本专栏回答了一些有关MATLAB中的回归学习者应用程序的问题;这不是一般的回归。
自2017年以来,工程师和科学家就可以使用回归学习者应用了。回归分析帮助人们理解变量和数值响应之间的关系,并可应用于预测能源消耗、财务绩效和制造工艺参数等任务。
从根本上说,回归学习者应用程序使您能够交互式地建立回归模型,无需编写代码,并测量您的模型的准确性和性能。您可以快速比较各种回归模型和特性的性能。
这款应用对于刚开始学习机器学习的人特别有用,所以我很高兴能回答一些与这款应用直接相关的问题。
如果你不熟悉回归学习者应用程序,这里有一个演示视频让你熟悉:

像其他机器学习应用程序,重要的是在使用前进行预处理和清洁你的时间序列数据的应用程序。这包括任务,比如适应数据正确的格式,规范数据是所有在同一尺度,分发同样,处理重复或缺失的数据,和其他必要的。

您可以在回归学习者应用程序中做一些事情来加速训练。提醒一下,我关注的是应用程序本身的技术。
建议1:采用并行回归模型训练

建议2:使用hold - out验证
如果您的数据仍然很大,请确保您使用了正确的验证选项。当您在回归学习者应用程序中打开一个新的会话并选择数据时,交叉验证默认选中。
交叉验证可以帮助您将数据划分为一定数量的折叠(k),训练模型,并计算所有折线的平均测试误差。与其他选项相比,这种方法提供了更好的防止过拟合的保护,但需要多次拟合,因此它适用于小型和中型数据集。
拒绝验证帮助您使用滑块控件选择数据的百分比作为测试集。应用程序将在训练集上训练模型,并通过测试集评估其性能。用于测试的模型仅基于部分数据,所以holdout验证特别适用于大数据集。
当然,您也可以选择不验证您的模型,但这将导致您过度拟合训练数据。
在启动新会话时,默认情况下选择交叉验证。
建议3:只在一组模型类型上训练数据
建议4:精简您的训练数据
你经常听说如何得到足够的数据,但这里的关键是确保你有足够的数据正确的数据。您可能有一些多年前的不必要的历史数据,这些数据已经不再有用了。删除或减少这类数据可以加快训练速度,当然,您需要密切关注数据的准确性和表示。这应该是您最后的选择,因为您必须非常谨慎地减少您的数据。
这是一个非常好的问题!在您用数据对模型进行培训以解释结果之后,需要采取几个步骤。
步骤1:找出均方根误差最小的模型
RMSE度量预测值与每个模型观测值之间的距离,因此它度量这些残差的分布情况。该应用程序将在最低RMSE附近添加一个框。
步骤2:探索模型
一旦选择了RMSE最低的模型,下一步就是检查在图片中:较低的RMSE将被加粗,并有一个方框围绕。

较低的均方根误差将用粗体表示,并用方框围住。
响应图
响应图以垂直线表示预测响应与观测结果的对比。如果您对数据使用坚守验证或交叉验证,那么这个图就特别有趣,因为图中显示的预测是坚守观察结果,而模型还没有接受过这种训练。
图中:使用响应图查看预测和观察之间的距离。

预测图与实际图
预测图和实际图可以帮助您检查模型的性能。模型的预测响应与实际的、真实的响应相对应。在这幅图中,一个完美的回归模型的预测响应与观测值相同,所以所有的点都在对角线上。然而,这在现实生活中并不会发生,所以我们的目标是让这些点尽可能接近对角线,并大致对称地分散在该线周围。如果您在图中发现模式,那就意味着模型可以得到改进,您可以训练另一种模型类型,或者使用高级选项使模型更加灵活。
在图中:预测图和实际图帮助您可视化回归模型的准确性
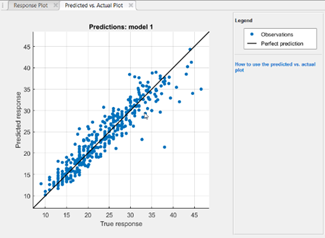
预测图与实际图可以帮助您可视化回归模型的准确性。
在培训和评估了数据的初始模型之后,您可以通过调优模型的超参数来确保最佳性能。
由于超参数调优的影响因模型而异,您必须为多种类型的模型优化超参数,因为初始模型可能不会产生最佳性能。
要使用经过充分训练和优化的模型对新数据进行预测,您需要将模型发送到其他地方。您可以将其导出到MATLAB的工作空间,或生成MATLAB代码,以训练模型使用相同的步骤在应用程序中。从那里,您可以使用MATLAB编译器™部署模型或使用MATLAB编码器™从模型生成C/ c++代码。