使用深度学习的序列分类
这个例子展示了如何使用长短期记忆(LSTM)网络对序列数据进行分类。
要训练深度神经网络对序列数据进行分类,可以使用LSTM网络。LSTM网络使您能够将序列数据输入到网络中,并根据序列数据的各个时间步长进行预测。
本例使用[1]和[2]中描述的日语元音数据集。这个例子训练一个LSTM网络来识别给定时间序列数据的说话者,这些数据代表连续说出的两个日语元音。训练数据包含9位演讲者的时间序列数据。每个序列有12个特征,长度不同。数据集包含270个训练观测值和370个测试观测值。
负载顺序数据
加载日语元音训练数据。XTrain是一个单元格数组,包含270个尺寸为12且长度不等的序列。Y是标签“1”,“2”,…的分类向量。,“9”,对应九个说话人。中的项XTrain是具有12行(每个特征一行)和不同列数(每个时间步一列)的矩阵。
[XTrain,YTrain] = japevowelstraindata;XTrain (1:5)
ans =5×1单元阵列{12×20 double} {12×26 double} {12×22 double} {12×20 double} {12×21 double}
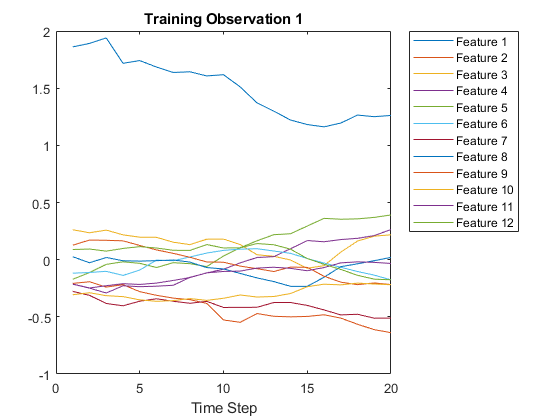
想象一个图中的第一个时间序列。每条线对应一个特征。
图plot(XTrain{1}') xlabel(“时间步”)标题(“训练观察1”) numFeatures = size(XTrain{1},1);传奇(“特性”+字符串(1:numFeatures),“位置”,“northeastoutside”)
准备填充数据
在训练过程中,默认情况下,软件将训练数据分成小批,并填充序列,使它们具有相同的长度。过多的填充会对网络性能产生负面影响。
为了防止训练过程中添加过多的填充,您可以按序列长度对训练数据进行排序,并选择一个小批量大小,以便小批量中的序列具有相似的长度。下图显示了在排序数据之前和之后填充序列的效果。

获取每个观测值的序列长度。
numObservations = numel(XTrain);为i=1:numObservations sequence = XTrain{i};sequenceLengths(i) = size(sequence,2);结束
按序列长度对数据排序。
[sequenceLengths,idx] = sort(sequenceLengths);XTrain = XTrain(idx);YTrain = YTrain(idx);
在条形图中查看排序后的序列长度。
图条(sequenceLengths) ylim([0 30]) xlabel(“序列”) ylabel (“长度”)标题(“排序数据”)

选择27的mini-batch大小来平均划分训练数据,并减少mini-batch中的填充量。下图说明了添加到序列中的填充。
miniBatchSize = 27;

定义LSTM网络架构
定义LSTM网络体系结构。将输入大小指定为大小为12的序列(输入数据的维度)。指定一个包含100个隐藏单元的双向LSTM层,并输出序列的最后一个元素。最后,通过包括大小为9的完全连接层、softmax层和分类层来指定9个类。
如果在预测时可以访问完整序列,那么可以在网络中使用双向LSTM层。双向LSTM层从每个时间步长的完整序列中学习。如果您在预测时无法访问完整的序列,例如,如果您正在预测值或一次预测一个时间步长,则使用LSTM层代替。
inputSize = 12;numHiddenUnits = 100;numClasses = 9;图层= […sequenceInputLayer inputSize bilstmLayer (numHiddenUnits,“OutputMode”,“最后一次”) fulllyconnectedlayer (numClasses) softmaxLayer分类层
layers = 5×1层阵列层:1“序列输入序列输入12维2”BiLSTM BiLSTM有100个隐藏单元3“全连接9全连接层4“Softmax Softmax 5”分类输出crossentropyex
现在,指定培训选项。指定要使用的解算器“亚当”,梯度阈值为1,最大epoch数为100。要减少小批量中的填充量,请选择小批量大小为27。要填充数据,使其具有与最长序列相同的长度,请指定要设置的序列长度“最长”。要确保数据保持按序列长度排序,请指定不打乱数据。
由于小批量是小序列,训练更适合于CPU。指定“ExecutionEnvironment”是“cpu”。在GPU上训练,如果可用,设置“ExecutionEnvironment”来“汽车”(这是默认值)。
maxEpochs = 100;miniBatchSize = 27;选项= trainingOptions(“亚当”,…“ExecutionEnvironment”,“cpu”,…“GradientThreshold”, 1…“MaxEpochs”maxEpochs,…“MiniBatchSize”miniBatchSize,…“SequenceLength”,“最长”,…“洗牌”,“永远”,…“详细”0,…“阴谋”,“训练进步”);
训练LSTM网络
使用指定的训练选项训练LSTM网络trainNetwork。
net = trainNetwork(XTrain,YTrain,layers,options);

测试LSTM网络
加载测试集并将序列分类到扬声器中。
加载日语元音测试数据。XTest是一个单元格数组,包含370个尺寸为12且长度不等的序列。欧美是标签“1”,“2”,…的分类向量。“9”,对应九个说话人。
[XTest,YTest] = japevowelstestdata;XTest (1:3)
ans =3×1单元阵列{12×19 double} {12×17 double} {12×19 double}
LSTM网络网使用相似长度的小批量序列进行训练。确保以相同的方式组织测试数据。按序列长度对测试数据进行排序。
numObservationsTest = numel(XTest);为1:numObservationsTest序列= XTest{i};sequenceLengthsTest(i) = size(sequence,2);结束[sequenceLengthsTest,idx] = sort(sequenceLengthsTest);XTest = XTest(idx);YTest = YTest(idx);
对测试数据进行分类。为了减少分类过程引入的填充量,将mini-batch大小设置为27。要应用与训练数据相同的填充,请指定序列长度为“最长”。
miniBatchSize = 27;YPred =分类(net,XTest,…“MiniBatchSize”miniBatchSize,…“SequenceLength”,“最长”);
计算预测的分类精度。
acc = sum(YPred == YTest)./ nummel (YTest)
Acc = 0.9730
参考文献
[10]工藤,富山,新波。“使用穿越区域的多维曲线分类。”模式识别信。第20卷,第11-13期,1103-1111页。
[2]UCI机器学习库:日语元音数据集。https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
另请参阅
bilstmLayer|lstmLayer|sequenceInputLayer|trainingOptions|trainNetwork