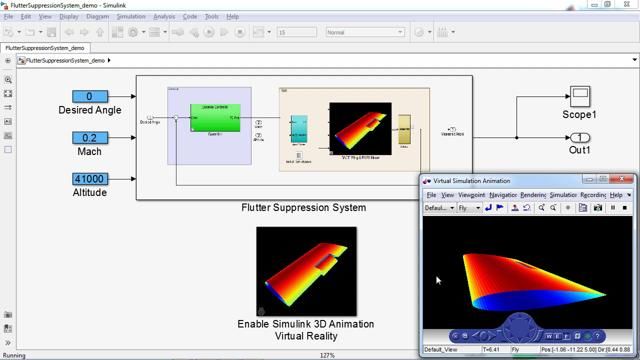
在本视频中,我们将展示在设计从FPGA到处理器的数据路径时,SoC Blockset如何用于建模和模拟硬件效果。
通过在开发应用程序时模拟硬件效果,您可以评估整体性能,而不需要在开发板上加载应用程序。此外,通过模拟,您可以比使用开发板更好地了解应用程序,因此您可以更快地识别问题并测试潜在的解决方案。
这是我们正在设计的应用程序的初始模型。它从外部源获取正弦数据流,将其分类为低频或高频信号,并照亮低频或高频探测器灯。
我们将使用拨动开关来选择低频和高频信号进行测试。为了进行测试,我们将在FPGA中生成测试信号。FPGA过滤输入流,然后将数据传递到缓冲区。这个初始模型使用了一个简单的理想缓冲区,足以检验算法。处理器处理一帧数据,检测信号,并打开相应的探测灯。
我们可以看到模型在运行。在模拟中,我们可以在低频和高频测试信号之间切换,我们看到探测器led亮起。这个模拟证明了该算法,但是现在我们想在DDR内存中加入缓冲的硬件效果,就像我们在硬件中配置它一样。SoC Blockset包括块和模板,帮助我们。
考虑我们应用程序的这张图。测试信号由FPGA以100 kHz的速率采样。处理器每10毫秒处理一帧数据。由于数据从FPGA异步传输到处理器,我们在FPGA内存和DDR内存中插入FIFO。虚线表示背压。这发生在内存缓冲区填满时,可能需要更多的数据留在FPGA的FIFO中,直到缓冲区被刷新。
以下是设计必须满足的两个要求:
- 允许的最大延迟是100毫秒
- 我们的样本不能超过万分之一
当我们试图满足这些要求时,我们将关注两个参数:帧大小和缓冲区的数量。
我们使用来自SoC块集的块来更准确地建模这个设计的架构。
- 此内存通道块模拟通过此DDR共享内存进行的数据传输。在这个模型中,内存通道模拟了通过DMA从FPGA到处理器的AXI4-Stream协议的实现。
- 内存控制器块进行仲裁并授予对内存的访问权。
- 寄存器通道模拟从处理器到FPGA的通信,我们看到FPGA块通过其输出引脚驱动led。
首先,我们使用800个样本的帧大小,每个样本消耗4字节。我们还指定内存区域将由11个缓冲区组成。我们设置了内存通道块的参数并进行了仿真。
在仿真过程中,我们可以在输入信号中切换低频信号和高频信号。我们可以看到来自处理器的数据输出信号,看到频率的变化,我们可以看到指示灯相应的变化。我们运行模拟100秒的时间,这个模型已经运行到完成。
我们打开内存通道块,它用于逐帧测量延迟。如图所示,模拟开始几秒钟后,延迟达到100 msec范围内的值。最大允许的延迟是100 msec,所以这个设计与延迟需求相差不大。既然我们已经接近需求了,让我们暂时继续。
另一项要求是,每10,000个样本中不能有超过1个被丢弃。使用SoC Blockset,我们可以对模型进行检测,从而确定样品是否被丢弃。我们可以从最上面的图表中看到,缓冲区的使用在模拟开始的3秒左右开始增加,并增加到5.5秒左右。中间的图表描绘了FIFO的使用情况,下面的图表描绘了已经丢弃的样本的数量。
在5.8秒左右,先进先出开始稳定地丢弃样本。在100秒结束时,将近900个样本被丢弃,我们可以看到,在每10秒的周期中,大约有100个样本被丢弃。这几乎正好是万分之一的要求极限。由于此设计不能很好地满足这两个规格,让我们尝试更改内存配置。
我们将把帧大小从800个增加到1000个样本,并将缓冲区数量从11个减少到9个。然后我们用新的参数重新运行模拟。
一旦模拟完成,我们就可以打开Memory Channel块。在这种情况下,延迟在模拟的23秒左右达到峰值,在那里它达到约78毫秒的延迟。请记住,最大允许的延迟是100毫秒,所以现在我们在这个限制下非常安全。
然后我们再次检查,看看我们是否在10000个样本中丢失少于1个的要求范围内。当我们看同样的三个变量时,我们可以看到没有样本被丢弃。这意味着我们现在的设计满足了我们的两个要求。
现在我们已经使用SoC Blockset模拟来确定帧大小和缓冲区数量,我们已经准备好在FPGA板上的硬件上实现设计,在那里我们可以使用SoC Blockset执行进一步的测试来验证我们的模拟结果。
总之,我们使用SoC Blockset来增加算法模型的硬件效果,这样我们就可以使用仿真来查看不同的帧大小和缓冲区数量是如何影响性能的。
通过用硬件架构模拟算法,我们能够在硬件上实现之前发现延迟和样本丢失等问题。