用GPU编码器求解线性系统的基准测试
这个例子展示了如何通过生成CUDA®代码来对线性系统进行基准测试。用矩阵左除法,又称mldivide或者反斜杠运算符(\),来解线性方程组A*x = b为x(即计算x = A\b).
第三方的先决条件
要求
本例生成CUDA MEX,第三方需求如下。
CUDA支持NVIDIA®GPU和兼容的驱动程序。
可选
对于非mex构建,例如静态、动态库或可执行文件,此示例具有以下附加要求。
英伟达工具包。
编译器和库的环境变量。有关更多信息,请参见第三方硬件而且设置必备产品下载188bet金宝搏.
检查GPU环境
要验证运行此示例所需的编译器和库是否已正确设置,请使用coder.checkGpuInstall函数。
envCfg = code . gpuenvconfig (“主机”);envCfg。BasicCodegen = 1;envCfg。安静= 1;coder.checkGpuInstall (envCfg);
确定最大数据大小
通过指定CPU和GPU可用的系统内存量(单位为GB),为计算选择适当的矩阵大小。默认值仅基于GPU上可用的内存量。您可以指定一个适合您的系统的值。
g = gpuDevice;maxMemory = 0.1*g.AvailableMemory/1024^3;
注意:
本例使用cuSOLVER库,这些库在创建工作空间时需要大量的GPU内存。如果遇到CUDA内存不足错误,请减少maxMemory或者矩阵的步长sizeSingle而且sizeDouble.
基准测试功能
这个例子测试了矩阵左除法(\),包括CPU和GPU之间传输数据的成本,以获得使用GPU Coder™时应用程序的总时间的清晰视图。应用程序时间分析不能包括创建示例输入数据的时间。的genData.m函数将测试数据的生成与求解线性系统的入口点函数分开。
类型getData.m
函数[A, b] = getData(n, clz) %版权所有2017-2022 The MathWorks, Inc. fprintf('创建一个大小为%d-by-%d的矩阵。\n', n, n);A = rand(n, n, clz) + 100*eye(n, n, clz);B = rand(n, 1, clz);结束
反斜杠入口点函数
的backslash.m入口点函数封装了要为其生成代码的(\)操作。
类型backslash.m
function [x] = back斜线(A,b) %#codegen %版权所有The MathWorks, Inc. code .gpu.kernelfun();x = A\b;结束
生成GPU代码
创建一个函数,根据特定的输入数据大小生成GPU MEX函数。
类型genGpuCode.m
function [] = genGpuCode(A, b) %版权所有2017-2022 The MathWorks, Inc. cfg = code . gpuconfig ('mex');evalc('codegen -config cfg -args {A,b}反斜杠');结束
选择问题大小
求解线性系统的并行算法的性能在很大程度上取决于矩阵的大小。这个例子比较了不同矩阵大小(1024的倍数)时算法的性能。
sizeLimit = inf;如果ispc sizeLimit = double(intmax(“int32”));结束maxSizeSingle = min(地板(根号(maxMemory*1024^3/4)),地板(根号(sizeLimit/4)));maxSizeDouble = min(地板(根号(maxMemory*1024^3/8)),地板(根号(sizeLimit/8)));Step = 1024;如果maxsize ouble/step >= 10 step = step*floor(maxsize ouble/(5*step));结束size = 1024:step:maxSizeSingle;size = 1024:step: maxsize ouble;numReps = 5;
比较性能:加速
使用总运行时间作为性能度量,因为这使您能够比较不同矩阵大小的算法的性能。给定矩阵大小,基准测试函数创建矩阵一个右边是b一次,然后解一个\ b多做几次,以准确测量所需的时间。
类型benchFcnMat.m
The MathWorks, Inc. time = inf;多次求解线性系统,取itr = 1时的最佳值:reps tic;矩阵=反斜杠(A, b);Tcurr = toc;Time = min(tcurr, Time);结束结束
为GPU代码执行创建一个不同的函数,调用生成的GPU MEX函数。
类型benchFcnGpu.m
function time = benchFcnGpu(A, b, reps) %版权归The MathWorks, Inc.所有time = inf;gpuX = backslash_mex(A, b);对于itr = 1:代表tic;gpuX = backslash_mex(A, b);Tcurr = toc;Time = min(tcurr, Time);结束结束
执行基准测试
执行基准测试时,计算可能需要很长时间才能完成。在完成每个矩阵大小的基准测试时,打印一些中间状态信息。在函数中封装所有矩阵大小的循环,以基准单精度和双精度计算。
实际执行时间可能因不同的硬件配置而异。本基准测试是在具有6核3.5GHz Intel®Xeon®CPU和NVIDIA TITAN Xp GPU的机器上使用MATLAB R2022a完成的。
类型executeBenchmarks.m
function [timeCPU, timeGPU] = executebenchmark (clz, sizes, reps) %版权所有2017-2022 The MathWorks, Inc. fprintf(['以%d different %s-precision启动基准测试'…'大小\n的矩阵,范围从%d-by-%d到%d- %d。\ n '],……长度(尺寸),clz,尺寸(1),尺寸(1),尺寸(end),…大小(结束));timeGPU = 0(大小(大小));timeCPU = 0(大小(大小));对于I = 1:长度(大小)n =大小(I);fprintf('Size: %d\n', n);[A, b] = getData(n, clz);genGpuCode (A, b); timeCPU(i) = benchFcnMat(A, b, reps); fprintf('Time on CPU: %f sec\n', timeCPU(i)); timeGPU(i) = benchFcnGpu(A, b, reps); fprintf('Time on GPU: %f sec\n', timeGPU(i)); fprintf('\n'); end end
以单精度和双精度执行基准测试。
[cpu, gpu] = executebenchmark (“单一”, sizeSingle, numReps);
从9个大小从1024 × 1024到17408 × 17408不等的单精度矩阵开始基准测试。创建1024 * 1024的矩阵。CPU时间:0.012281秒GPU时间:0.008329秒大小:3072创建一个3072 × 3072的矩阵。CPU Time: 0.115839 sec GPU Time: 0.035071 sec Size: 5120创建大小为5120 * 5120的矩阵。CPU时间:0.380651秒GPU时间:0.074228秒大小:7168创建大小为7168 × 7168的矩阵。CPU时间:0.867239秒GPU时间:0.127977秒大小:9216创建大小为9216 × 9216的矩阵。CPU时间:1.677065秒GPU时间:0.205344秒大小:11264创建大小为11264 * 11264的矩阵。CPU时间:2.911081秒GPU时间:0.306867秒大小:13312创建大小为13312 * 13312的矩阵。CPU时间:4.684644秒GPU时间:0.440095秒大小:15360创建大小为15360 × 15360的矩阵。CPU时间:6.950956秒GPU时间:0.608897秒大小:17408创建一个大小为17408 * 17408的矩阵。 Time on CPU: 9.833478 sec Time on GPU: 0.802604 sec
结果。sizeSingle = sizeSingle;结果。timeSingleCPU = cpu;结果。timeSingleGPU = gpu;[cpu, gpu] = executebenchmark (“双”, size ouble, numReps);
从6个大小从1024 × 1024到11264 × 11264的不同双精度矩阵开始基准测试。创建1024 * 1024的矩阵。CPU时间:0.021463秒GPU时间:0.010796秒大小:3072创建一个3072 × 3072的矩阵。CPU时间:0.213805秒GPU时间:0.093114秒大小:5120创建大小为5120 × 5120的矩阵。CPU时间:0.689023 sec GPU时间:0.323026 sec大小:7168创建大小为7168 × 7168的矩阵。CPU时间:1.687437秒GPU时间:0.775834秒大小:9216创建9216 * 9216的矩阵。CPU Time: 3.521580 sec GPU Time: 1.539601 sec Size: 11264创建大小为11264 * 11264的矩阵。CPU时间:6.075310秒GPU时间:2.694465秒
结果。size ouble = size ouble;结果。timeDoubleCPU = cpu;结果。timeDoubleGPU = gpu;
绘制性能图
绘制结果并比较CPU和GPU上的单精度和双精度性能。
首先,看看反斜杠运算符的单精度性能。
图;Ax =轴(“父”图);情节(ax,结果。sizeSingle,结果。timeSingleGPU,“- x”,...结果。sizeSingle results.timeSingleCPU,“o”网格)在;传奇(“图形”,“CPU”,“位置”,“西北”);标题(ax,单精度性能的) ylabel (ax,“时间(s)”);包含(ax,矩阵大小的);

drawnow;
现在,看看反斜杠运算符在双精度下的性能。
图;Ax =轴(“父”图);情节(ax,结果。sizeDouble,结果。timeDoubleGPU,“- x”,...结果。sizeDouble results.timeDoubleCPU,“o”)传说(“图形”,“CPU”,“位置”,“西北”);网格在;标题(ax,“双精度性能”) ylabel (ax,“时间(s)”);包含(ax,矩阵大小的);drawnow;

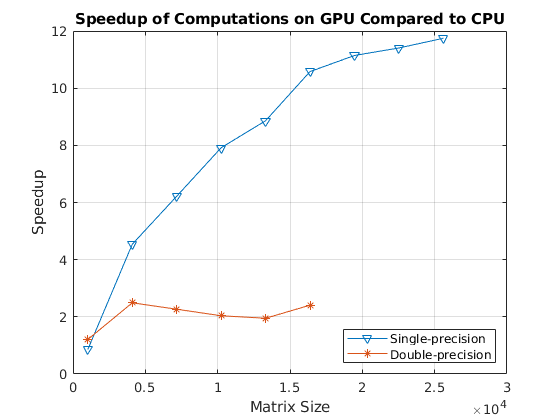
最后,在比较GPU和CPU时,看看反斜杠运算符的加速。
speedupDouble = results.timeDoubleCPU./results. timeddoubllegpu;speedupSingle = results.timeSingleCPU./results.timeSingleGPU;图;Ax =轴(“父”图);情节(ax,结果。sizeSingle,speedupSingle,“v”,...结果。sizeDouble speedupDouble,“- *”网格)在;传奇(单精度的,“双精度”,“位置”,“东南”);标题(ax,GPU运算速度比CPU更快);ylabel (ax,“加速”);包含(ax,矩阵大小的);drawnow;
另请参阅
功能
codegen|coder.gpu.kernel|coder.gpu.kernelfun|gpucoder.matrixMatrixKernel|coder.gpu.constantMemory|gpucoder.stencilKernel|coder.checkGpuInstall
对象
相关的话题
您也可以从以下列表中选择一个网站: