章
选择最佳机器学习分类模型及避免过拟合
使用机器学习建模对于任何处理数据的人来说都是一项具有挑战性但有价值的技能。无论你使用机器学习做什么,你都有可能遇到关于分类和过拟合的问题。这本电子书向您展示如何使用MATLAB减轻这些挑战的影响®.
第一章
分类模型
选择正确的分类模型
什么是数据分类模型?
分类模型用于根据特定的特征集将项目分配到一个离散的组或类。
为什么做对这么难?
在给定的场景中,每个模型都有自己的优点和缺点。在不过分简化考虑因素的情况下,没有可以用来确定应该使用哪个模型的简单流程图。选择数据分类模型还与业务案例密切相关,并对您要实现的目标有充分的理解。
如何选择合适的型号呢?
首先,确保你能回答以下问题:
- 你有多少数据,它是连续的吗?
- 它是什么类型的数据?
- 你想要完成什么?
- 可视化这个过程有多重要?
- 你需要多少细节?
- 存储是一个限制因素吗?

当您确信自己理解了将要处理的数据类型以及它的用途时,您就可以开始研究各种模型的优点了。有一些一般的经验规则可以帮助您选择最佳的分类模型,但这些只是起点。如果您正在处理大量数据(其中性能或准确性的微小差异可能会产生很大的影响),那么选择正确的方法通常需要反复试验,以实现复杂性、性能和准确性之间的适当平衡。下面几节描述了一些有必要了解的常见模型。
分类交叉验证
交叉验证是一种模型评估技术,用于评估机器学习算法在对尚未训练过的新数据集进行预测时的性能。这是通过划分数据集并使用子集来训练算法和用于测试的剩余数据来完成的。这种技术将在第3章中更详细地讨论。
常用分类模型
天真的贝叶斯

如果数据不复杂,你的任务相对简单,试试Naïve贝叶斯算法。这是一种高偏差/低方差分类器,在使用有限的可用数据来训练模型时,它比逻辑回归和最近邻算法具有优势。
Naïve Bayes在CPU和内存资源受限的情况下也是一个不错的选择。因为Naïve贝叶斯非常简单,它不会倾向于过度拟合数据,并且可以非常快速地训练。它还可以很好地处理用于更新分类器的连续新数据。
如果数据在规模和方差上增长,而您需要一个更复杂的模型,那么其他分类器可能会更好地工作。此外,它的简单分析也不是复杂假设的良好基础。
Naïve Bayes通常是科学家在处理文本时尝试的第一个算法(想想垃圾邮件过滤器和情感分析)。在排除这个算法之前,先试试这个算法是个好主意。
k最近的邻居

根据数据点与训练数据集中其他点的距离对数据点进行分类是一种简单而有效的数据分类方法。k-最近邻(kNN)是“关联犯罪”算法。
kNN是一种基于实例的懒惰学习者,这意味着没有真正的训练阶段。您将训练数据加载到模型中,并让它保持不变,直到您真正想要开始使用分类器。当您有一个新的查询实例时,k神经网络模型寻找指定的k最近邻居数;因此,如果k是5,然后你找到5个最近邻居的类。如果您想要应用一个标签或类,模型会投票决定它应该被归类到哪里。如果你在做一个回归问题,想要找到一个连续数,取的均值f的值k最近的邻居。
虽然培训时间的kNN较短,实际查询时间(和存储空间)可能比其他模型长。随着数据点数量的增长,这一点尤其正确,因为你要保留所有的训练数据,而不仅仅是一个算法。
这种方法最大的缺点是,它可能会被不相关的属性所欺骗,这些属性会掩盖重要的属性。决策树等其他模型能够更好地忽略这些干扰。有很多方法可以纠正这个问题,比如对数据施加权重,所以在决定使用哪个模型时,您需要使用自己的判断。
决策树

要了解决策树如何预测响应,请从根(开始)节点一直到包含响应的叶节点。分类树给出的响应是名义上的,比如真或假。回归树给出数值响应。
决策树是相对快速和容易遵循的;您可以看到从根到叶的路径的完整表示。如果你需要与对结论如何得出感兴趣的人分享结果,这一点尤其有用。
决策树的主要缺点是它们倾向于过拟合,但有集成方法来抵消这一点。Toshi Takeuchi写了一个很好的例子(用于Kaggle比赛)金宝app支持向量机

当数据只有两个类时,可以使用支持金宝app向量机(SVM)。支持向量机通过寻找将一个类别的所有数据点与另一个类别的所有数据点分开的最佳超平面来对数据进行分类(支持向量机的最佳超平面是两个类别之间的最大差值)。您可以使用具有两个以上类的SVM,在这种情况下,模型将创建一组二元分类子问题(每个子问题有一个SVM学习器)。
使用SVM有两个强大的优点。首先,它非常准确,而且不会过度拟合数据。其次,线性支持向量机相对容易解金宝app释。因为SVM模型非常快,一旦你的模型被训练好了,如果你的可用内存有限,你可以丢弃训练数据。它还倾向于利用一种称为“核技巧”的技术,很好地处理复杂的非线性分类。
但是,需要预先训练和调优svm,因此在开始使用它之前需要在模型上投入时间。此外,如果您使用的模型有两个以上的类,那么它的速度也会受到很大影响。
神经网络
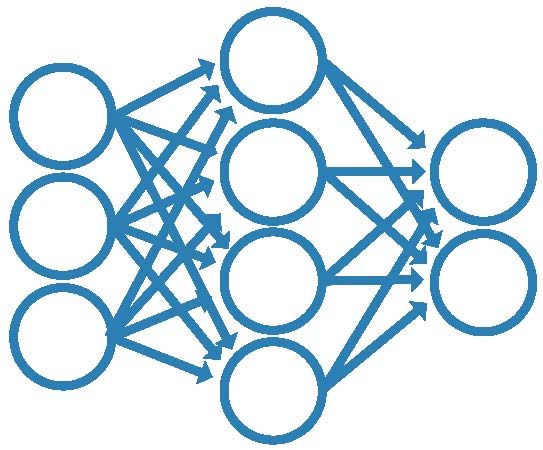
人工神经网络(ANN)可以学习,因此可以通过训练来找到解决方案、识别模式、分类数据和预测未来事件。金宝搏官方网站人们经常使用ann来解决更复杂的问题,例如字符识别、股票市场预测和图像压缩。
神经网络的行为是由其各个计算元素的连接方式以及这些连接的强度(或权重)定义的。根据指定的学习规则,通过训练网络自动调整权重,直到它正确地执行所需的任务。
对于有经验的用户,人工神经网络非常擅长建模具有大量输入特征的非线性数据。如果使用得当,人工神经网络可以解决用简单的算法难以解决的问题。然而,神经网络的计算成本很高,很难理解人工神经网络是如何得到解决方案的(因此也很难推断出算法),而且对人工神经网络进行微调通常是不实际的——你所能做的就是改变训练设置的输入并重新训练。