现在我们已经了解了强化学习工作流程,在这个视频中,我想展示如何将该工作流程用于让一个双足机器人使用配备了rl的代理行走。我们将使用来自MATLAB和Simulink Robotics Arena的行走机器人示例,您可以在GitHub上找到它们。金宝app我在描述区留下了链接。这个示例附带了一个环境模型,您可以在其中调整训练参数、训练代理并可视化结果。在这个视频中,我们还将看看如何修改这个例子,使它看起来更像我们设置一个传统的控制问题,然后展示这种设计的一些局限性。所以我希望你们能坚持下去因为我认为它会帮助你们理解如何在典型的控制应用中使用强化学习。我是Brian,欢迎来到MATLAB技术讲座。
让我们从这个问题的快速概述开始。高级别的目标是让一个两条腿的机器人像人类一样走路。作为设计师,我们的工作是确定正确移动机器人腿和身体的动作。我们可以采取的行动是每个关节的电机扭矩命令;这是左和右脚踝,左和右膝盖,还有左和右髋关节。所以有六个不同的扭矩命令,我们需要在任何给定的时间发送。
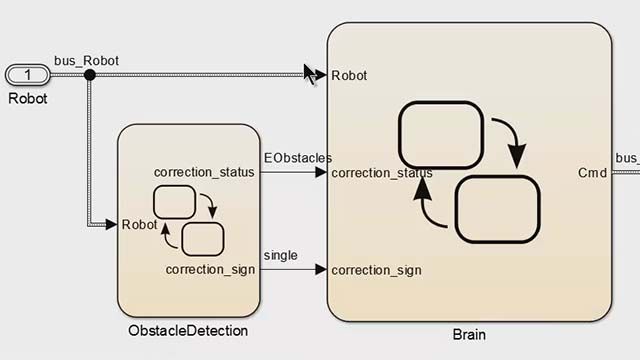
机器人的身体和腿,以及它所运行的世界,构成了环境。来自环境的观测是基于传感器的类型和位置以及软件生成的任何其他数据。在这个例子中,我们使用了31种不同的观察结果。这些是Y轴和Z轴的物体位置,X轴和Y轴的物体速度,还有物体方向和角速度。还有六个关节的角度和角度速率,以及脚与地面之间的接触力。这些是感知到的观察。我们也在反馈我们在前一个时间步骤中命令的六个动作,它们存储在软件的缓冲区中。因此,我们的控制系统总共接收了这31个观测值,并必须连续计算6个电机扭矩的值。所以你可以开始看到即使是这个非常简单的系统逻辑也有多么复杂。
正如我在之前的视频中提到的,与其尝试设计逻辑,循环,控制器,参数,以及所有使用传统控制理论工具的东西,我们可以用一个强化学习代理取代整个庞大的函数,端到端;一种是使用行动者网络将这31个观察结果映射到6个动作,另一种是使用评论家网络使训练行动者更有效。
正如我们所知,训练过程需要一个奖励函数——告诉智能体它是如何做的,这样它就可以从自己的行为中学习。我想通过思考对行走机器人来说很重要的条件来推理奖励函数中应该存在什么。如果你不知道从哪里开始,这可能就是你建立奖励函数的方法。现在,我将在创建这个函数时向您展示训练的结果,这样您就可以看到更改是如何影响解决方案的;然而,我不打算介绍如何运行模型,因为塞巴斯蒂安·卡斯特罗已经有一个很棒的视频。所以,如果你有兴趣自己尝试所有这些,我建议你看看下面描述中的链接。好了,关于奖励。
从哪里开始呢?我们显然想让机器人的身体向前移动;否则它就会站在那里。但不是距离,而是它的前进速度。这样一来,人们就会希望机器人走得更快而不是更慢。在这个奖励的训练之后,我们可以看到机器人在开始的时候向前俯冲以获得快速的速度爆发,然后摔倒,哪里都去不了。它最终可能会想出如何通过奖励来进一步前进,但它需要很长时间才能收敛,并且没有取得很大的进展,所以让我们思考一下我们可以添加什么来帮助训练。我们可以惩罚摔倒的机器人,这样向前跳水就不那么吸引人了。因此,如果它保持站立的时间更长,或者在模拟结束前经过更多的采样时间,那么智能体应该得到更多的奖励。
让我们看看它是怎么做的。在最终再次倒下之前,它在一开始有一点跳跃。也许如果我让这个特工训练更久,我就能拥有一个像青蛙一样跳跃世界的机器人,这很酷,但这不是我想要的。机器人向前移动而不跌倒是不够的;我们想要一些行走的样子,而不是跳着走或蹲着走。所以为了解决这个问题,我们还应该奖励代理让身体尽可能接近站立的高度。
让我们来看看这个奖励函数。好吧,这个看起来好多了,但是解决方案并不是很自然。它偶尔会停下来来回抖动它的腿,大多数时候它像僵尸一样拖着它的右腿把所有的动力都放在左腿上。如果我们考虑到驱动器的磨损或运行机器人所需的能量,这就不理想了。我们希望两条腿都能做同样的工作,而不是过度使用有很多抖动的执行器。因此,为了解决这个问题,我们可以奖励代理最小化执行器的工作。这样可以减少额外的紧张和平衡,使每条腿都能分担负担。
让我们看看我们训练有素的探员。好了,我们越来越接近了。这看起来很不错。但现在我们还有最后一个问题。我们想让机器人保持直线运动,而不是像现在这样向右或向左转向,所以我们应该奖励它保持在x轴附近。
这是我们的最终奖励,训练需要3500次模拟。所以如果我们在我们的模型中设置这个然后在多核或者GPU或者计算机集群上进行模拟,然后经过几个小时的训练,我们就会有一个解决方案。我们会有一个像人类一样走直线的机器人。
有了奖励函数,让我们转向策略。我已经说过,策略是一个行动者神经网络,同时也是一个评论家神经网络。每个网络都有几个隐藏层,每个层有数百个神经元,所以有很多计算要做。如果我们没有足够的神经元,那么网络将永远无法模拟高维函数,而高维函数需要将31个观察结果映射到非线性环境中的6个动作。另一方面,太多的神经元,我们花更多的时间来训练过多的逻辑。此外,网络的体系结构在功能复杂性方面非常重要。这些东西包括层数,它们是如何连接的,以及每层神经元的数量。因此,需要一些经验和知识来找到使培训成为可能和有效的最佳点。
幸运的是,正如我们所知,我们不需要手动解决网络中成千上万的权重和偏差。我们让训练算法来帮我们。在这个例子中,我们使用了一种被称为深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)的演员/评论家训练算法。原因是这个算法可以在有连续动作空间的环境中学习就像我们在电机上有连续的力矩范围。而且,由于它估计了一个确定性策略,它比学习随机策略要快得多。
我知道这一切听起来相当复杂和抽象,但对我来说,最酷的事情是,大多数复杂性都是用于训练策略的。一旦我们有了一个受过充分训练的代理,那么我们所要做的就是将参与者网络部署到目标硬件上。记住,actor是将观察映射到操作的函数;这是决定要做什么的东西,是政策。评论家和学习算法只是帮助确定参与者中的参数。
好的,在这一点上,你可能有一个问题。当然,我们可以用RL让机器人走直线;然而,这一政策难道不会只做这一件事吗?例如,如果我部署这个策略并启动我的机器人,它会立即开始直线行走,永远。那么,我如何才能学习一种策略,让我向机器人发送命令,让它走到我想让它走的地方呢?
我们想一下。现在,这就是系统的样子。我们有产生观察和奖励的环境,然后我们有产生行动的代理。我们没有办法将任何外部命令注入到这个系统中,我们的代理也没有办法对它们做出响应,即使我们有它们。因此,我们需要在代理之外编写一些额外的逻辑,用于接收参考信号并计算错误项。误差是我们从环境中得到的当前X位置与参考值之间的差值。这和我们在一个正常的反馈控制系统中会得到的误差计算是一样的。
现在,我们可以奖励它低误差,而不是奖励它在X方向上的高速度。这将激励机器人走向并停留在命令的x参考值。
对于观察结果,我们需要为代理提供一种查看误差项的方法,以便它能够相应地制定策略。因为它可能会帮助我们的代理人获得误差变化率和其他更高的导数,我将输入来自最近5个样本次数的误差。这将允许该政策在必要时创造衍生品。最终,如果错误是正的,策略将以指定的速率向前走,如果错误是负的,策略将向后走。
由于我们现在对代理有36个观察,我们需要调整参与者网络来处理额外的输入。同样,如果你需要如何做出这些改变的指导,请查看描述区塞巴斯蒂安的视频。
我用新的误差项更新了Simulink中的默认模型,并将其输入观察块和金宝app奖励块。我用这个特殊的配置文件训练了这个代理数千集,所以它应该很擅长跟踪这个。但希望训练过的策略足够强大,可以跟踪其他具有类似速率和加速度的配置文件。所以让我们试一试。我将让它向前走,暂停一会儿,然后向后走。
当它倒着走的时候看起来有点滑稽,但总的来说是一个很好的努力。通过一些奖励调整,也许再花点时间训练,我可能会在这里得到一些很好的东西。
因此,通过这种方式,您可以开始看到我们如何使用RL代理来替换控制系统的一部分。取而代之的是一个学习单一行为的函数,我们可以提取高级参考信号,并让代理消除错误,这样我们就可以保留发送命令的能力。
我们还可以从代理中删除低级功能。例如,该智能体可以只学习将脚放在地面的哪里,而不是六个关节中的每个关节的低水平扭矩。动作是将左脚放在身体坐标系中的某个位置。这个动作可以作为驱动关节电机的低级传统控制系统的参考命令。你知道,它可能会根据你对系统动力学的了解来前馈力矩指令并反馈一些信号来保证性能和稳定性。
这是有益的,因为我们可以使用我们特定的领域知识来解决简单的问题,这将使我们对设计有洞察力和控制,然后我们可以为困难的问题保留强化学习。
到目前为止,关于我们最终的行走解需要注意的是它只对自己的状态具有鲁棒性。你知道,它可以四处走动而不摔倒,这很好,但只有在完全平坦的平原上。它没有考虑到机器人外部世界的任何部分,所以它实际上是一个相当脆弱的设计。例如,让我们看看如果我们在机器人的道路上放置一个障碍会发生什么。
嗯,一切都和预期的一样。这里的问题是,除了机器人本身的运动之外,我们没有给我们的代理任何识别环境状态的方法。没有任何东西可以感知障碍,因此也没有任何办法来避免它们。
但问题是。基于神经网络的代理的美妙之处在于,它们可以处理我们所说的丰富传感器。比如激光雷达和可视相机,这些东西不会产生像角度这样的单一测量,而是返回代表数千个距离或不同光强度像素的数字数组。因此,我们可以在机器人上安装一个可视摄像头和一个激光雷达传感器,并将1000个左右的新值作为额外的观察输入到我们的代理中。你可以想象,当我们的观测值从36增加到数千时,这个函数的复杂性需要如何增长。
我们可能会发现一个简单的、完全连接的网络并不理想,因此我们可能会添加额外的层,这些层包含了专门的逻辑,可以像卷积网络一样最小化连接,或者像循环网络一样增加内存。这些网络层更适合处理大型图像数据和更动态的环境。然而,我们可能不需要为了让机器人避开这些障碍而改变奖励函数。智能体仍然可以了解到偏离路径,因此在这里获得较低的奖励,允许机器人继续行走而不会摔倒,从而获得更多的奖励。
在这个视频中,我已经解决了强化学习的一些问题,并展示了我们如何通过结合传统控制设计和强化学习的好处来修改问题。我们将在下个视频中进一步扩展这一点,在那里我们将讨论强化学习的其他缺点,以及我们可以做些什么来缓解它们。
所以如果你不想错过本期节目和未来的Tech Talk视频,不要忘记订阅这个频道。此外,如果你想看看我的频道,控制系统讲座,我在那里介绍了更多的控制主题。感谢收看,我们下期见。