Reinforcement learning is a type of machine learning technique where a computer agent learns to perform a task through repeated trial and error interactions with a dynamic environment. This learning approach enables the agent to make a series of decisions that maximize a reward metric for the task without human intervention and without being explicitly programmed to achieve the task.
AI programs trained with reinforcement learning beat human players in board games like Go and chess, as well as video games. While reinforcement learning is by no means a new concept, recent progress in deep learning and computing power made it possible to achieve some remarkable results in the area of artificial intelligence.
Reinforcement Learning vs. Machine Learning vs. Deep Learning
Reinforcement learning is a branch of machine learning (Figure 1). Unlike unsupervised and supervised machine learning, reinforcement learning does not rely on a static dataset, but operates in a dynamic environment and learns from collected experiences. Data points, or experiences, are collected during training through trial-and-error interactions between the environment and a software agent. This aspect of reinforcement learning is important, because it alleviates the need for data collection, preprocessing, and labeling before training, otherwise necessary in supervised and unsupervised learning. Practically, this means that, given the right incentive, a reinforcement learning model can start learning a behavior on its own, without (human) supervision.
Deep learning spans all three types of machine learning; reinforcement learning and deep learning are not mutually exclusive. Complex reinforcement learning problems often rely on deep neural networks, a field known as deep reinforcement learning.
