查找表是嵌入式设计的关键构造,通常用于加速算法的某些函数的运行时执行。例如,复杂的三角函数通常被更高效的LUT实现所取代。
让我们做一个简单的实验,把同样的原理应用到s形函数上,来研究我们如何加速深度学习推理的性能,尤其是在边缘。
s形函数是神经网络的关键构件,是深度学习网络中常用的非线性激活函数之一。
这里我们有一个简单的Simulink子系统,金宝app它模拟了s形函数。我将使用Lookup Table Optimizer应用程序生成一个最佳LUT,指定输入和输出数据类型。因为这是一个有界函数,我可以指定输出的界限,最后是1%的输出公差。
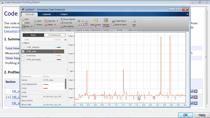
一旦优化问题被解决,我们可以查看比较图,以验证LUT近似的误差在我们指定的公差之内。
现在作为下一步,让我们从sigmoid函数和生成的LUT生成C代码,并将其部署到像Arduino板这样的cortex M平台上。
我们使用硬件在环模拟来运行带有来自Simulink的输入的生成代码。金宝app在这种模式下运行代码会有一些开销,但这仍然让我们对相对的执行速度有一个很好的比较。
从执行配置文件中可以看到,在Arduino上的LUT要快2.5倍。我在Cortex M7的stmicroelectronics发现板上重复了同样的测试。下面的图显示了不同数据类型查找表的相对加速。
事实上,如果您可以在所有神经元之间共享查找表近似值,那么执行速度将进一步降低几个数量级。你可以对其他激活函数做同样的实验,比如双曲正切函数。
要了解更多关于优化lut的设计,请参考视频下面的其他链接。