负载预定义金宝appEnvironments
钢筋学习工具箱™软件提供预定义的Simulink金宝app®在已经定义了操作,观察,奖励和动态的环境。您可以使用这些环境:
Learn reinforcement learning concepts.
Gain familiarity with Reinforcement Learning Toolbox software features.
测试自己的强化学习代理。
您可以使用以下方法加载以下预定义的Simulink环境金宝appRlpredefinedenv.功能。
| Environment | 代理任务 |
|---|---|
| Simple pendulum Simulink model | Swing up and balance a simple pendulum using either a discrete or continuous action space. |
| Cart-pole Simscape™ model | 通过使用离散或连续的动作空间将力施加到购物车上的移动电车上的平衡。 |
对于预定义的Simulink环金宝app境,环境动态,观察和奖励信号在相应的Simulink模型中定义。该Rlpredefinedenv.功能创建A.金宝appSimulinkenvwithagent.对象培养function uses to interact with the Simulink model.
Simple Pendulum金宝appModel
该环境是一个简单的无摩擦摆,最初悬挂在向下位置。培训目标是使摆锤直立,而不会使用最小的控制工作。此环境的模型是定义的R.lSimplePendulumModel金宝appSimulink模型。
open_system('rlSimplePendulumModel')

该R.e are two simple pendulum environment variants, which differ by the agent action space.
离散代理可以施加任何一个扭矩T.max那
0., 要么-T.max到摆锤,在哪里T.maxis theMax_tau.variable in the model workspace.连续代理可以在范围内施加任何扭矩[ -T.max那T.max].
要创建一个简单的摆动环境,请使用Rlpredefinedenv.功能。
离散的动作空间
Env = Rlpredefinedenv('SimpleDepulummodel-Collete');Continuous action space
Env = Rlpredefinedenv('SimpleDepulummodel连续');
例如,培训代理在简单的摆动环境中,请参阅:
Actions
In the simple pendulum environments, the agent interacts with the environment using a single action signal, the torque applied at the base of the pendulum. The environment contains a specification object for this action signal. For the environment with a:
离散的动作空间,规范是一个
rlfinitesetspec.object.Continuous action space, the specification is an
R.lNumericSpecobject.
有关从环境中获取动作规范的详细信息,请参阅getActionInfo。
观察
在简单的摆动环境中,代理接收以下三个观察信号,该信号在其中构建create observationssubsystem.
摆角的正弦角
摆锤角度的余弦
摆角的衍生物
对于每个观察信号,环境包含一个R.lNumericSpec观察规范。所有观察结果都是连续和无界的。
For more information on obtaining observation specifications from an environment, seegetObservationInfo。
奖励
该R.eward signal for this environment, which is constructed in the计算专家ate reward子系统,是
这里:
θT.is the pendulum angle of displacement from the upright position.
是摆角的衍生物。
你T.-1是前一步的控制力。
Cart-PoleSimscapeModel
预定推出的推车环境中的代理的目标是通过将水平力应用于推车来平衡移动推车上的杆。如果满足以下两个条件,则杆被认为成功平衡:
极角保持在垂直位置的给定阈值内,其中垂直位置是零弧度。
推车位置的大小保持在给定阈值以下。
此环境的模型是定义的rlcartpolesimscapemodel.金宝appSimulink模型。使用此模型的动态定义Simscape Multibody™。
open_system('rlCartPoleSimscapeModel')
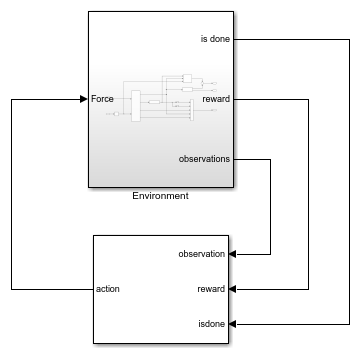
In theEnvironmentsubsystem, the model dynamics are defined using Simscape components and the reward and observation are constructed using Simulink blocks.
open_system('rlcartpolesimscapemodel /环境')

有两个推车杆环境变体,由代理动作空间不同。
离散 - 代理可以施加力量
15.那0., 要么-15T.o the cart.Continuous — Agent can apply any force within the range [
-15那15.].
要创建购物车环境,请使用Rlpredefinedenv.功能。
离散的动作空间
Env = Rlpredefinedenv('CartPoleSimscapeModel-Discrete');Continuous action space
Env = Rlpredefinedenv('CartPoleSimscapeModel-Continuous');
有关在此卡车环境中培训代理的示例,请参阅火车DDPG代理摇摆和平衡车杆系统。
Actions
在推车杆环境中,代理使用单个动作信号与环境交互,施加到推车的力。环境包含此动作信号的规范对象。对于环境的环境:
离散的动作空间,规范是一个
rlfinitesetspec.object.Continuous action space, the specification is an
R.lNumericSpecobject.
有关从环境中获取动作规范的详细信息,请参阅getActionInfo。
观察
In the cart-pole environment, the agent receives the following five observation signals.
杆角度的正弦
极点角度的余弦
摆角的衍生物
购物车位置
推车位置的衍生物
对于每个观察信号,环境包含一个R.lNumericSpec观察规范。所有观察结果都是连续和无界的。
For more information on obtaining observation specifications from an environment, seegetObservationInfo。
奖励
该R.eward signal for this environment is the sum of three components (R.=R.QR.+R.N+R.P.):
一种二次调节器控制奖励,构建在
Environment/qr rewardsubsystem.An additional reward for when the pole is near the upright position, constructed in the
Environment/near upright rewardsubsystem.购物车限制罚款,建造在
Environment/x limit penaltysubsystem. This subsystem generates a negative reward when the magnitude of the cart position exceeds a given threshold.
这里:
Xis the cart position.
θ是从直立位置的位移的极点角度。
你T.-1是前一步的控制力。
也可以看看
Blocks
职能
Related Topics
You can also select a web site from the following list:
Americas
- América Latina(Español)
- Canada(English)
- United States(English)
Europe
- 荷兰(English)
- Norway(English)
- Österreich.(Deutsch)
- 葡萄牙(English)
- 瑞典(English)
- Switzerland<你l class="list-unstyled add_indent_20">
- Deutsch
- English
- Français.