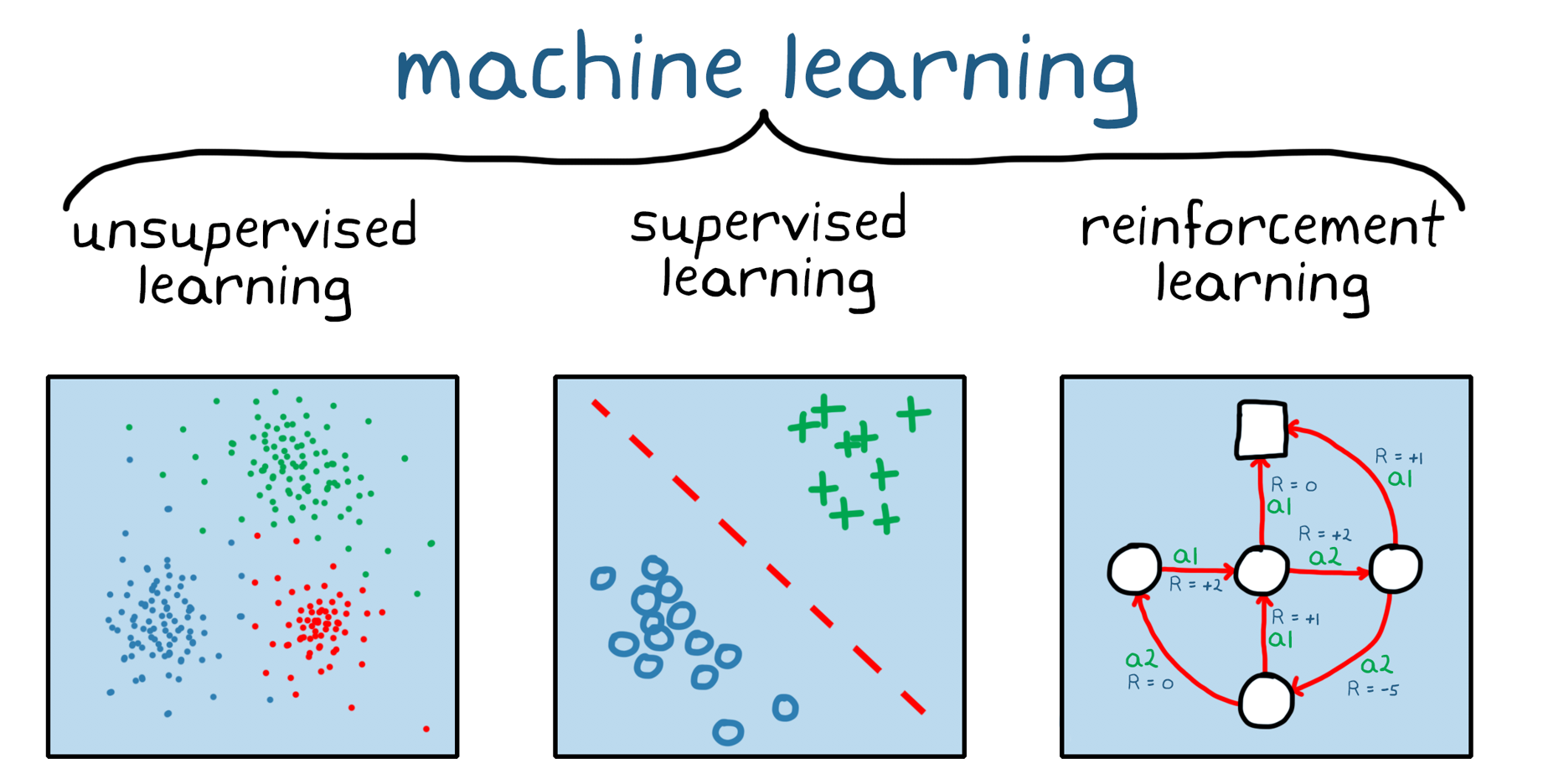
图1.三种广泛类别的机器学习:无监督学习,监督学习和加强学习。


例子of Reinforcement Learning Applications
深神经网络有钢筋学习培训可以编码复杂的行为。这允许替代方法对否则难以应变或更具挑战来解决更传统的方法的应用。例如,在自动驾驶中,神经网络可以通过同时查看诸如相机帧和激光雷达测量的多个传感器来决定如何通过同时查看转向轮。没有神经网络,问题通常会在较小的块中分解,如从相机帧中提取特征,过滤激光雷达测量,fusing the sensor outputs, and making “driving” decisions based on sensor inputs.
While reinforcement learning as an approach is still under evaluation for production systems, some industrial applications are good candidates for this technology.
先进的控件:控制非线性系统是一个具有挑战性的问题,通常通过在不同的操作点线性化系统来解决。增强学习可以直接应用于非线性系统。
Automated driving:根据相机输入制作驾驶决策是强化学习适用于考虑图像应用中深神经网络成功的领域。
机器人: Reinforcement learning can help with applications like robotic grasping, such as teaching a robotic arm how to manipulate a variety of objects for pick-and-place applications. Other robotics applications include human-robot and robot-robot collaboration.
Scheduling: Scheduling problems appear in many scenarios including traffic light control and coordinating resources on the factory floor towards some objective. Reinforcement learning is a good alternative to evolutionary methods to solve these combinatorial optimization problems.
校准: Applications that involve manual calibration of parameters, such as electronic control unit (ECU) calibration, may be good candidates for reinforcement learning.
钢筋学习背后的培训机制反映了许多现实世界的情景。考虑,例如,通过积极的加强培训。

图2.狗训练中的加强学习。
使用钢筋学习术语(图2),在这种情况下学习的目标是训练狗(代理)在环境中完成一项任务,包括狗的周围和培训师。首先,培训师发出命令或提示,狗观察(观察)。然后狗采取行动响应。如果该行动接近所需的行为,培训师可能会提供奖励,例如食物治疗或玩具;否则,将不提供奖励。在培训开始时,当给出的命令是“坐下”时,狗可能需要更多随机的动作,如“坐下”的命令,因为它试图将特定的观察与动作和奖励联系起来。此关联或映射在观察和操作之间称为策略。从狗的角度来看,理想的案例将是它将正确响应每个提示的理想情况,以便它尽可能多的零食。因此,加强学习培训的整个意义是“调整”狗的政策,以便它学会最大化一些奖励的所需行为。培训完成后,狗应该能够观察所有者并采取适当的行动,例如,当使用它开发的内部政策命令“坐下”时坐着。 By this point, treats are welcome but, theoretically, shouldn’t be necessary.
