制造工厂作业调度与资源估计
概述
此示例显示了如何建模制造工厂。该工厂包括基于预先确定的计划处理作业的装配线。此示例通过工作流程来实现:
分析作业调度对吞吐量的影响
估计工人人数
模型的结构
制造工厂迎合生产40种不同的产品变体基于预先定义的时间表。每个变体都需要两个部分,PartA和PartB,它们对应于特定的变体。每个零件都要经过一系列的制造步骤。在模型初始化过程中读取的Excel文件中指定了以下建模细节:
零件到达工厂的时间表
装配线上每个工位变体的操作时间
不同工人池中的工人数
检查区域的不合格率
下面的脚本读取excel文件并初始化所有参数。
模型中使用的变量的初始化excelFile =“seEstimatingAssemblyLineThroughput.xlsx”;时间= xlsread (excelFile,“MfgSchedule”);optim = xlsread (excelFile,“OperationTimes”);参数= xlsread (excelFile,“参数”);numMfgWorkers =参数(1);%生产区域工人人数numInspectWorkers =参数(2);检验区域的工人人数discard_rate =参数(4)/ 100;合格率%种子= 12345;%随机数种子modelname =“seEstimatingAssemblyLineThroughput”;open_system (modelname);范围= find_system (modelname,“LookUnderMasks”,“上”,“BlockType”,“范围”);cellfun (@ (x) close_system (x)范围);
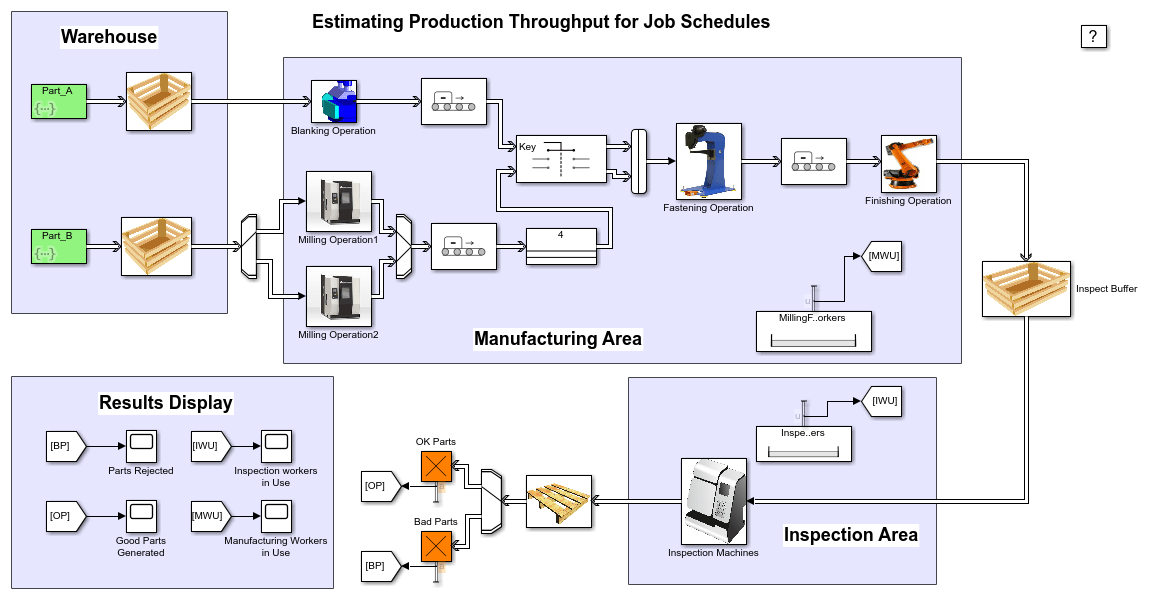
制造工厂主要由两个区域组成:
生产区域
检验区域
生产面积:工厂收到工作订单那是要实现的。一个工作订单指定变体ID和该特定变体所需的数量。实体生成器基于预定义的序列生成零件,该序列满足工作订单.在这个例子中,序列要么从MATLAB脚本生成,要么从excel表读取。下面的脚本读取工作订单要求从excel文件。
需求= xlsread (excelFile,'要求');
为了制造一个特定的变型,对应于变型的PartA和PartB被带到制造区域。零件在离开制造区域之前要经过以下步骤:
零件进行下料操作
零件经过铣削操作
然后两个部分都被紧固
装配然后通过一个精加工操作
每个变量的平均操作完成时间都列在excel表格中。假设完井时间变化4%。工人从制造工人池装载和卸载零件从铣削和紧固机器。
open_system ([modelname' /铣削Operation1 ']);
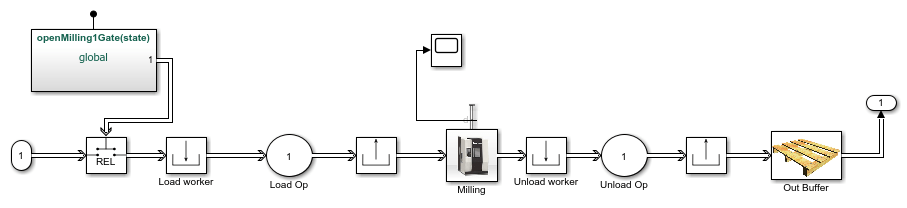
close_system ([modelname' /铣削Operation1 ']);
检查面积:成品进入检验区,在那里产品要么被证明是ok,要么被拒绝和报废。这个例子假设在检查区域有5%的不合格率。来自检查工人池的工人装卸三台检查机器上的零件。
open_system ([modelname'/检查机器']);

close_system ([modelname'/检查机器']);
作业调度对吞吐量的影响分析
以满足工作订单具有最佳吞吐量的需求,可以生成不同的调度。在这个例子中,吞吐量是工厂生产的好产品的总数。下载188bet金宝搏名为“MfgSchedule”的表显示了几个满足工作订单.以下脚本根据特定的标准生成作业调度:
计划1:下料机上最短的第一作业:
该进度表将在冲裁机上运行时间最短的工序排在第一位,最长的工序排在最后。这里的想法是将尽可能多的部件尽早地推入工厂。然后检查吞吐量:
idx = 1;S1 =悲伤(optimes(: [1]), 2);为i = 1:长度(S1)重复=要求(S1(i), 2);为j = 1:重复newSchedule(idx) = S1(i);Idx = 1;结束结束scheduleID = size(schedule, 2) + 1;schedule(:, scheduleID) = newSchedule';sim (modelname);open_system ([modelname/好的部分生成的]);

close_system ([modelname/好的部分生成的]);
计划2:铣床上最短的工作首先:
这个时间表把在铣床上运行时间最短的操作放在第一位,最长的在最后。同样,这个想法是将尽可能多的部件从工厂的其他起始分支推入工厂。然后检查吞吐量:
idx = 1;S2 =悲伤(optimes(: [1 3]), 2);为i = 1:长度(S2)重复=要求(S2(i), 2);为j = 1:重复newSchedule(idx) = S2(i);Idx = 1;结束结束scheduleID = size(schedule, 2) + 1;schedule(:, scheduleID) = newSchedule';sim (modelname);open_system ([modelname/好的部分生成的]);
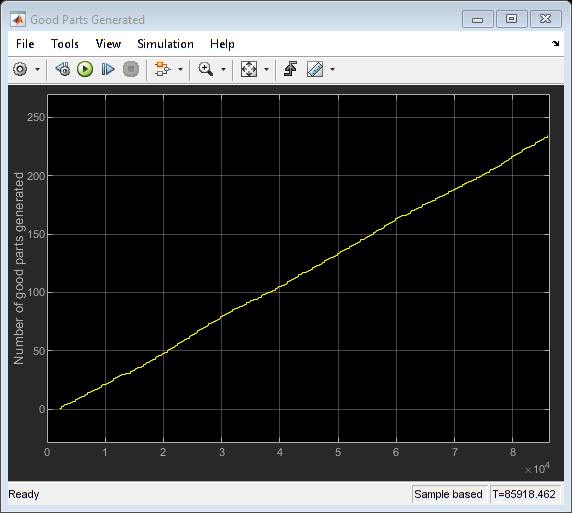
close_system ([modelname/好的部分生成的]);
附表3:紧固机器上最短的工作:
该计划将在紧固机上运行时间最短的操作放在首位,运行时间最长的操作放在最后。这里的想法是尽可能早地将零件从瓶颈机器中推出。然后检查吞吐量:
idx = 1;S4 =悲伤(optimes(: [1 5]), 2);为i = 1:长度(S4)重复=要求(S4(i), 2);为j = 1:重复newSchedule(idx) = S4(i);Idx = 1;结束结束scheduleID = size(schedule, 2) + 1;schedule(:, scheduleID) = newSchedule';sim (modelname);open_system ([modelname/好的部分生成的]);

close_system ([modelname/好的部分生成的]);% %
计划4:最短的工作优先使用累积制造时间:
此计划考虑到所有计算机上的累积运行时间。首先将具有最短累积运行时间的操作,最长的操作进入末端。然后检查吞吐量:
idx = 1;cumativesum = sortrows([optimes(:, 1)) sum(optimes(:, [2 3 5 6]), 2), 2);为i=1:长度(累积vesum)重复=要求(累积vesum (i), 2);为j = 1:重复newSchedule(idx) = cumativesum (i);Idx = 1;结束结束scheduleID = size(schedule, 2) + 1;schedule(:, scheduleID) = newSchedule';
sim (modelname);open_system ([modelname/好的部分生成的]);

close_system ([modelname/好的部分生成的]);
时间表5到8:随机时间表:
附表5到8在excel表中都是随机的时间表,满足工作订单.可以通过从任何调度开始并使用RANDPERM函数生成随机排列来生成这些调度。以下是“附表8”的结果:
scheduleID = 9;sim (modelname);open_system ([modelname/好的部分生成的]);

close_system ([modelname/好的部分生成的]);
模拟上述所有的策略,表明时间表与“紧固机器上最短的工作优先”相关,“时间表3”为我们提供了最好的吞吐量。
估计员工人数
在选择最佳时间表之后,估计两个工人池中需要的工人数量。我们一开始有三个工人在制造区工作,三个在检查区工作。
numMfgWorkers = 3;numInspectWorkers = 3;sim (modelname);open_system ([modelname'/使用中的制造业工人']);open_system ([modelname“/检查使用中的工人”]);open_system ([modelname/好的部分生成的]);
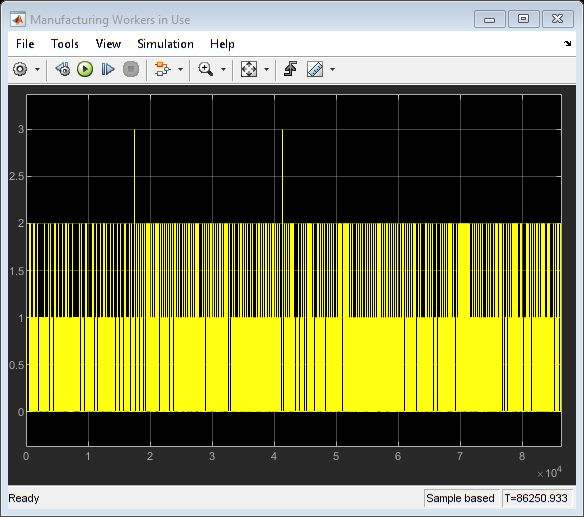


close_system ([modelname'/使用中的制造业工人']);close_system ([modelname“/检查使用中的工人”]);close_system ([modelname/好的部分生成的]);
从范围中我们可以看到,在任何给定的时间点,制造和检查池中使用的最大工人数量很少超过两个。将工人数量减少到两个表明,在提高工人利用率的情况下,对吞吐量没有影响。
numMfgWorkers = 2;numInspectWorkers = 2;sim (modelname);open_system ([modelname'/使用中的制造业工人']);open_system ([modelname“/检查使用中的工人”]);open_system ([modelname/好的部分生成的]);

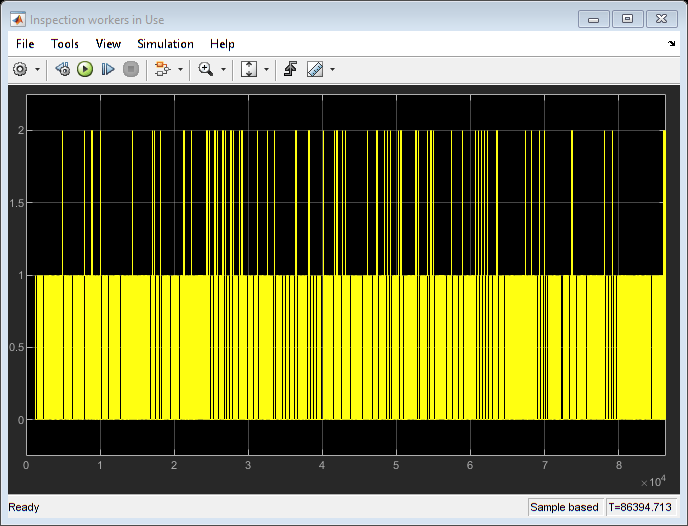
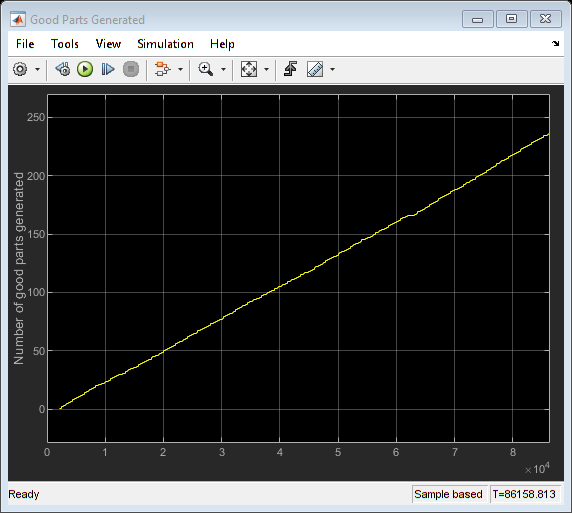
close_system ([modelname'/使用中的制造业工人']);close_system ([modelname“/检查使用中的工人”]);close_system ([modelname/好的部分生成的]);
结论
这个例子展示了我们如何使用SimEvents来建模一个作业车间。使用MATLAB脚本可以让我们进行实验,并达到最佳的时间表。
%下面的脚本关闭并清理模型bdclose (modelname);清晰的nummfgworkers.numInspectWorkersmodelnameexcelFile...scheduleIDdiscard_rate作用域时间表需求...种子optim参数;
另请参阅
实体生成器|实体服务器|队列|资源池|资源收购方|资源发布人
相关话题
您也可以从以下列表中选择一个网站: