深度学习工具箱
设计,列车和分析深度学习网络
深度学习工具箱™为设计和实现具有算法,预磨料模型和应用的深度神经网络提供框架。您可以使用卷积神经网络(CoundNet,CNN)和长短期内存(LSTM)网络在图像,时序和文本数据上执行分类和回归。您可以使用自动分化,自定义训练循环和共享权重构建网络架构,例如生成的对抗网络(GANS)和暹罗网络。使用深度网络设计器应用程序,您可以以图形方式设计,分析和培训网络。实验管理器应用程序可帮助您管理多个深度学习实验,跟踪培训参数,分析结果和与不同实验的代码进行比较。您可以可视化图层激活和图形监控培训进度。
您可以通过Tennx格式和来自Tensorflow-Keras和Caffe的INNX格式和导入模型交换模型。工具箱支持使用Darkn金宝appet-53,Reset-50,NASnet,Screezenet和许多其他预磨模的转移学习。
您可以在单个或多个GPU工作站上加快培训(并行计算工具箱™),或扩展到集群和云,包括NVIDIA® GPU Cloud and Amazon EC2® GPU instances (with MATLAB Parallel Server™).
开始:

卷积神经网络
学习图像中的模式以识别对象,面部和场景。构建和列车卷积神经网络(CNNS)来执行特征提取和图像识别。

长短期内存网络
学习序列数据的长期依赖关系,包括信号、音频、文本和其他时间序列数据。构建和训练长短期记忆(LSTM)网络进行分类和回归。

使用LSTMS。
网络体系结构
使用各种网络结构,包括指导的无循环图(DAG)和经常性架构来构建您的深度学习网络。使用自定义培训循环,共享权重和自动差异构建高级网络架构,如生成的对抗网络(GANS)和暹罗网络。

使用不同的网络架构。
设计深度学习网络
使用deep network Designer应用程序从头开始创建和训练一个深度网络。导入一个预先训练的模型,可视化网络结构,编辑层,调整参数,并训练。

分析深度学习网络
分析您的网络架构以在培训之前检测和调试错误,警告和层兼容性问题。可视化网络拓扑和查看详细信息,例如学习参数和激活。

分析一个深度学习网络架构。
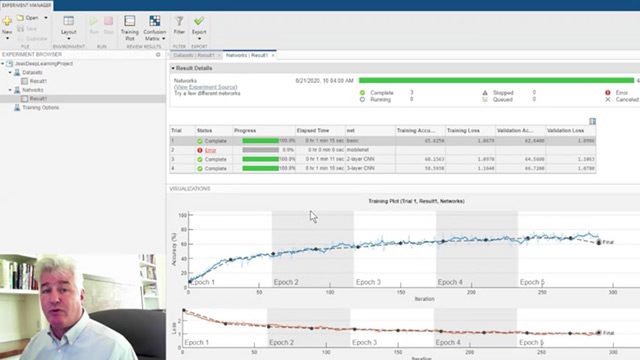
管理深度学习实验
使用实验管理器应用管理多个深度学习实验。跟踪培训参数,分析结果和与不同实验的代码进行比较。使用可视化工具,如培训图和混淆矩阵,排序和过滤实验结果,并定义定制度量来评估培训的型号。

转移学习
访问佩带的网络并使用它们作为学习新任务的起点。执行转移学习以在网络中使用网络中的学习功能进行特定任务。

Pretrained模型
使用单行代码的最新研究访问佩带的网络。导入普试模型,包括DarkNet-53,Reset-50,Screezenet,NASNet和Incepion-V3。

预磨料模型分析。

监控您的模型的培训进度。
网络激活和可视化
提取对应于图层的激活,可视化学习功能,并使用激活培训机器学习分类器。使用Grad-Cam,闭塞和石灰来解释深度学习网络的分类决策。

可视化激活。
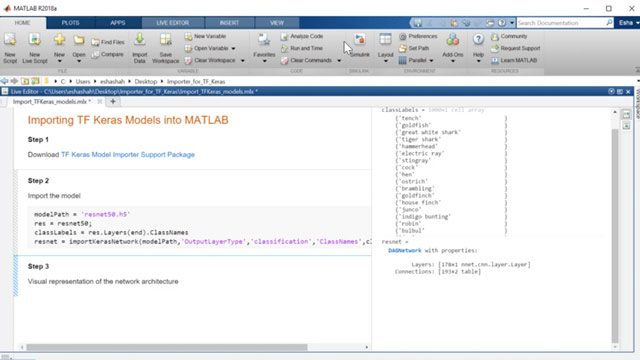
ONNX转换器
在MATLAB中导入和导出ONNX模型®对于与其他深度学习框架的互操作性。ONNX使模型能够在一个框架中接受培训并转移到另一个框架以进行推断。采用GPU编码器™生成优化的nvidia®CUDA.®代码和使用Matlab Coder™为导入模型生成C ++代码。

与深度学习框架互操作。
Caffe进口商
将Caffe Model Zoo中的模型导入MATLAB进行推理和迁移学习。

从Caffe Model动物园导入Matlab的模型。
GPU加速
高性能NVIDIA GPU加快深度学习培训和推论。对单个工作站GPU的培训或在数据中心或云上使用DGX系统进行缩放到多个GPU。你可以使用matlab并行计算工具箱和最支持的CUDA启用的NVIDIA GPU计算能力3.0或更高。

与gpu加速。
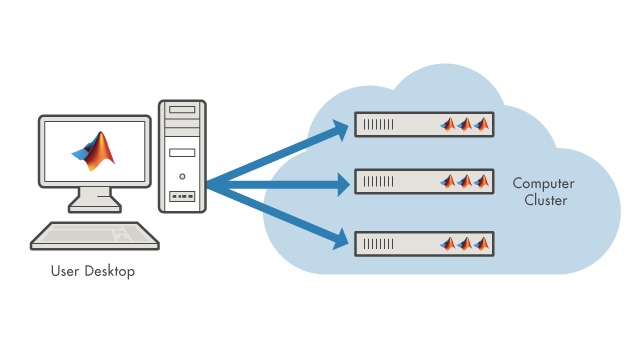
使用并行计算工具箱和MATLAB并行服务器加速云中的培训。
分布式计算
使用MATLABPrilital Server在网络上的多个服务器上跨多个处理器进行深度学习培训。

在平行和云中扩大深入学习。
模拟
模拟和生成Simulink中深度学习网络的代码金宝app®。使用alexnet,googlenet和其他佩带的模型。您还可以模拟从头开始创建的网络或通过传输学习,包括LSTM网络。使用GPU编码器和NVIDIA GPU加快Simulink中的深度学习网络的执行。金宝app使用控制,信号处理和传感器融合组件模拟深度学习网络,以评估深度学习模型对系统级性能的影响。
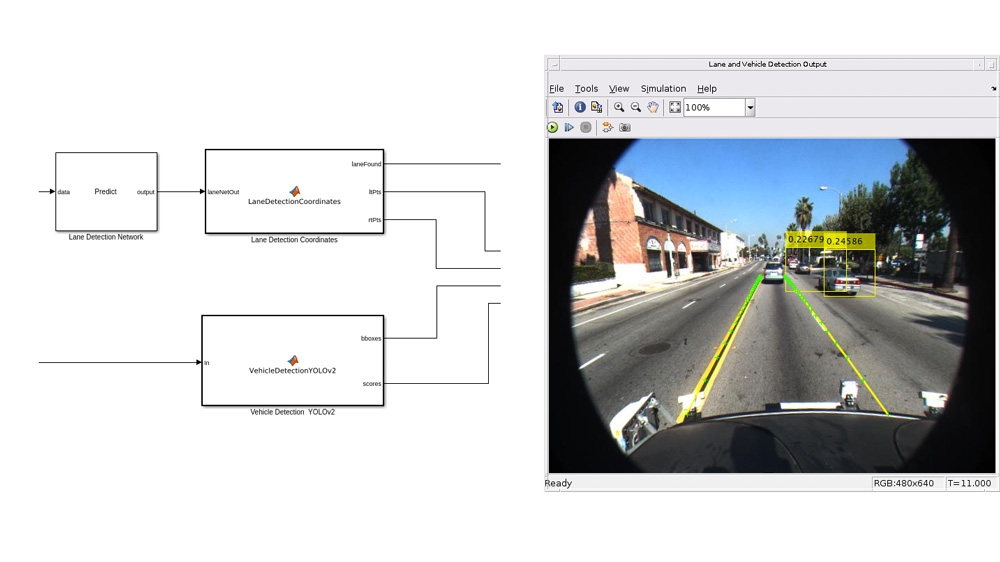
Simulink中的深度卷积神经网络金宝app®用于执行车道和车辆检测的模型
代码生成
采用GPU编码器生成优化的CUDA代码,MATLAB编码器和金宝app仿真软件编码器生成C和c++代码,将深度学习网络部署到NVIDIA gpu, Intel®Xeon.®和手臂®皮质®-a处理器。自动化交叉编译和将生成的代码部署到NVIDIA Jetson™和Drive™平台以及Raspberry PI™板上。采用深度学习HDL工具箱™原型和实施FPGA和SOC的深度学习网络
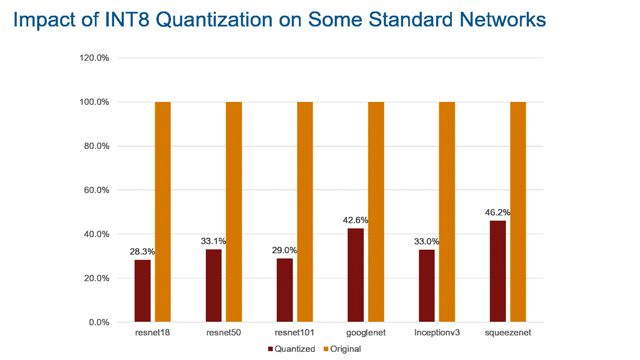
深度学习量化
量化您的深度学习网络,以减少内存使用和提高推理性能。使用Deep Network Quantizer应用程序分析和可视化提高性能和推理精度之间的权衡。
部署独立应用程序
采用Matlab Compiler™和MATLAB编译器SDK™将培训的网络部署为C ++共享库,Microsoft® .NET assemblies, Java® 类和Python® packages from MATLAB programs with deep learning models.

使用MATLAB编译器共享独立MATLAB程序。

无监督的网络
查找数据中的关系,并通过让浅网络不断调整为新输入来自动定义分类方案。使用自组织,无监督的网络以及竞争层和自组织地图。

自组织映射。
堆积的autoencoders.
通过使用自动编码器从数据集中提取低维特征,执行无监督特征转换。你也可以通过训练和堆叠多个编码器来使用堆叠自动编码器进行有监督的学习。

堆积的编码器。