Keeping in mind the dog training example, consider the task of parking a vehicle using an automated driving system (Figure 3). The goal is to teach the vehicle computer (agent) to park in the correct parking spot with reinforcement learning. As in the dog training case, the environment is everything outside the agent and could include the dynamics of the vehicle, other vehicles that may be nearby, weather conditions, and so on. During training, the agent uses readings from sensors such as cameras, GPS, and lidar (observations) to generate steering, braking, and acceleration commands (actions). To learn how to generate the correct actions from the observations (policy tuning), the agent repeatedly tries to park the vehicle using a trial-and-error process. A reward signal can be provided to evaluate the goodness of a trial and to guide the learning process.
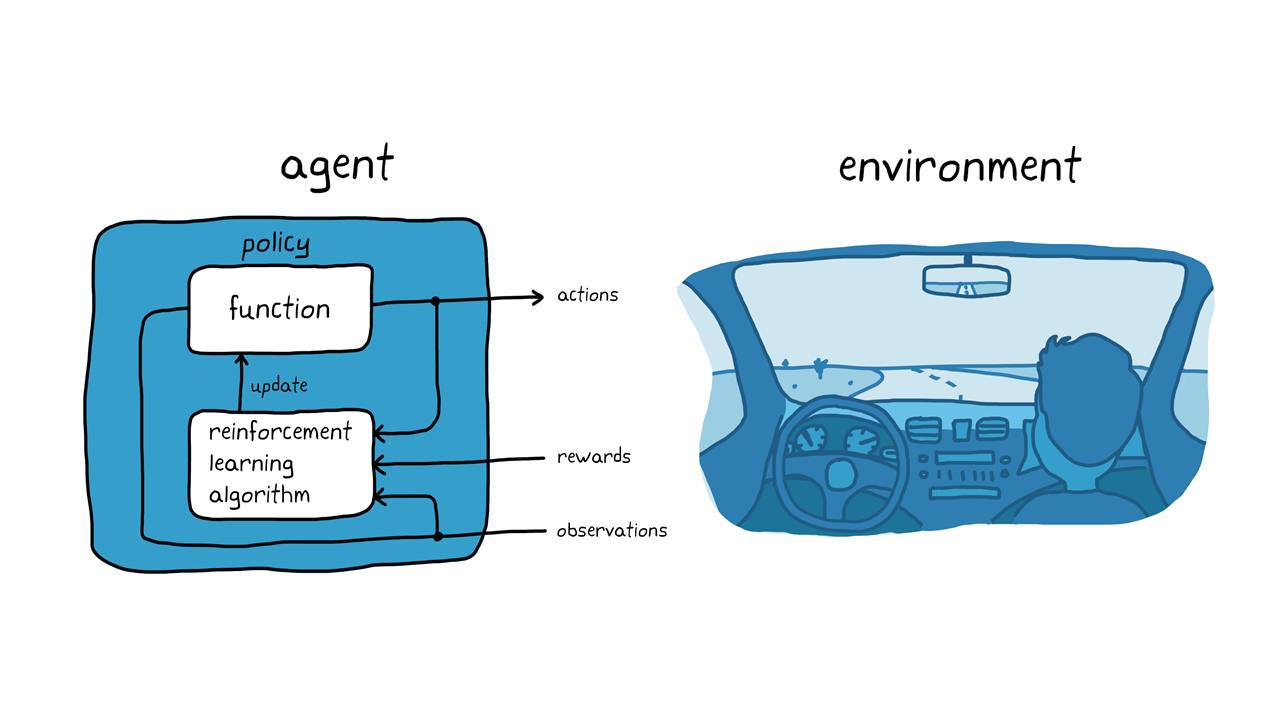
Figure 3. Reinforcement learning in autonomous parking.
在狗训练的例子中,训练正在发生在狗的大脑里面。在自动停车示例中,培训由培训算法处理。培训算法负责根据收集的传感器读数,操作和奖励调整代理的策略。培训完成后,车辆的计算机应该只能使用调谐策略和传感器读数停放。
One thing to keep in mind is that reinforcement learning is not sample efficient. That is, it requires a large number of interactions between the agent and the environment to collect data for training. As an example, AlphaGo, the first computer program to defeat a world champion at the game of Go, was trained non-stop for a period of a few days by playing millions of games, accumulating thousands of years of human knowledge. Even for relatively simple applications, training time can take anywhere from minutes, to hours or days. Also, setting up the problem correctly can be challenging as there is a list of design decisions that need to be made, which may require a few iterations to get right. These include, for example, selecting the appropriate architecture for the neural networks, tuning hyperparameters, and shaping of the reward signal.
加强学习工作流程
The general workflow for training an agent using reinforcement learning includes the following steps (Figure 4):

Figure 4. Reinforcement learning workflow.
1.创建环境
首先,您需要定义强化学习代理的操作,包括代理和环境之间的接口。环境可以是仿真模型,或实际物理系统,但模拟环境通常是良好的第一步,因为它们更安全并允许实验。
2.定义奖励
Next, specify the reward signal that the agent uses to measure its performance against the task goals and how this signal is calculated from the environment. Reward shaping can be tricky and may require a few iterations to get it right.
3.创建代理
Then you create the agent, which consists of the policy and the reinforcement learning training algorithm. So you need to:
a) Choose a way to represent the policy (such as using neural networks or look-up tables).
b)选择适当的训练算法。不同的表示通常与特定类别的培训算法相关联。但总的来说,大多数现代化的加强学习算法依赖神经网络,因为它们是大状态/行动空间和复杂问题的良好候选者。
4.培训并验证代理人
