使用深度学习网络的鸡尾酒会源分离
这个例子展示了如何使用深度学习网络分离语音信号。
介绍
鸡尾酒会效应指的是大脑在过滤掉其他声音和背景噪音的同时专注于单个说话者的能力。人类在鸡尾酒会问题上表现得很好。这个例子展示了如何使用深度学习网络从一男一女同时讲话的语音组合中分离出单个发言者。
下载所需的文件
在详细介绍示例之前,您将下载一个经过预培训的网络和4个音频文件。
url =“http://ssd.mathworks.com/金宝appsupportfiles/audio/CocktailPartySourceSeparation.zip”;downloadNetFolder=tempdir;netFolder=fullfile(downloadNetFolder,“CocktailPartySourceSeparation”);如果~存在(netFolder“dir”) disp (下载预先训练的网络和音频文件(5个文件- 24.5 MB)…)解压缩(url,下载NetFolder)结束
问题总结
加载包含以4 kHz采样的男性和女性语音的音频文件。分别收听音频文件以供参考。
[mSpeech, Fs] = audioread (fullfile (netFolder,“MaleSpeech-16-4-mono-20secs.wav”));声音(mSpeech Fs)
[fSpeech] = audioread (fullfile (netFolder,“FemaleSpeech-16-4-mono-20secs.wav”)); 声音(fSpeech,Fs)
结合两种语言来源。确保资源在混合中有同等的力量。对混合进行归一化,使其最大振幅为1。
mSpeech=mSpeech/norm(mSpeech);fSpeech=fSpeech/norm(fSpeech);ampAdj=最大值(绝对值([mSpeech;fSpeech]);mSpeech=mSpeech/ampAdj;fSpeech=fSpeech/ampAdj;mix=mSpeech+fSpeech;混合=混合。/max(abs(混合));
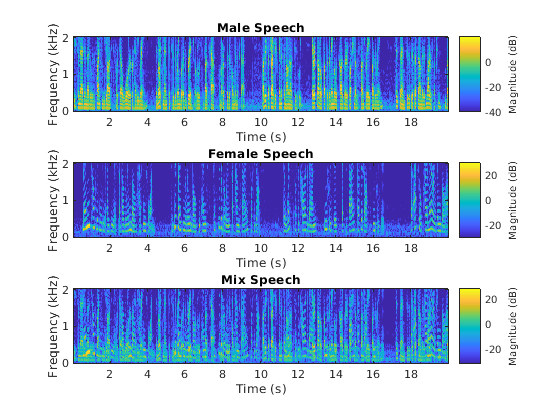
形象化原始和混合信号。听混合语音信号。这个例子展示了一个从语音混合中提取男性和女性源的源分离方案。
t =(0:元素个数(混合)1)* (1 / Fs);图(1)subplot(3,1,1) plot(t,mSpeech) title(“男性演讲》)网格在…上次要情节(3,1,2)情节(t, fSpeech)标题(“女性语言”)网格在…上次要情节(3、1,3)情节(t,混合)标题(“语音组合”)xlabel(“时间(s)”)网格在…上

听混音。
声音(混音,Fs)
时频表示
使用stft要可视化男性、女性和混合语音信号的时频(TF)表示,请使用长度为128的Hann窗口、长度为128的FFT窗口和长度为96的重叠窗口。
WindowLength=128;FFTLength=128;OverlapsLength=96;win=hann(WindowLength,“周期”);图(2)subplot(3,1,1) stft(mSpeech, Fs,“窗口”赢“重叠长度”,重叠长度,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);标题(“男性演讲》) subplot(3,1,2) stft(fSpeech, f, f)“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);标题(“女性语言”) subplot(3,1,3) stft(mix, Fs,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);标题(“混合”演讲)
使用理想时频掩模的源分离
应用TF掩模已被证明是一种有效的方法从竞争的声音中分离所需的音频信号。TF掩模是一个与底层STFT大小相同的矩阵。掩模与底层STFT逐单元相乘,以隔离所需的源。TF掩码可以是二进制的,也可以是软的。
使用理想二元掩模的源分离
在理想的二进制掩码中,掩码单元值为0或1。如果所需源的功率大于特定TF单元中其他源的组合功率,则该单元设置为1。否则,该单元设置为0。
为男性演讲者计算理想的二元掩模,然后将其可视化。
