安纳州.没有一个索引对应于0或Nyquist。在DFT基上加上相应的复共轭得到非线性近似。画出近似和原始信号。
indconj =长度(xdft)印第安纳+ 2;indconj = [indconj];xdftapp = 0(大小(xdft));xdftapp(印第安纳州)= xdft(印第安纳州);xrec =传输线(xdftapp);情节(x)在情节(xrec“线宽”, 2)从包含(“分钟”) ylabel (“使用”)传说(原始信号的,“非线性DFT近似”)
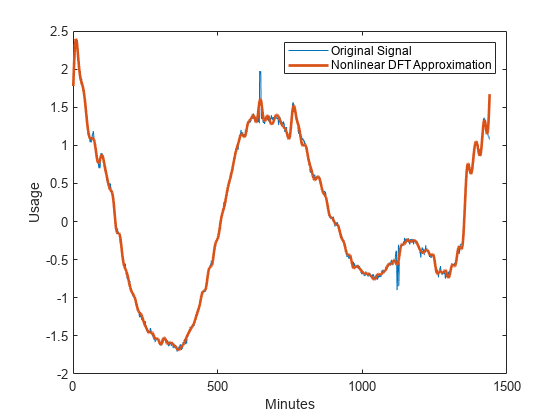
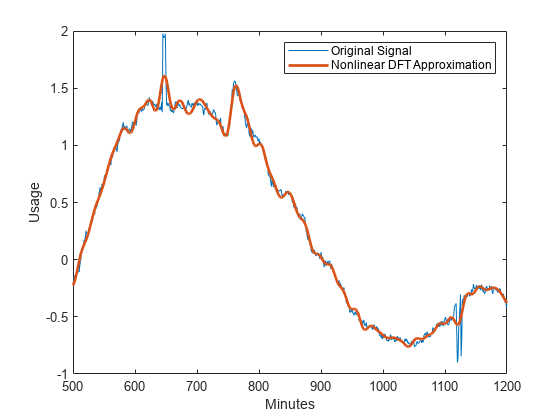
与dct -sin字典相似,非线性DFT逼近在匹配电耗数据的平滑振荡方面表现良好。然而,非线性DFT逼近方法并不能准确地逼近突变点。放大包含消费突变的数据的间隔。
情节(x)在情节(xrec“线宽”, 2)从包含(“分钟”) ylabel (“使用”)传说(原始信号的,“非线性DFT近似”) xlim(1200年[500])
你也可以从以下列表中选择一个网站: