火车AC代理以平衡车杆系统Using Parallel Computing
此示例显示如何培训演员 - 评论家(AC)代理以平衡通过异步并行培训在Matlab®中建模的购物车系统。有关在不使用并行培训的情况下展示如何训练代理的示例,请参阅火车AC代理以平衡车杆系统。
演员并行培训
When you use parallel computing with AC agents, each worker generates experiences from its copy of the agent and the environment. After everyN步骤,工作者从体验中计算渐变,并将计算的渐变返回给主机代理。主机代理如下更新其参数。
对于异步训练,主机代理应用所接收的渐变,而无需等待所有工人发送渐变,并将更新的参数发送回提供渐变的工作人员。然后,工人继续使用更新的参数从其环境生成经验。
对于同步培训,主机代理等待接收来自所有工人的渐变并使用这些渐变更新其参数。然后,主机同时向所有工人发送更新的参数。然后,所有工人继续使用更新的参数生成经验。
Create Cart-Pole MATLAB Environment Interface
Create a predefined environment interface for the cart-pole system. For more information on this environment, seeLoad Predefined Control System Environments。
env = rlPredefinedEnv(“cartpole - 离散”); env.PenaltyForFalling = -10;
从环境界面获取观察和动作信息。
obsInfo = getObservationInfo(env); numObservations = obsInfo.Dimension(1); actInfo = getActionInfo(env);
修复随机发生器种子以进行再现性。
rng(0)
Create AC Agent
AC代理使用批评价值函数表示来估计长期奖励,给定观察和行动。要创建评论家,首先创建一个具有一个输入(观察)和一个输出(状态值)的深神经网络。批评网络的输入大小为4,因为环境提供4个观察。有关创建深度神经网络值函数表示的更多信息,请参阅Create Policy and Value Function Representations。
criticNetwork = [ featureInputLayer(4,'Normalization','none','Name','州') fullyConnectedLayer(32,'Name','批评福尔福克') reluLayer('Name','rictrelu1') fullyConnectedLayer(1,'Name','CriticFC')];批评= rlrepresentationOptions('LearnRate',1e-2,'GradientThreshold',1);评论家= rlvalueerepresentation(批判性,Obsinfo,'Observation',{'州'},批评);
An AC agent decides which action to take, given observations, using an actor representation. To create the actor, create a deep neural network with one input (the observation) and one output (the action). The output size of the actor network is 2 since the agent can apply 2 force values to the environment, –10 and 10.
ActorNetWork = [FeatureInputLayer(4,'Normalization','none','Name','州') fullyConnectedLayer(32,'Name','ActorStateFC1') reluLayer('Name','ACTORRELU1') fullyConnectedLayer(2,'Name','action')];actorOpts = rlRepresentationOptions('LearnRate',1e-2,'GradientThreshold',1);Actor = rlstochastOrtorrepresentation(Actornetwork,Obsinfo,Actinfo,。。。'Observation',{'州'},actorOpts);
To create the AC agent, first specify the AC agent options usingrlacagentoptions.。
agentOpts = rlACAgentOptions(。。。'numstepstolookahead',32,。。。'EntropyLossWeight',0.01,。。。'贴花因子',0.99);
Then create the agent using the specified actor representation and agent options. For more information, seerlACAgent。
agent = rlACAgent(actor,critic,agentOpts);
Parallel Training Options
要培训代理,首先指定培训选项。对于此示例,请使用以下选项。
最多运行每个培训
1000episodes, with each episode lasting at most500time steps.Display the training progress in the Episode Manager dialog box (set the
Plotsoption) and disable the command line display (set theverboption).当代理收到平均累积奖励时停止培训大于
500over10consecutive episodes. At this point, the agent can balance the pendulum in the upright position.
trainOpts = rlTrainingOptions(。。。'maxepisodes',1000,。。。'maxstepperepisode',500,。。。'Verbose',假,。。。“阴谋”,'training-progress',。。。'StopTrainingCriteria','AverageReward',。。。'stoptriningvalue',500,。。。'ScoreAveragingWindowLength',10);
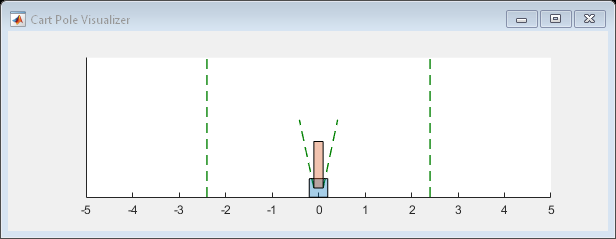
您可以在训练或模拟期间可视化车杆系统可以使用plot功能。
情节(env)
To train the agent using parallel computing, specify the following training options.
Set the
UseParallel选择真正。Train the agent in parallel asynchronously by setting the
parallelizationOptions.mode.选择“异步”。经过每32个步骤后,每个工人计算来自体验的渐变并将它们发送到主机。
AC代理需要workers to send "
gradients"to the host.AC代理需要
'stpeptuntildataissent'to be equal toagentOptions.NumStepsToLookAhead。
训练.Useplate = true;训练.ParlellelizationOptions.Mode =.“异步”;训练.ParlellizationOptions.datatosendfromworkers =“渐变”;训练.ParlellelizationOptions.stepsuntataissent = 32;
有关更多信息,请参阅rltringOptions.。
Train Agent
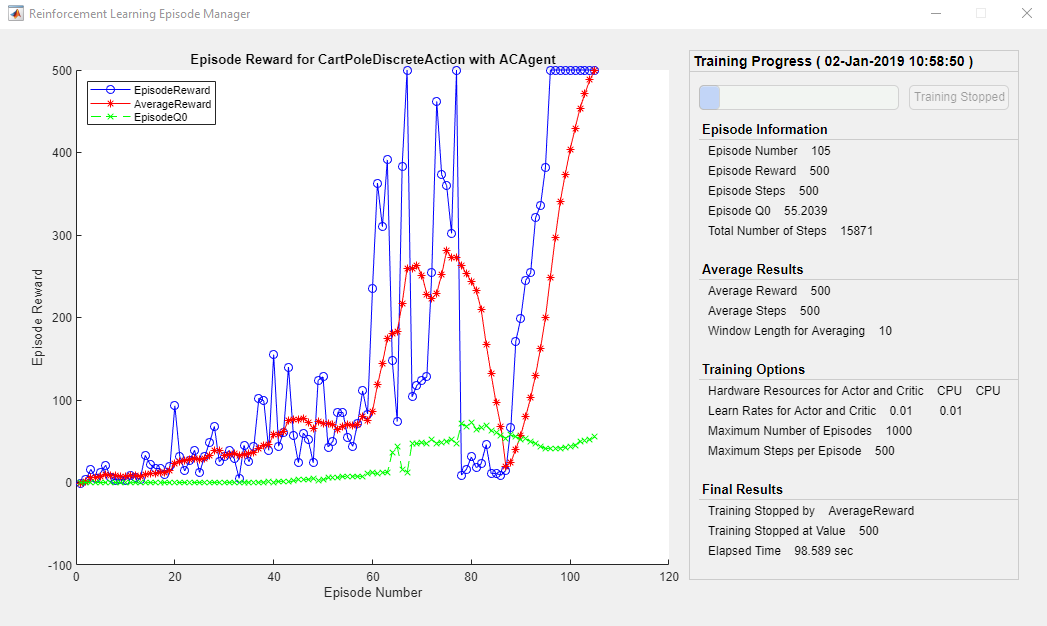
使用该代理商培训train功能。培训代理是一个计算密集的进程,需要几分钟才能完成。要在运行此示例的同时节省时间,请通过设置加载预制代理doTrainingtofalse。训练代理人,套装doTrainingto真正。Due to randomness in the asynchronous parallel training, you can expect different training results from the following training plot. The plot shows the result of training with six workers.
dotraining = false;ifdoTraining% Train the agent.trainingStats = train(agent,env,trainOpts);else% Load the pretrained agent for the example.load('MATLABCartpoleParAC.mat','agent');end
模拟AC代理
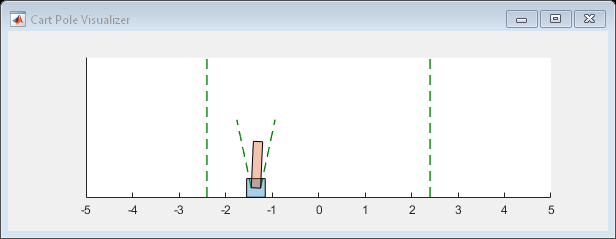
在仿真期间,您可以使用绘图功能可视化Cart-杆系统。
情节(env)
To validate the performance of the trained agent, simulate it within the cart-pole environment. For more information on agent simulation, seeRlsimulationOptions.和sim。
simoptions = rlsimulation选项('maxsteps',500); experience = sim(env,agent,simOptions);
totalReward = sum(experience.Reward)
TotalReward = 500.
参考资料
[1] Mnih,Volodymyr,AdriàPuigdomènechBadia,Mehdi Mirza,Alex Graves,Timothy P. Lillicrap,Tim Harley,David Silver和Koray Kavukcuoglu。'深度加强学习的异步方法'。ArXiv:1602.01783 [Cs], 16 June 2016.https://arxiv.org/abs/1602.01783。
See Also
相关话题
选择一个网站
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select:。
Selectweb site您还可以从以下列表中选择一个网站:
欧洲
- Belgium(English)
- 丹麦(English)
- Deutschland(德意志)
- España.(Español)
- Finland(English)
- 法国(Français)
- 爱尔兰(English)
- 意大利(Italiano)
- Luxembourg(English)
- Netherlands(English)
- 挪威(English)
- Österreich(德意志)
- Portugal(English)
- Sweden(English)
- 瑞士
- 英国(English)
