估计的PK参数多个人
这个例子展示了如何估计范畴特定(如年轻人和老年人,男性和女性),细化和全民参数使用PK从多个个人配置文件数据。
背景
假设你有药物血浆浓度数据从30个人和想估算药动学参数,即中央和周边室的体积,间隙,intercompartmental间隙。假定药物浓度和时间剖面遵循biexponential下降 ,在那里 是药物浓度在时间t, 和 山坡上的相应指数下降。
加载数据
这个合成数据包含时间的等离子体浓度的丸剂量(100毫克)后30个人在不同的时间测量中央和周边隔间。它还包含分类变量,即性和年龄。
明确负载(“sd5_302RAgeSex.mat”)
groupedData格式转换
将数据集转换成groupedData对象,它是拟合函数所需的数据格式sbiofit。一个groupedData对象还允许您设置独立变量和组织变量名(如果存在的话)。设置的单位ID,时间,CentralConc,PeripheralConc,年龄,性变量。单位是可选的,只有所需的UnitConversion功能,该功能会自动匹配的物理量转换为一个一致的单位系统。
gData = groupedData(数据);gData.Properties。VariableUnits = {”,“小时”,毫克/升的,毫克/升的,”,”};gData.Properties
ans =结构体字段:描述:“用户数据:[]DimensionNames:{“行”“变量”}VariableNames: {1} x6细胞VariableDescriptions: {} VariableUnits: {1} x6细胞VariableContinuity: [] RowNames: {} CustomProperties: [1 x1 matlab.tabular。CustomProperties] GroupVariableName:“ID”IndependentVariableName:“时间”
的IndependentVariableName和GroupVariableName被自动设置为属性时间和ID变量的数据。
可视化数据
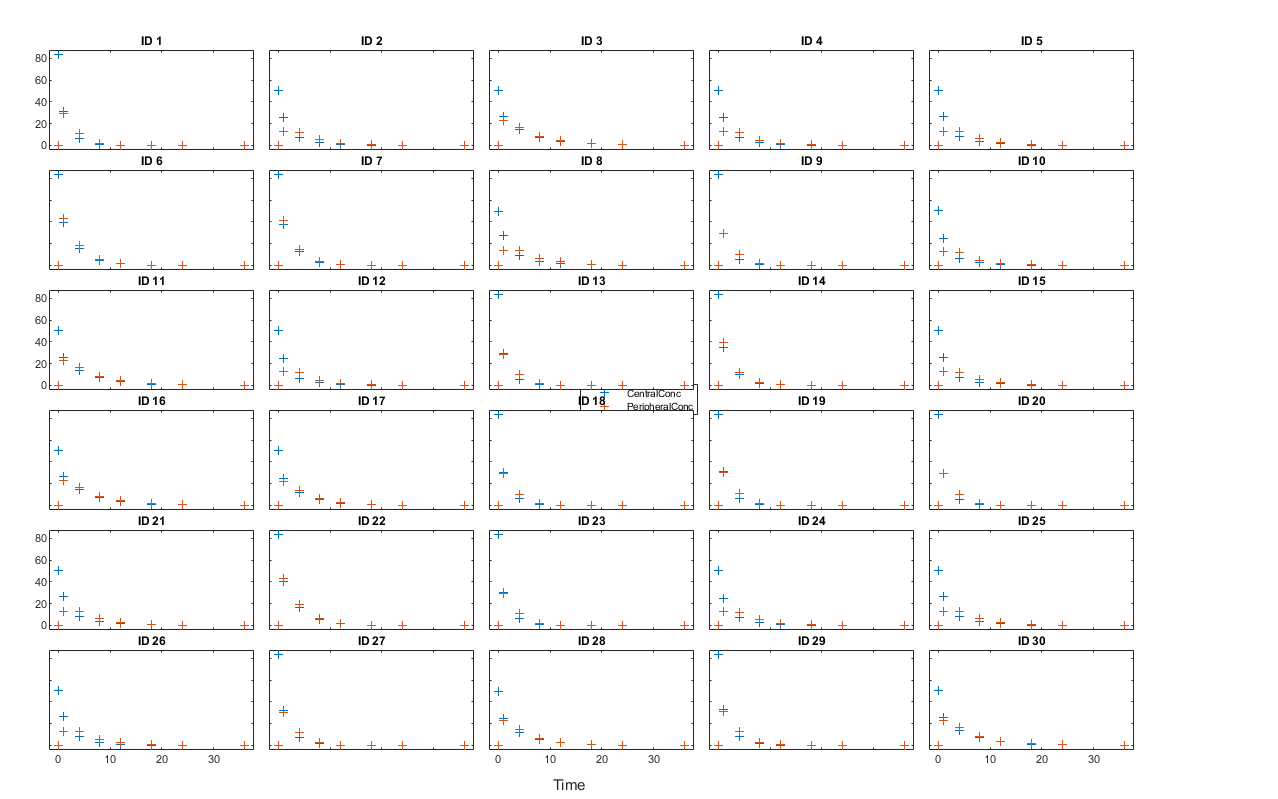
显示响应数据为每个单独的。
t = sbiotrellis (gData“ID”,“时间”,{“CentralConc”,“PeripheralConc”},…“标记”,“+”,“线型”,“没有”);%调整图。t.hFig.Position (:) = (100 100 1280 800);
建立一个两舱制模式
使用内置的PK库来构建一个两舱制模型与注入剂量和一阶消除消除速率取决于间隙和中央室的体积。使用configset对象单位转换。
