聪明的演讲者在仿真软件模型金宝app
这个例子展示了如何建模仿真软件的智能扬声器系统。金宝app聪明的扬声器集成了语音命令识别和实时运行。
介绍
智能扬声器是一个演讲者,可以控制你的声音。这个例子显示了一个聪明的扬声器模式响应语音指令。你聪明的扬声器播放音乐的命令“走”。你让它停止播放音乐,说“停止”。你的音乐音量增加或减少“向上”和“向下”的命令,分别。
模型的总结
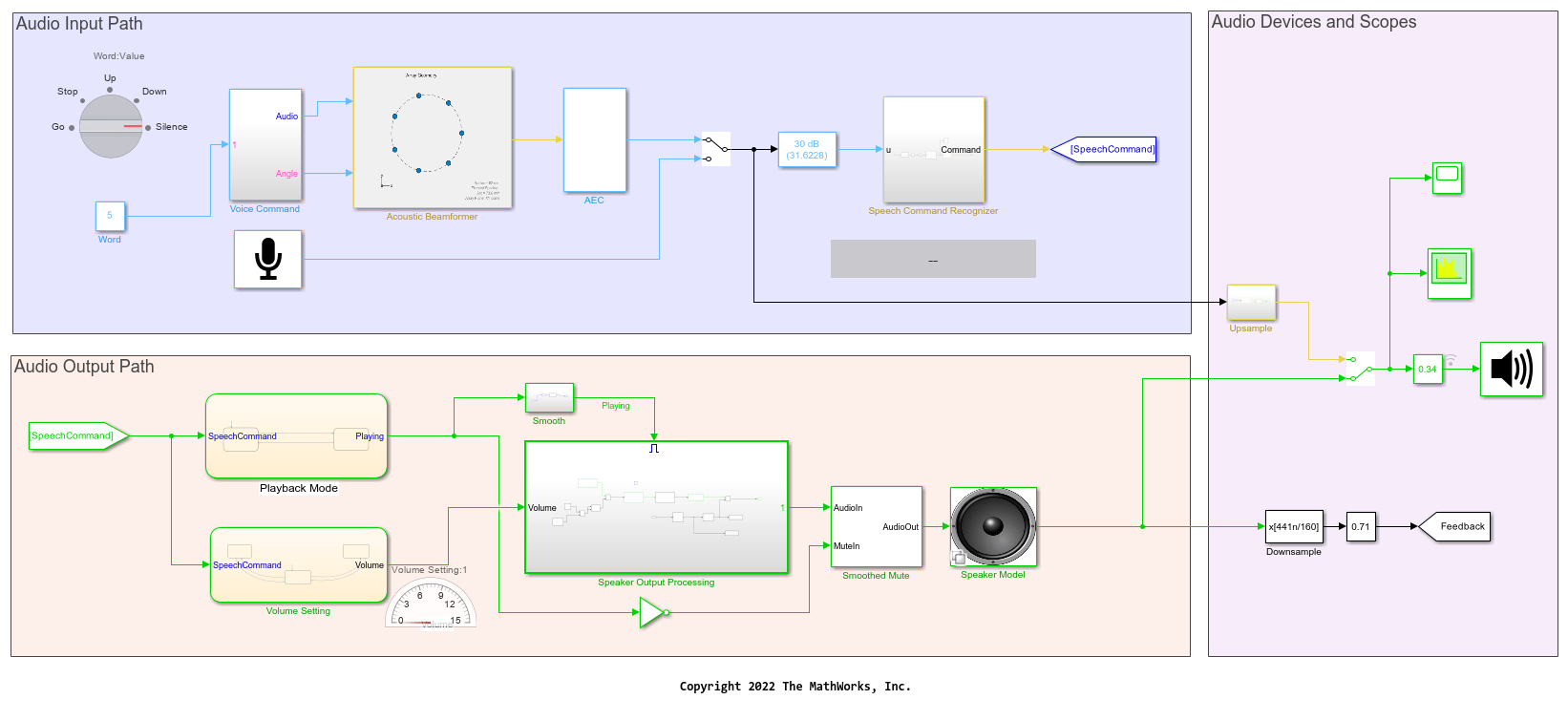
模型包括三个主要部分:
一个音频输入路径,代表麦克风预处理。
一个音频输出路径,代表扬声器输出处理。
音频设备和范围,包括组件监控音频和输出信号在时间和频率域的阴谋。
open_system (“audioSmartSpeaker”);
语音命令源
你可以把智能议长在两个方面:
您可以指定命令直接模式是贯穿一个麦克风。通过对话框设置麦克风音频设备的读者。
你也可以模拟信号的接收到一个麦克风阵列。在这种情况下,语音指令的来源是一组预录好的音频文件包含命令。
选择语音命令源通过手动切换开关在音频输入路径模型的部分。
声波束形成
你应用声波束形成模拟麦克风阵列。在这种情况下,您的模型三个来源的声音命令子系统(语音命令,加上两个背景噪音来源)。声Beamformer子系统处理不同的声音信号隔离,提高语音命令。
声学回波消除
当你发出命令,音乐响起,音乐是被麦克风回荡的房间后,创建一个不受欢迎的反馈效果。
声学回波消除(AEC)子系统从输入信号中删除播放音频通过使用归一化LMS自适应滤波器。这个组件只适用于当你使用声学模拟麦克风阵列波束形成。
可以包含或排除原子能委员会组件通过改变复选框的值在其面具对话框。
听到原子能委员会在输入音频信号的影响,抛在音频设备和手动开关作用域模型的部分。
语音命令识别
你通过预处理的演讲命令语音命令识别子系统。语音命令识别是基于pretrained深度学习卷积网络相同的一个使用深度学习训练语音命令识别模型的例子。
你提取听觉(树皮)谱图从输入音频,你喂pretrained网络。网络输出预测的命令。你使用这个命令来驱动模型的音频输出路径部分。
控制音频输出路径状态图表
解码语音命令进入两个不同的状态图:
第一个图表控制回放。音乐开始时支付收到命令,“走”和“停止”时停止播放。
第二个图表控制回放反应体积的命令“向上”和“向下”。
扬声器输出处理
当触发播放时,扬声器输出处理子系统启用。这个子系统包含块通常用于调整音频、图形情商等多波段参量均衡器和动态范围控制器(限幅器)。您可以优化您的系统声音的模式是通过打开这些块的面具对话框和改变参数的值(例如,图形情商的频率)。
平滑的
当音乐停止播放时,它突然消失顺利而不是停止。这是通过平滑静音块适用于音频信号的时变增益。这一块是基于SmoothedMute的系统对象。
演讲者建模
扬声器输出处理和平滑静音后,信号进入演讲者子系统模型。这个子系统允许您控制扬声器是如何建模:
你可以选择行为模型,实现了使用基本数学模型块议长模型(比如sum,延迟,积分器,并获得)。金宝app
你可以选择一个电路模型,实现演讲者使用SimScape组件模型。
你也可以绕过这些模型如果您使用的是一个真正的,物理扬声器听音频。
改变变量的值speakerMode基本工作空间中选择一个旁路(speakerMode = 0)、行为(speakerMode = 1),或电路(speakerMode = 2)。
音频设备和范围
模型使用一个频谱分析仪块情节音频信号在频域和时间范围可视化流时域音频。