主要内容
文本数据准备
将文本数据导入MATLAB®并对其进行预处理以进行分析
Text Analytics Toolbox™包括用于处理来自设备日志、新闻提要、调查、操作员报告和社交媒体等来源的原始文本的工具。使用这些工具从流行的文件格式中提取文本,预处理原始文本,提取单个单词或多词短语(n-gram),将文本转换为数字表示,并构建统计模型。有关如何开始的示例,请参见准备文本数据进行分析.
文本分析工具箱支持英语、日语、德语和韩语。大多金宝app数文本分析工具箱函数使用来自其他语言的文本。有关详细信息,请参阅语言的注意事项.
功能
话题
进口
这个例子展示了如何从文本、HTML、Microsoft®Word、PDF、CSV和Microsoft Excel®文件中提取文本数据,并将其导入MATLAB®进行分析。
此示例演示如何解析HTML代码并从特定元素中提取文本内容。
为各种文本分析任务发现数据集。
预处理
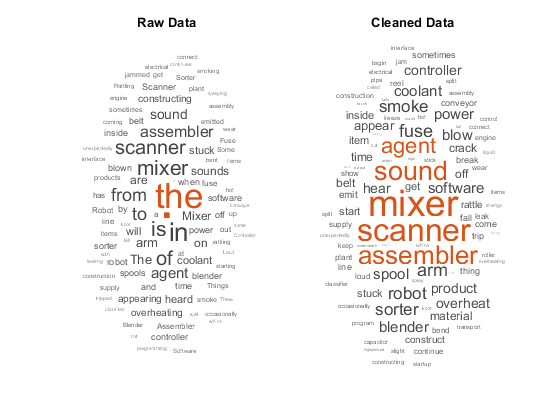
此示例演示如何创建一个函数,用于清理和预处理文本数据以进行分析。
这个例子展示了如何分析包含表情符号的文本数据。
此示例演示如何使用拼写更正文档中的拼写。
这个示例展示了如何创建一个Hunspell扩展字典来进行拼写校正。
此示例演示如何使用编辑距离搜索器和已知单词的词汇表更正拼写。
语言支持金宝app
有关为其他语言使用文本分析工具箱功能的信息。
文本分析工具箱中的日语支持信息。金宝app
这个示例展示了如何使用主题模型导入、准备和分析日语文本数据。
关于文本分析工具箱中的德语支持的信息。金宝app
这个示例展示了如何使用主题模型导入、准备和分析德语文本数据。
特色实例


你也可以从以下列表中选择一个网站:
