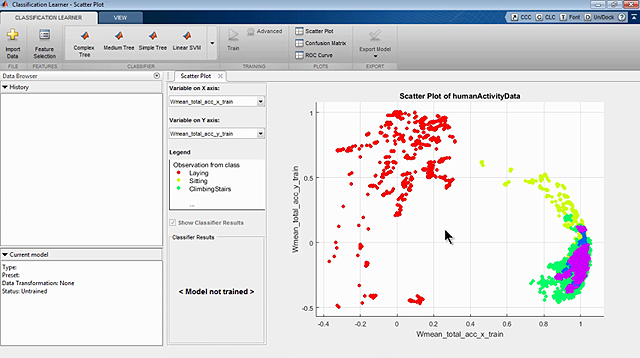
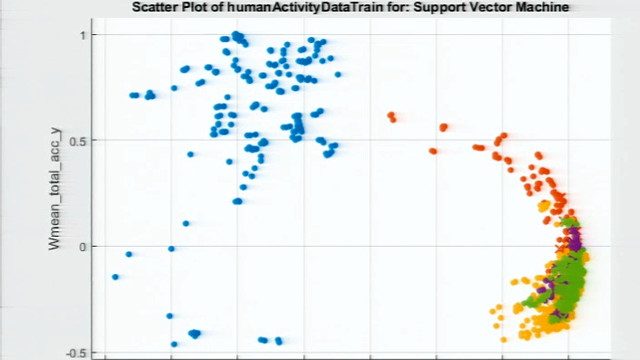
今天,我们将讨论机器学习。我们将专注于它是什么以及为什么要使用它。
机器学习教会计算机做人类自然而然会做的事:从经验中学习。
它适用于涉及大量数据和大量变量的复杂问题,但没有现成的公式或方程来描述系统。
一些适用于机器学习的常见场景包括:
- 当系统对于手写规则太复杂时,就像在面部和语音识别中一样。
- 当任务规则不断变化时,如欺诈检测。
- 并且当数据本身的性质不断变化,就像在自动交易,能源需求预测和预测购物趋势一样。
机器学习使用两种技术:
- 无监督的学习,它在输入数据中找到隐藏的模式,
- 和监督学习,它在已知的输入和输出数据上训练模型,以便它可以预测未来的输出。
无监督学习从没有与输入数据相关联的标记响应的数据集中得出推论。
聚类是最常见的无监督学习技术。它基于数据中的共享特征将数据放入不同的组中。
群集用于在许多其他诸如基因序列分析,市场研究和对象识别之类的应用中找到隐藏的分组。
另一方面,监督学习要求输入数据的每个示例都具有正确标记的输出。它使用此标记数据以及分类和回归技术来开发预测模型。
分类技术预测离散响应 - 如电子邮件是否是真实的或垃圾邮件。基本上,这些模型将输入数据分类为预定的类别集。
回归技术预测连续响应 - 如恒温器应在电力需求中设定出或波动的温度。
同样,在监督学习和无监督学习之间的大区别是监督学习需要正确标记的示例来训练机器学习模型,然后使用该模型来标记新数据。
请记住:您使用的技术和选择的算法取决于您所使用的数据的大小和类型,您想从数据中获得的见解,以及这些见解将如何使用。我们将在接下来的几集视频中更多地讨论这些技巧。
目前,这是机器学习的非常简短的概述。务必查看描述以获取更多信息。