P_M = stft (mSpeech,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);P_F=stft(fSpeech,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”)[P_mix,F]=stft(mix,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);binaryMask=abs(P_M)>=abs(P_F);图(3)绘图掩码(binaryMask,WindowLength-重叠长度,F,Fs)

通过将混合STFT乘以男性说话人的二进制掩码来估计男性语音STFT。通过将混合STFT乘以男性说话人二进制掩码的倒数来估计女性语音STFT。
P_M_Hard = P_mix .* binarmask;P_F_Hard = P_mix .* (1-binaryMask);
使用逆短时FFT(ISTFT)估计男性和女性音频信号。可视化估计和原始信号。聆听估计的男性和女性语音信号。
mspeech = istft(P_M_Hard,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);fSpeech_Hard=istft(P_F_Hard,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);图(4)subplot(2,2,1) plot(t,mSpeech) axis([t(1) t(end) -1 1]) title(“原创男性演讲”)网格在…上subplot(2,2,3) plot(t, mspeech - hard) axis([t(1) t(end) -1 1]) xlabel(“时间(s)”)标题(“估计男性讲话”)网格在…上subplot(2,2,2) plot(t,fSpeech) axis([t(1) t(end) -1 1]) title(“原创女性演讲”)网格在…上子地块(2,2,4)图(t,fSpeech_硬)轴([t(1)t(end)-11])标题(“估计女性演讲”)xlabel(“时间(s)”)网格在…上

声音(mSpeech_Hard Fs)
声音(fSpeech_Hard Fs)
使用理想的软面膜分离源
在软掩模中,TF掩模单元值等于所需的源功率与总混合功率的比值。TF细胞的值在[0,1]范围内。
计算公喇叭的软掩码。通过将混合STFT乘以男性扬声器的软掩模来估计男性扬声器的短时傅里叶变换。通过将混合STFT乘以女性发言人的软掩模来估计女性发言人的STFT。
使用ISTFT估计男性和女性音频信号。
softMask = abs (P_M)。/ (abs (P_F) + abs (P_M) + eps);P_M_Soft = P_mix .* softMask;P_F_Soft = P_mix .* (1-softMask);mSpeech_Soft = istft (P_M_Soft,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);fSpeech_Soft=istft(P_F_Soft,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);
可视化估计和原始信号。听估计的男性和女性的语音信号。注意,结果非常好,因为掩码是在完全了解分离的男性和女性信号的情况下创建的。
图(5)subplot(2,2,1) plot(t,mSpeech) axis([t(1) t(end) -1 1]) title(“原创男性演讲”)网格在…上subplot(2,2,3) plot(t, mspeech - soft) axis([t(1) t(end) -1 1]) title(“估计男性讲话”)网格在…上子地块(2,2,2)图(t,fSpeech)轴([t(1)t(end)-11])xlabel(“时间(s)”)标题(“原创女性演讲”)网格在…上subplot(2,2,4) plot(t, fspeech - soft) axis([t(1) t(end) -1 1]) xlabel(“时间(s)”)标题(“估计女性演讲”)网格在…上

声音(mSpeech_Soft Fs)
声音(fSpeech_Soft Fs)
基于深度学习的掩码估计
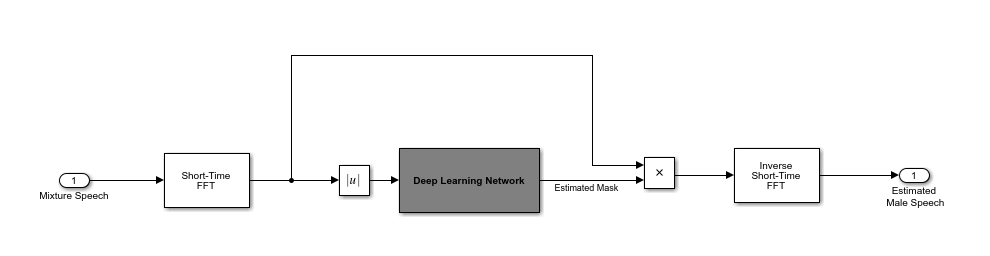
本例中的深度学习网络的目标是估计上述理想的软面具。该网络估计与男性说话人对应的面具。女性说话人面具直接来自男性面具。
基本的深度学习培训方案如下所示。预测因子是混合(男性+女性)的幅度谱音频。目标是与男性扬声器相对应的理想软掩模。回归网络使用预测器输入来最小化其输出和输入目标之间的均方误差。在输出时,音频STFT使用输出幅度谱和混合信号的相位转换回时域。

使用短时傅里叶变换(STFT)将音频变换到频域,窗口长度为128个样本,重叠为127个,并使用Hann窗口。通过删除与负频率对应的频率样本(因为时域语音信号是真实的,这不会导致任何信息丢失),可以将频谱向量的大小减小到65。预测器输入由20个连续的STFT向量组成。输出是一个65×20的软掩模。
你用训练过的网络来估计男性的讲话。输入到训练网络的是混合(男性+女性)语音音频。
STFT目标和预测
本节说明如何从训练数据集生成目标和预测信号。
阅读训练信号,分别由男性和女性演讲者的约400秒的讲话组成,采样频率为4khz。采用低采样率来提高训练速度。修剪训练信号,使它们的长度相同。
maleTrainingAudioFile =“malespeech - 16 - 4 - mono - 405 secs.wav”;femaleTrainingAudioFile =“femalespeech - 16 - 4 - mono - 405 secs.wav”;maleSpeechTrain=audioread(完整文件(netFolder,maleTrainingAudioFile));femaleSpeechTrain=audioread(完整文件(netFolder,femaleSpeechTrain AudioFile));L=min(长度(maleSpeechTrain),长度(femaleSpeechTrain));maleSpeechTrain=maleSpeechTrain(1:L);femaleSpeechTrain=femaleSpeechTrain(1:L);
读入验证信号,包括分别来自男性和女性扬声器的约20秒的语音,采样频率为4 kHz。修剪验证信号,使其长度相同
maleValidationAudioFile =“MaleSpeech-16-4-mono-20secs.wav”;femaleValidationAudioFile =“FemaleSpeech-16-4-mono-20secs.wav”;maleSpeechValidate=audioread(完整文件(netFolder,maleValidationAudioFile));femaleSpeechValidate=audioread(完整文件(netFolder,femaleValidationAudioFile));L=min(长度(maleSpeechValidate),长度(femaleSpeechValidate));maleSpeechValidate=maleSpeechValidate(1:L);femaleSpeechValidate=femaleSpeechValidate(1:L);
将训练信号缩放到相同的功率。将验证信号放大到相同的功率。
maleSpeechTrain = maleSpeechTrain /规范(maleSpeechTrain);femaleSpeechTrain = femaleSpeechTrain /规范(femaleSpeechTrain);ampAdj = max (abs ([maleSpeechTrain; femaleSpeechTrain]));maleSpeechTrain = maleSpeechTrain / ampAdj;femaleSpeechTrain = femaleSpeechTrain / ampAdj;maleSpeechValidate = maleSpeechValidate /规范(maleSpeechValidate);femaleSpeechValidate = femaleSpeechValidate /规范(femaleSpeechValidate);ampAdj = max (abs ([maleSpeechValidate; femaleSpeechValidate]));maleSpeechValidate = maleSpeechValidate / ampAdj;femaleSpeechValidate = femaleSpeechValidate / ampAdj;
创建培训和验证“鸡尾酒会”混合。
mixTrain =男性语音列车+女性语音列车;mixTrain = mixTrain / max(mixTrain);mixValidate = maleSpeechValidate + femaleSpeechValidate;mixValidate = mixValidate / max(mixValidate);
生成培训STFT。
WindowLength = 128;FFTLength = 128;OverlapLength = 128 - 1;Fs = 4000;赢得=损害(WindowLength,“周期”); P_mix0=stft(混合序列,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);P_M = abs (stft (maleSpeechTrain“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”)); P_F=abs(stft(女性Peechtrain,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”));
取混合STFT的日志。通过其平均值和标准偏差对值进行标准化。
P_mix = log(abs(P_mix0) + eps);议员=意味着(P_mix (:));SP =性病(P_mix (:));P_mix = (P_mix - MP) / SP;
生成验证STFT。获取混合STFT的日志。通过其平均值和标准偏差对值进行标准化。
P_Val_mix0=stft(mixValidate,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);P_Val_M = abs (stft (maleSpeechValidate“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”));P_Val_F = abs (stft (femaleSpeechValidate“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”))P_Val_mix=log(abs(P_Val_mix0)+eps);MP=mean(P_Val_mix(:);SP=std(P_Val_mix(:);P_Val_mix=(P_Val_mix-MP)/SP;
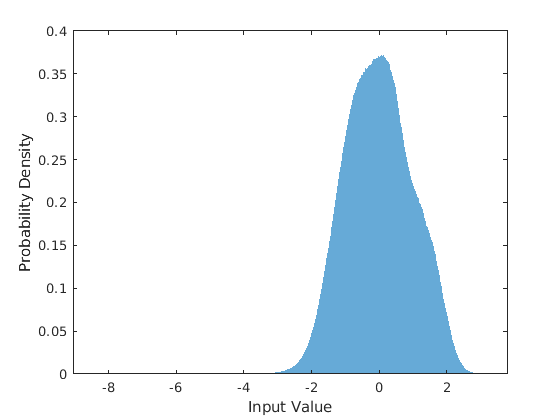
当神经网络的输入具有合理的平滑分布并被归一化时,神经网络的训练是最容易的。为了检查数据分布是否平滑,绘制训练数据的STFT值的直方图。
图(6)直方图(P_混合、,“EdgeColor”,“没有”,“归一化”,“pdf”)xlabel(“输入值”)伊拉贝尔(“概率密度”)
计算训练软掩码。在训练网络时,将此掩模作为目标信号。
maskTrain = P_M ./ (P_M + P_F + eps);
计算验证软掩码。使用此掩码来评估经过训练的网络发出的掩码。
maskValidate=P_Val_M./(P_Val_M+P_Val_F+eps);
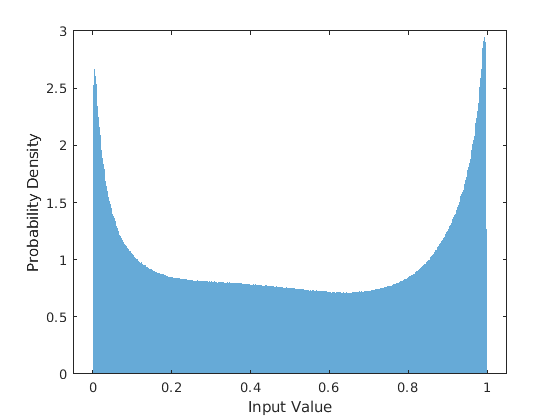
为了检查目标数据的分布是否平滑,绘制训练数据掩模值的直方图。
图(7)直方图(maskTrain“EdgeColor”,“没有”,“归一化”,“pdf”)xlabel(“输入值”)伊拉贝尔(“概率密度”)
从预测器和目标信号创建大小为(65,20)的块。为了得到更多的训练样本,在连续的块之间使用10个分段的重叠。
seqLen = 20;seqOverlap = 10;mixSequences = 0 (1 + FFTLength/2,seqLen,1,0);maskSequences = 0 (1 + FFTLength/2,seqLen,1,0);loc = 1;而loc%#嗯maskSequences(:,:,:,结束+ 1)= maskTrain (:, loc: loc + seqLen-1);%#嗯loc = loc + seqOverlap;结束
从验证预测器和目标信号创建大小为(65,20)的块。
mixValSequences = 0 (1 + FFTLength/2,seqLen,1,0);maskValSequences = 0 (1 + FFTLength/2,seqLen,1,0);seqOverlap = seqLen;loc = 1;而loc%#嗯maskValSequences(:,:,:,end+1)=maskValidate(:,loc:loc+seqLen-1);%#嗯loc = loc + seqOverlap;结束
重塑训练和验证信号。
mixSequencesT=重塑(mixSequences,[1(1+fft长度/2)*序列大小(mixSequences,4)]);mixSequencesV=重塑(mixValSequences,[11(1+FFT长度/2)*序列大小(mixValSequences,4)];maskSequencesT=重塑(maskSequences,[11(1+fft长度/2)*序列大小(maskSequences,4)]);maskSequencesV=重塑(maskValSequences,[11(1+FFT长度/2)*序列大小(maskValSequences,4)];
定义深度学习网络
定义网络的层次。指定输入大小为尺寸为1 × 1 × 1300的图像。定义两个隐藏的完全连接层,每个层有1300个神经元。跟随每一个隐藏的完全连接的层与乙状体层。批处理归一化层对输出的平均值和标准偏差进行归一化。添加一个有1300个神经元的完全连接层,然后是一个回归层。
numNodes = (1 + FFTLength/2) * seqLen;层= [...imageInputLayer([1 1 (1 + FFTLength/2)*seqLen],“归一化”,“没有”) fulllyconnectedlayer (numNodes) BiasedSigmoidLayer(6) batchNormalizationLayer dropoutLayer(0.1) fulllyconnectedlayer (numNodes) BiasedSigmoidLayer(6) batchNormalizationLayer dropoutLayer(0.1) fulllyconnectedlayer (numNodes) BiasedSigmoidLayer(0) regressionLayer;
指定网络的训练选项。集MaxEpochs到3.这样网络就可以对训练数据进行三次传递MiniBatchSize到64这样网络就可以看到64每次训练信号。集阴谋到训练进步生成随迭代次数增加而显示训练进度的绘图。设置详细的到假禁用将与绘图中显示的数据相对应的表输出打印到命令行窗口。集洗牌到every-epoch在每个历元开始时洗牌训练序列。设置LearnRateSchedule到分段每经过一定数量的纪元(1),学习率就降低一个指定的因子(0.1)。集ValidationData到验证预测值和目标。设置验证频率以便每个历元计算一次验证均方误差。本例使用自适应矩估计(ADAM)求解器。
maxEpochs=3;miniBatchSize=64;options=trainingOptions(“亚当”,...“MaxEpochs”,maxEpochs,...“MiniBatchSize”,小批量,...“SequenceLength”,“最长”,...“洗牌”,“每个时代”,...“详细”,0,...“阴谋”,“培训进度”,...“验证频率”、地板(大小(mixSequencesT, 4) / miniBatchSize),...“ValidationData”,{mixSequencesV,maskSequencesV},...“LearnRateSchedule”,“分段”,...“LearnRateDropFactor”, 0.9,...“LearnRateDropPeriod”1);
培训深度学习网络
使用指定的培训选项和层体系结构培训网络trainNetwork。由于培训集很大,培训过程可能需要几分钟。若要加载预培训的网络,请设置doTraining到假.
doTraining=true;如果doTraining CocktailPartyNet=列车网络(mixSequencesT、maskSequencesT、layers、options);其他的s =负载(“CocktailPartyNet.mat”);CocktailPartyNet = s.CocktailPartyNet;结束
将验证预测器传递给网络。输出是估计的掩码。重塑估计掩码。
estimatedMasks0=预测(CocktailPartyNet,mixSequencesV);estimatedMasks0=estimatedMasks0';estimatedMasks0=重塑(estimatedMasks0,1+FFT长度/2,numel(estimatedMasks0)/(1+FFT长度/2));
评估深度学习网络
绘制实际掩码和预期掩码之间的误差直方图。
图(8)直方图(maskValSequences(:) - estimatedMasks0(:),“EdgeColor”,“没有”,“归一化”,“pdf”)xlabel(“面具错误”)伊拉贝尔(“概率密度”)

评估软掩模估计
估计男性和女性的软口罩。通过对软掩码设置阈值来估计公、母二进制掩码。
SoftMaleMask=estimatedMasks0;SoftFemaleMask=1-SoftMaleMask;
缩短混合STFT以匹配估计遮罩的大小。
P_Val_mix0=P_Val_mix0(:,1:size(软掩码,2));
将混合短时傅里叶变换与男性软掩模相乘得到估计的男性语音短时傅里叶变换。
P_Male = P_Val_mix0 .* SoftMaleMask;
使用ISTFT获取估计的男性音频信号。缩放音频。
maleSpeech_est_soft = istft (P_Male,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“ConjugateSymmetric”,真的,...“FrequencyRange”,“片面的”); maleSpeech_est_soft=maleSpeech_est_soft/max(abs(maleSpeech_est_soft));
将估计的和原始的男性语音信号可视化。听估计软面具男性讲话。
范围=(numel(win):numel(maleSpeech_est_soft)-numel(win));t=范围*(1/Fs);图(9)子地块(2,1,1)图(t,maleSpeechValidate(range))标题(“原创男性演讲”)xlabel(“时间(s)”)网格在…上子地块(2,1,2)图(t,maleSpeech_est_soft(range))xlabel(“时间(s)”)标题(“估计男性语言(软面具)”)网格在…上

声音(声音范围,Fs)
将混合短时傅里叶变换与女性软掩模相乘得到估计的女性语音短时傅里叶变换。使用ISTFT获取估计的男性音频信号。缩放音频。
P_Female = P_Val_mix0 .* sofemalask;femaleSpeech_est_soft = istft (P_Female,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“ConjugateSymmetric”符合事实的...“FrequencyRange”,“片面的”);femaleSpeech_est_soft=femaleSpeech_est_soft/max(femaleSpeech_est_soft);
想象估计的和原始的女性信号。听估计的女性讲话。
范围=(numel(win):numel(maleSpeech_est__soft)-numel(win));t=范围*(1/Fs);图(10)子地块(2,1,1)图(t,femaleSpeechValidate(range))标题(“原创女性演讲”)网格在…上次要情节(2,1,2)情节(t, femaleSpeech_est_soft(范围)包含(“时间(s)”)标题(“估计女性语言(软面具)”)网格在…上

声音(femaleSpeech_est_soft(范围)、Fs)
评估二进制掩码估计
通过对软掩码设置阈值来估计公、母二进制掩码。
硬屏蔽=软屏蔽>=0.5;硬屏蔽=软屏蔽<0.5;
将混合短时傅里叶变换乘以男性二值掩模得到估计的男性语音短时傅里叶变换。使用ISTFT获取估计的男性音频信号。缩放音频。
P_Male=P_Val_mix0.*硬男性面具;男性语言(P_Male,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“ConjugateSymmetric”,真的,...“FrequencyRange”,“片面的”);maleSpeech_est_hard = maleSpeech_est_hard / max(maleSpeech_est_hard);
可视化估计和原始的男性语言信号。听估计二元掩模男性讲话。
范围=(numel(win):numel(maleSpeech_est_soft)-numel(win));t=范围*(1/Fs);图(11)子地块(2,1,1)图(t,maleSpeechValidate(range))标题(“原创男性演讲”)网格在…上次要情节(2,1,2)情节(t, maleSpeech_est_hard(范围)包含(“时间(s)”)标题(“估计男性语言(二元面具)”)网格在…上
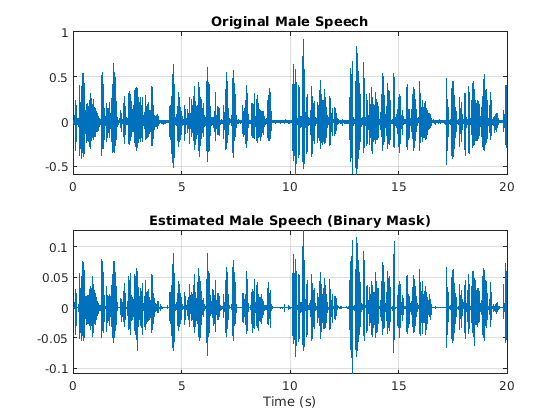
声音(音域,Fs)
将混合STFT乘以女性二进制掩码,得到估计的男性语音STFT。使用ISTFT获得估计的男性音频信号。缩放音频。
P_Female = P_Val_mix0 .* HardFemaleMask;femaleSpeech_est_hard = istft (P_Female,“窗口”赢“重叠长度”OverlapLength,...“FFTLength”,fft长度,“ConjugateSymmetric”,真的,...“FrequencyRange”,“片面的”); femaleSpeech_est_hard=femaleSpeech_est_hard/max(femaleSpeech_est_hard);
形象化估计和原始的女性语言信号。听一听估计的女性演讲。
=(元素个数(赢得):元素个数(maleSpeech_est_soft)元素个数(赢得));t = range * (1/Fs);图(12)subplot(2,1,1) plot(t,femaleSpeechValidate(range)) title(“原创女性演讲”)网格在…上次要情节(2,1,2)情节(t, femaleSpeech_est_hard(范围)标题(“估计女性言语(二元掩码)”)网格在…上
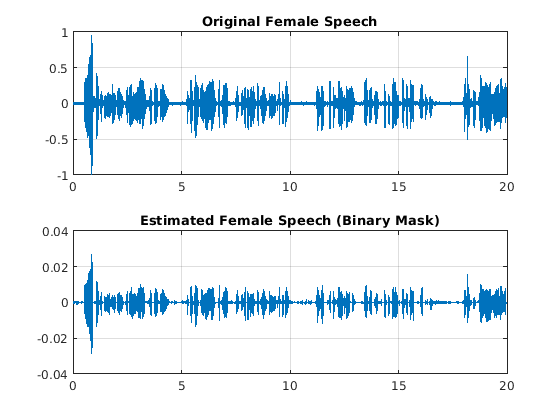
声音(femaleSpeech_est_hard(范围)、Fs)
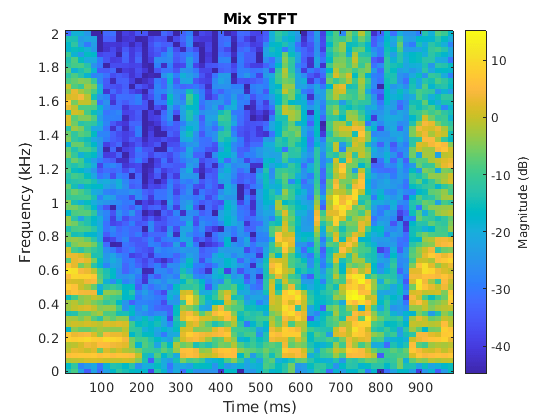
比较混合、原始女性和男性、估计女性和男性的一秒片段的STFTs。
范围=7e4:7.4e4;图(13)stft(混合验证(范围),Fs,“窗口”赢“重叠长度”, 64,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);标题(“混合STFT”)
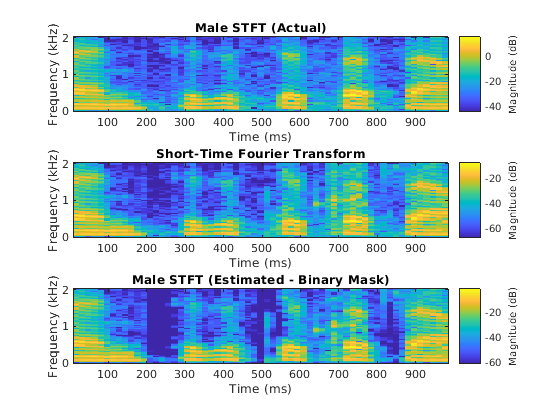
图(14)次要情节(3,1,1)stft (maleSpeechValidate(范围),Fs,“窗口”赢“重叠长度”, 64,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);标题(“男性STFT(实际)”)子批次(3,1,2)stft(maleSpeech_est__soft(范围)),Fs,“窗口”赢“重叠长度”, 64,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);子批次(3,1,3)stft(maleSpeech_est__hard(range)),Fs,“窗口”赢“重叠长度”, 64,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);标题(男性STFT(估计-二元掩模));
图(15)子批次(3,1,1)stft(女性视觉验证(范围),Fs,“窗口”赢“重叠长度”, 64,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);标题(“女性STFT(实际)”次要情节(3、1、2)stft (femaleSpeech_est_soft(范围),Fs,“窗口”赢“重叠长度”, 64,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);标题(“女性STFT(估计-软面膜)”次要情节(3,1,3)stft (femaleSpeech_est_hard(范围),Fs,“窗口”赢“重叠长度”, 64,...“FFTLength”,fft长度,“FrequencyRange”,“片面的”);标题(“女性STFT(估计-二进制掩码)”)

参考文献
[1] “卷积深度神经网络中的概率二进制掩码鸡尾酒会源分离”,Andrew J.R.Simpson,2015年。