聚类分析涉及应用聚类算法,目的是在数据集中发现隐藏的模式或分组。因此,它经常用于探索性数据分析,但也用于异常检测和监督学习的预处理。
聚类算法以这样一种方式形成分组,即一组(或一簇)中的数据比任何其他簇中的数据具有更高的相似性度量。可以使用各种相似度量,包括欧几里得、概率、余弦距离和相关性。大多数无监督学习方法是聚类分析的一种形式。
聚类算法分为两大类:
- 硬聚类,即每个数据点只属于一个聚类,如流行K-方法。
- 软聚类,其中每个数据点可以属于多个聚类,例如在高斯混合模型中。例如,语音中的音素可以建模为多个基本声音的组合,基因可以参与多种生物过程。

K-means clustering,它用质心来表示组——每个成员的平均值,如图中的星星所示。
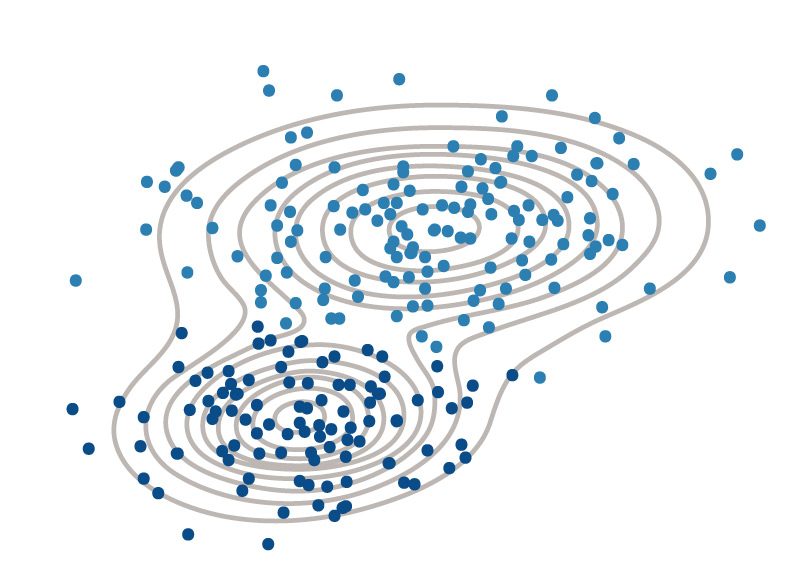
Gassian混合模型,分配簇成员概率,表示不同簇的关联强度。
聚类分析用于多种领域和应用,以识别模式和序列:
- 在数据压缩方法中,聚类可以表示数据而不是原始信号。
- 在分割算法中,簇表示图像和激光雷达点云的区域。
- 遗传聚类和序列分析被用于生物信息学。
在半监督学习中,聚类技术还用于建立标记数据和未标记数据之间的相似性,其中初始模型使用最小标记数据建立,并用于为原始未标记数据分配标签。相比之下,半监督聚类将有关聚类的可用信息合并到聚类过程中,例如,如果已知某些观测值属于同一个聚类,或者某些聚类与特定的结果变量相关联。
MATLAB®金宝app支持多种流行的聚类分析算法:
- 分层聚类通过创建群集树来构建群集的多级层次结构。
- k-均值聚类根据到聚类中心的距离将数据划分为k个不同的聚类。
- 高斯混合模型以多元正态密度分量的混合形式形成簇。
- 空间聚类(例如流行的基于密度的DBSCAN)对高密度区域中彼此接近的点进行分组,跟踪低密度区域中的异常值。可以处理任意非凸形状。
- 自组织映射使用学习数据拓扑和分布的神经网络。
- 谱聚类将输入数据转换为基于图的表示,其中的聚类比原始特征空间中分离得更好。通过研究图的特征值可以估计出簇的数目。
- 隐马尔可夫模型可用于发现序列中的模式,如生物信息学中的基因和蛋白质。
要点
- 聚类分析常用于探索性数据分析、异常检测和分割以及监督学习的预处理。
- K-均值和层次聚类仍然很流行,但对于非凸形状,需要更先进的技术,如DBSCAN和谱聚类。
- 可用于发现数据分组的其他无监督方法包括降维技术和特征排序。
MATLAB中的聚类分析实例
使用imsegkmeans命令(使用K-means算法),MATLAB将三个聚类分配给原始图像(组织用血氧毒素和伊红染色),将组织分割为三个类别(表示为白色、黑色和灰色)。自己尝试一下,以及相关的细分方法下面是一个代码示例.