Set up training options (like stopping criteria) and train the agent to tune the policy. Make sure to validate the trained policy after training ends. If necessary, revisit design choices like the reward signal and policy architecture and train again. Reinforcement learning is generally known to be sample inefficient; training can take anywhere from minutes to days depending on the application. For complex applications, parallelizing training on multiple CPUs, GPUs, and computer clusters will speed things up (Figure 5).
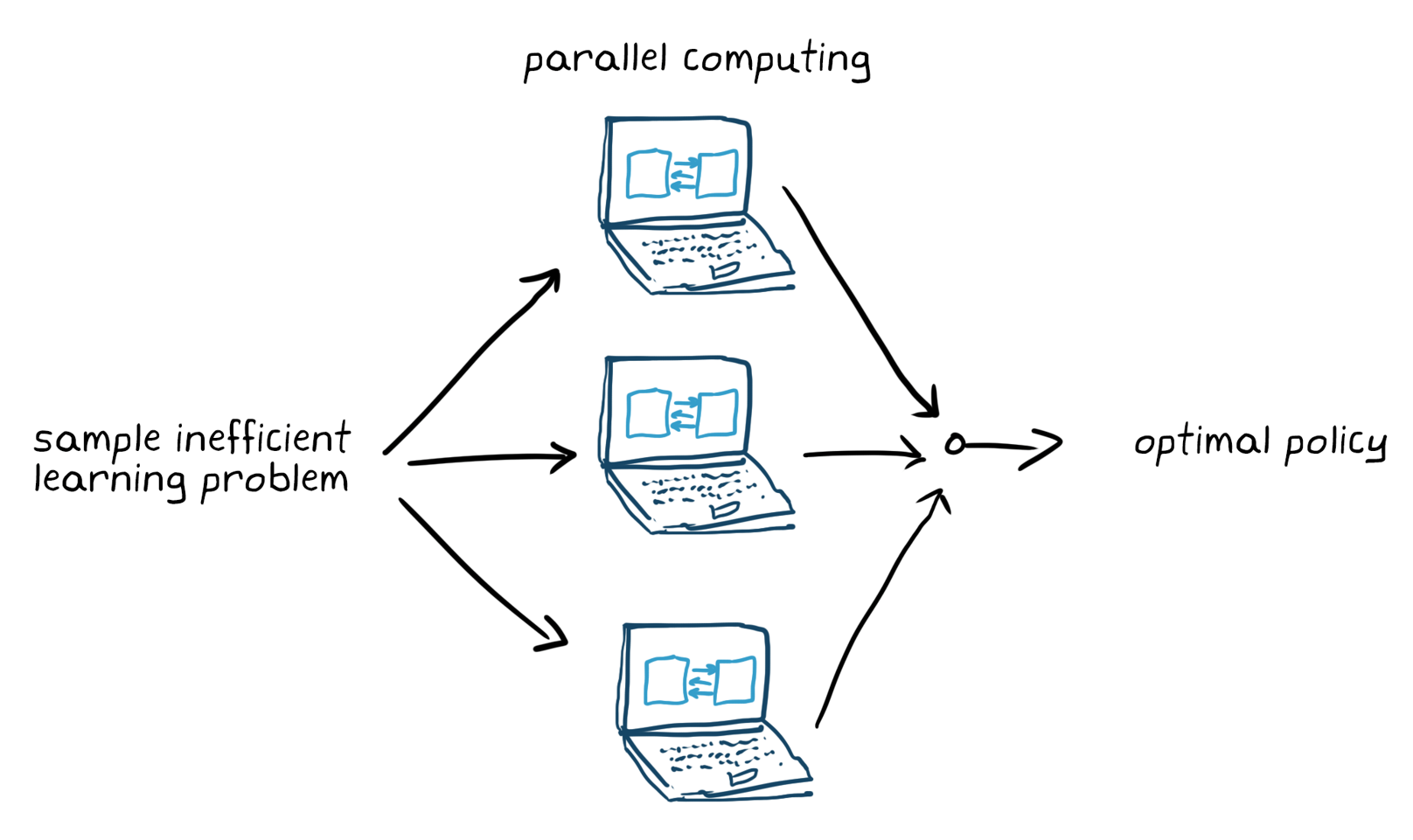
Figure 5. Training sample inefficient learning problem with parallel computing.
5. Deploy the policy
使用例如生成的C / C ++或CUDA代码部署训练策略表示。此时,该政策是独立的决策系统。
Training an agent using reinforcement learning is an iterative process. Decisions and results in later stages can require you to return to an earlier stage in the learning workflow. For example, if the training process does not converge to an optimal policy within a reasonable amount of time, you may have to update any of the following before retraining the agent:
- Training settings
- 强化学习算法配置
- Policy representation
- Reward signal definition
- 动作和观察信号
- 环境动态
MATLAB®和Reinforcement Learning Toolbox™简化强化学习任务。您可以通过通过加强学习工作流程的每一步,为机器人和自主系统等复杂系统实施控制器和决策算法。具体来说,你可以:
1. Create environments and reward functions using MATLAB and Simulink®
2.使用深层神经网络、多项式和看-up tables to define reinforcement learning policies
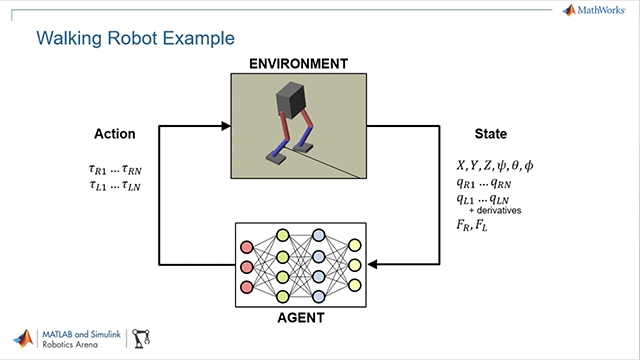
图6教授一款双层机器人与钢筋学习工具箱™一起行走
3.切换,评估和比较流行的强化学习算法,如DQN,DDPG,PPO和SAC,只有次要代码更改,或创建自己的自定义算法
4.使用Parallel Computing Toolbox™和MATLAB并行服务器™通过利用多个GPU,多个CPU,计算机集群和云资源来培训加固学习策略
5.使用Matlab Coder™和GPU编码器™生成代码并部署嵌入式设备的嵌入式设备
6. Get started with reinforcement learning usingreference examples.




30天免费试用

Questions?
选择一个网站
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select:.
Select网站您还可以从以下列表中选择一个网站: