为什么工业机器人需要工程师和成千上万的代码行业,即使是长颈鹿,马和许多其他动物在分娩的几分钟之内就可以走出最基本的,重复的任务?
我的同事和我在USC大脑身体动态实验室开始通过创建一个学会移动的机器人肢体来解决这个问题,没有先验知识的自己的结构或环境[1,2]。在几分钟内,G2P,我们在Matlab中实现的加固学习算法®,学会了如何将肢体移到推动跑步机(图1)。

肌腱驱动的肢体控制挑战
机器人肢体具有类似于肌肉和肌腱结构的架构,该结构能够为人类和脊椎动物运动提供动力[1,2]。肌腱将肌肉连接到骨骼,使得生物学可能成为可能的motors(肌肉)交货ert force on bones from a distance [3,4]. (The dexterity of the human hand is achieved through a tendon-driven system; there are no muscles in the fingers themselves!)
虽然肌腱具有机械和结构的优点,但是肌腱驱动的机器人比传统的机器人更具挑战性,而是传统的机器人,其中简单的PID控制器直接控制关节角度通常足够。在肌腱驱动的机器人肢体中,多个电动机可以作用在单个接头上,这意味着给定马达可以作用在多个接头上。结果,该系统同时是非线性的,过度确定的,过度确定的,大大增加了控制设计复杂性和呼叫新的控制设计方法。
G2P算法
G2P(常规)算法的学习过程有三个阶段:Motor Babbling,探索和开发。摩托车is a five-minute period in which the limb performs a series of random movements similar to the movements a baby vertebrate uses to learn the capabilities of its body.
During the motor babbling phase, the G2P algorithm randomly produces a series of step changes to the current of the limb’s three DC motors (Figure 2), and encoders at each limb joint measure joint angles, angular velocities, and angular accelerations.
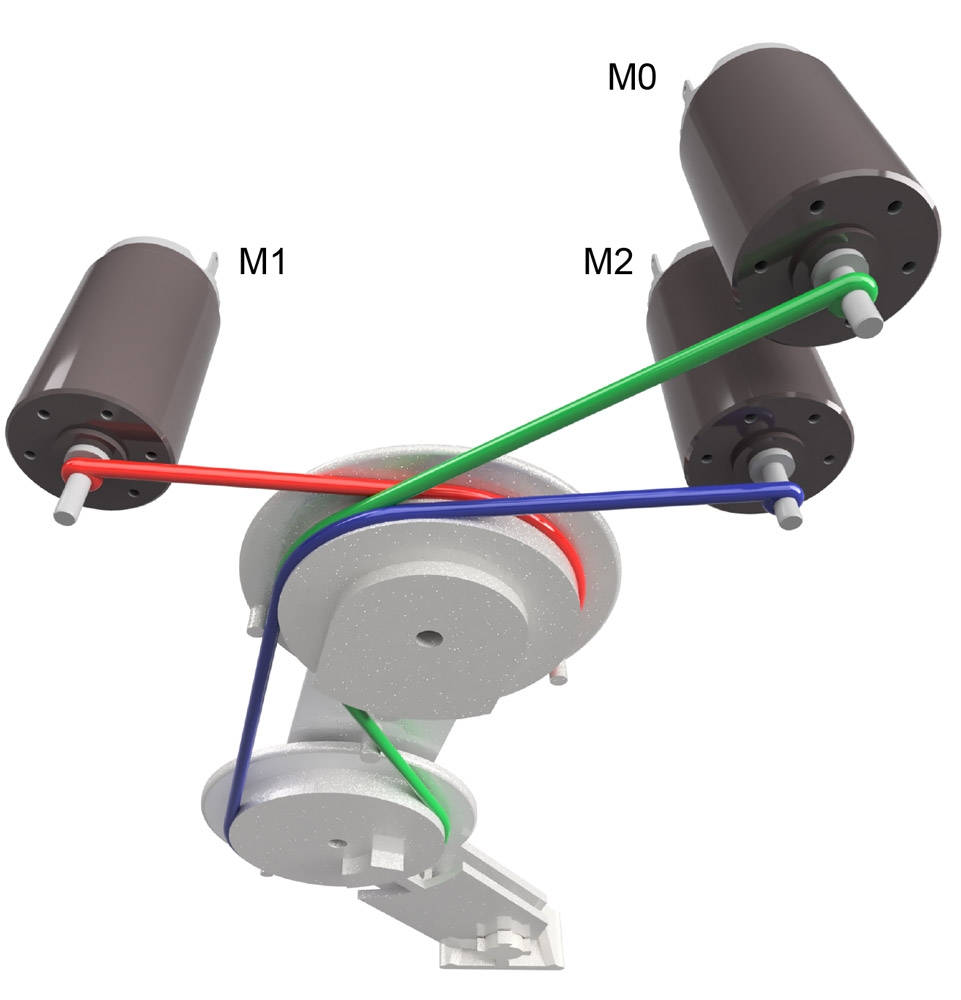
Figure 2. Robotic limb and DC motors.
The algorithm then generates a multilayer perceptron artificial neural network (ANN) using Deep Learning Toolbox™. Trained with the angular measurements as input data and the motor currents as output data, the ANN serves as an inverse map linking the limb kinematics to the motor currents that produce them (Figure 3).
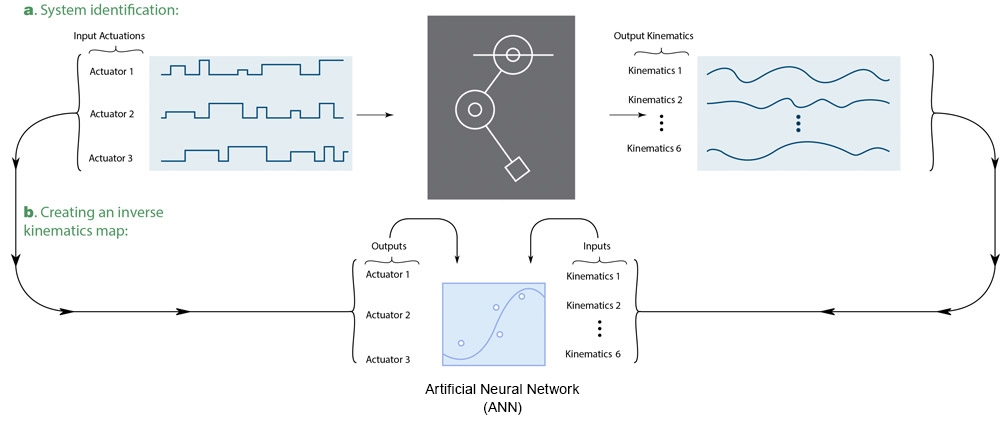
Figure 3. Artificial neural network (ANN) training on motor babbling data.
Next, the G2P algorithm enters an exploration phase, the first of two phases of reinforcement learning. In the exploration phase, the algorithm directs the robotic limb to repeat a series of cyclic movements and then the G2P algorithm measures how far the treadmill moved. For the cyclic movements, the algorithm uses a uniform random distribution to generate 10 points, with each point representing a pair of joint angles. These 10 points will be interpolated to create a complete trajectory in joint space for the cyclical move. The algorithm then calculates the angular velocities and accelerations for these trajectories and uses the inverse map to obtain the associated motor activation values for the complete cycle. The algorithm feeds these values to the limb’s three motors, repeating the cycle 20 times before checking how far the treadmill moved.
The distance that the limb propels the treadmill is the reward for that attempt: the greater the distance, the higher the reward. If the reward is small or nonexistent, then the algorithm generates a new random cycle and makes another attempt. The algorithm updates the inverse map with the new kinematic information gathered during each attempt. If, however, the reward exceeds a baseline performance threshold (an empirically determined 64 mm), then the algorithm enters its second reinforcement learning phase: exploitation.
In this phase, having identified a series of movements that works reasonably well, the algorithm begins looking for a better solution in the vicinity of the trajectory it previously tested. It does this by using a Gaussian distribution to generate random values near the values used in the previous attempt. If the reward for this new set of values is higher than the previous set, it keeps going, recentering the Gaussian distribution on the new best set of values. When an attempt produces a reward that is lower than the current best, those values are rejected in favor of the “best-so-far” values (Figure 4).
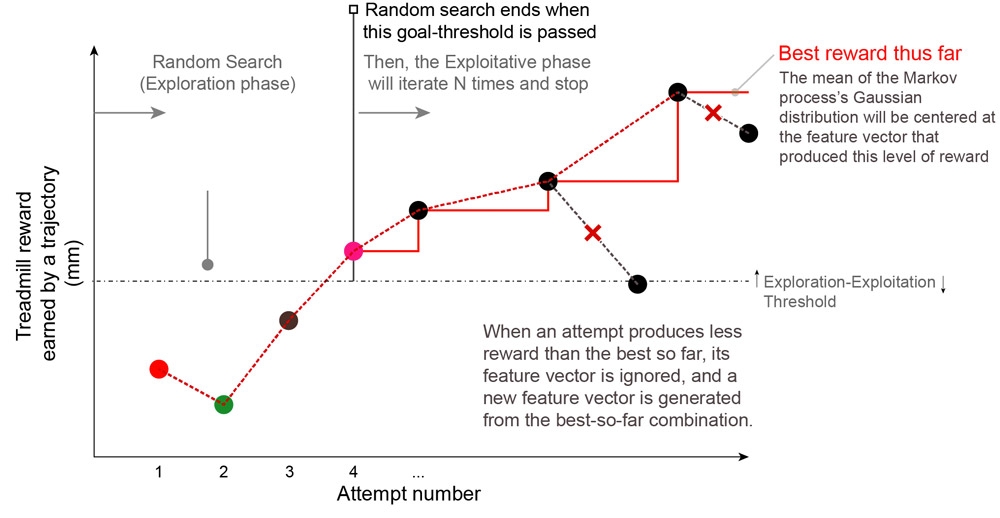
图4.勘探阶段G2P算法。
The Emergence of Unique Gaits
每次G2P算法都运行时,它开始重新学习,探索机器人肢体的动态与新的随机移动。当偶然地,偶然地,驾驶员欺骗或勘探阶段特别有效时,该算法学会更快,需要较少的尝试来达到利用阶段(图5)。该算法不寻求推动跑步机的最佳运动,只有足够好的动作。人类和其他生物也学会使用他们的身体“足够好”,因为与每次练习企图有相关的成本,包括伤害,疲劳和可以应用于学习其他技能的时间和能量的开支。

图5。跑步机奖励绘制了为15种不同运行的G2P算法中的每一个尝试。
从随机运动开始并搜索“足够好”解决方案的一个显着的结果是,每次运行时,算法都会产生不同的步态。我们已经看到了G2P算法产生各种各样的步态模式,从厚重踩到精致的尖端趾。我们称之为我们的机器人可以发展的这些独特的Gaits“电动人物”。我们相信这种方法将使机器人能够在未来拥有更多的人培养特征和特征。
添加反馈和未来增强功能
G2P的初始实施完全是前面的。结果,除了系统的被动响应之外,它无法响应扰动,例如碰撞。要解决此问题,我们实现了一种包含最小反馈的G2P版本[5]。即使在相当冗长的感觉延迟(100ms)的情况下,我们发现增加了简单的反馈,使这种新的G2P算法能够补偿来自逆图中的影响或缺陷所产生的错误。我们还发现反馈加速了学习,需要较短的Motor Babbly会话,或更少的探索/剥削尝试。
我们计划将G2P算法中体现的原则扩展到Biped和二次机器人的开发,以及机器人操纵。
为什么matlab?
我们的团队决定在其他可用软件包中使用Matlab进行此项目,原因有很多。首先,我们的研究是多学科的,涉及神经科学家和计算机科学家以及生物医学,机械和电气工程师。无论他们的纪律是什么,团队的每个成员都知道Matlab,使其成为一种共同的语言和有效的合作方式。
选择MATLAB的另一个原因是它使工作更容易对其他研究人员进行复制和扩展。我们写的代码可以在任何版本的MATLAB上运行。如果我们在Matlab中使用Filtfilt()应用零阶段数字过滤,我们可以自信地确信其他人将能够使用相同的功能并获得相同的结果。此外,在Python或C中,会有担心的包或库版本,以及需要更新或甚至降级到已经使用的其他包的依赖关系。在我的经验中,Matlab没有这样的局限性。
最后,我想提到Matlab附带的优秀客户支持。金宝app客户支持团队帮助我们解决了金宝app我们的数据收购的问题。他们对主题的响应时间和专业知识水平令人印象深刻。
我非常感谢我的同事DaríoUrbina-Meléndez和Brian Cohn,以及Brain-Body Dynamics Lab(Valerolab.org)和PI的主任Francisco Valero-Cuevas,他们在本文中描述的项目上与我合作。我还要感谢我们的赞助商,包括国防部,Darpa,NIH和USC研究生院支持这一项目。金宝app