pkmd = PKModelDesign;pkc1 = addCompartment (pkmd,“中央”);pkc1。DosingType =“丸”;pkc1。EliminationType =“linear-clearance”;pkc1。HasResponseVariable = true;pkc2 = addCompartment (pkmd,“外围”);模型=构造(pkmd);configset = getconfigset(模型);configset.CompileOptions。UnitConversion = true;
有关创建区划的PK模型使用SimBiology®内置库,明白了创建药代动力学模型。
定义剂量
假设每个人收到丸剂量100毫克的时间= 0。设置不同的给药策略的细节,请参阅剂量SimBiology模型。
剂量= sbiodose (“剂量”,“TargetName”,“Drug_Central”);剂量。开始时间= 0;剂量。一个mount = 100; dose.AmountUnits =毫克的;剂量。时间Units =“小时”;
响应数据映射到相应的模型组件
数据包含测量血浆浓度在中央和周边箱内。这些变量映射到适当的模型组件,Drug_Central和Drug_Peripheral。
responseMap = {“Drug_Central = CentralConc”,“Drug_Peripheral = PeripheralConc”};
指定的参数估计
指定的中央和周边隔间中央和外围,intercompartmental间隙12个和清关Cl_Central作为参数估计。的estimatedInfo对象允许您选择指定参数变换,初始值和参数范围。因为两个中央和外围限制是积极的,为每个参数指定一个log-transform。
paramsToEstimate = {“日志(中央)”,的日志(外围),“12”,“Cl_Central”};estimatedParam = estimatedInfo (paramsToEstimate,“InitialValue”[1 1 1 1]);
细化参数估计
估计为每个单独的一组参数设置“池”名称-值对参数假。
unpooledFit = sbiofit(模型、gData responseMap estimatedParam,剂量,“池”、假);
显示结果
画出拟合结果与原始数据为每个单独的(集团)。
情节(unpooledFit);
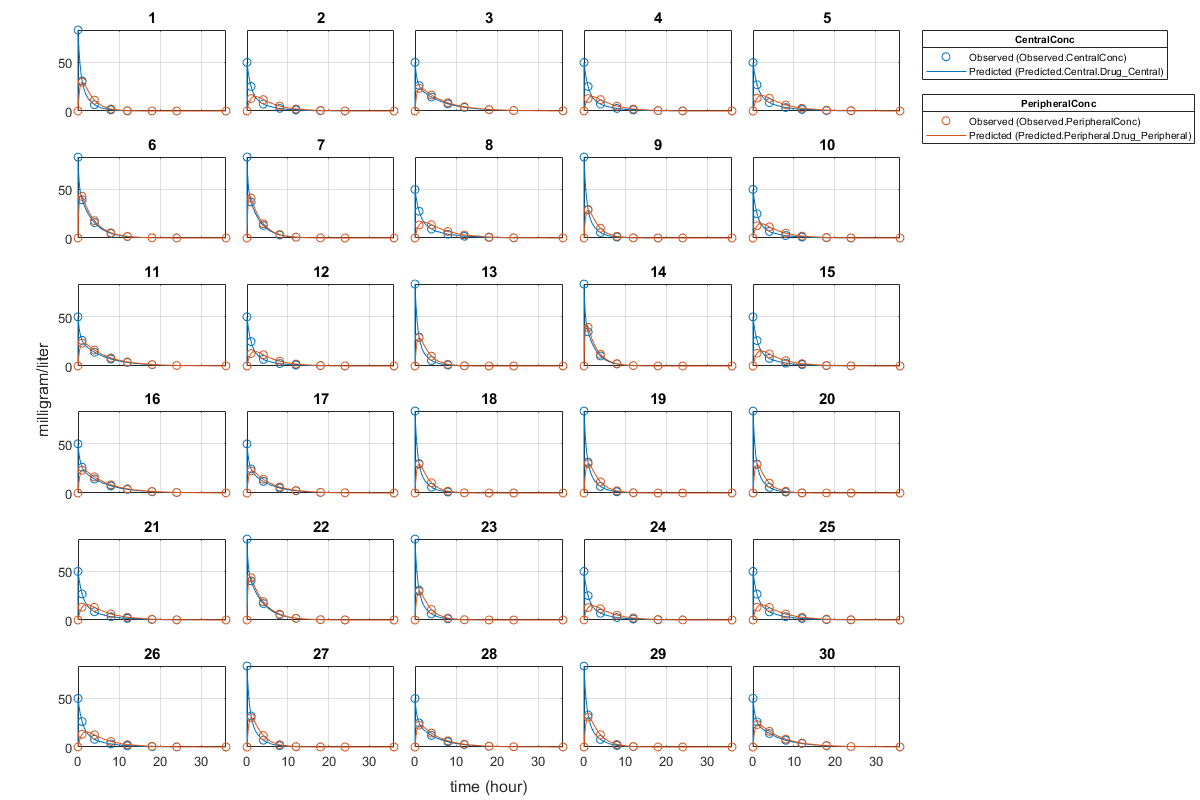
对于一个未共享健康,sbiofit总是返回一个对象为每个单独的结果。
检查参数估计类依赖关系
探索未共享是否有任何的参数估计,也就是说,如果一些参数相关的一个或多个类别。如果有任何类别的依赖性,它可能减少自由度的数量,通过估计这些参数的值。
首先提取和类别ID值为每个ID
catParamValues =独特(gData (: {“ID”,“性”,“年龄”}));
将变量添加到表包含每个参数的估计。
allParamValues = vertcat (unpooledFit.ParameterEstimates);catParamValues。中央=一个llParamValues.Estimate(strcmp(allParamValues.Name,“中央”));catParamValues。外围=一个llParamValues.Estimate(strcmp(allParamValues.Name,“外围”));catParamValues。12个=一个llParamValues.Estimate(strcmp(allParamValues.Name,“12”));catParamValues。Cl_Central=一个llParamValues.Estimate(strcmp(allParamValues.Name,“Cl_Central”));
为每个类别阴谋每个参数的估计。gscatter需要统计和机器学习的工具箱™。如果你没有它,使用其他替代绘图等功能情节。
h =图;ylabels = [“中央”,“边缘”,“12”,“Cl \ _Central”];plotNumber = 1;为我= 1:4 thisParam = estimatedParam(我). name;%的阴谋性范畴次要情节(4 2 plotNumber);plotNumber = plotNumber + 1;gscatter(双(catParamValues.Sex), catParamValues。(thisParam) catParamValues.Sex);甘氨胆酸ax =;斧子。XTick = [];ylabel (ylabels (i));传奇(“位置”,“bestoutside”)%的阴谋年龄类别次要情节(4 2 plotNumber);plotNumber = plotNumber + 1;gscatter(双(catParamValues.Age), catParamValues。(thisParam) catParamValues.Age);甘氨胆酸ax =;斧子。XTick = [];ylabel (ylabels (i));传奇(“位置”,“bestoutside”)结束%调整图。h.Position (:) = (100 100 1280 800);
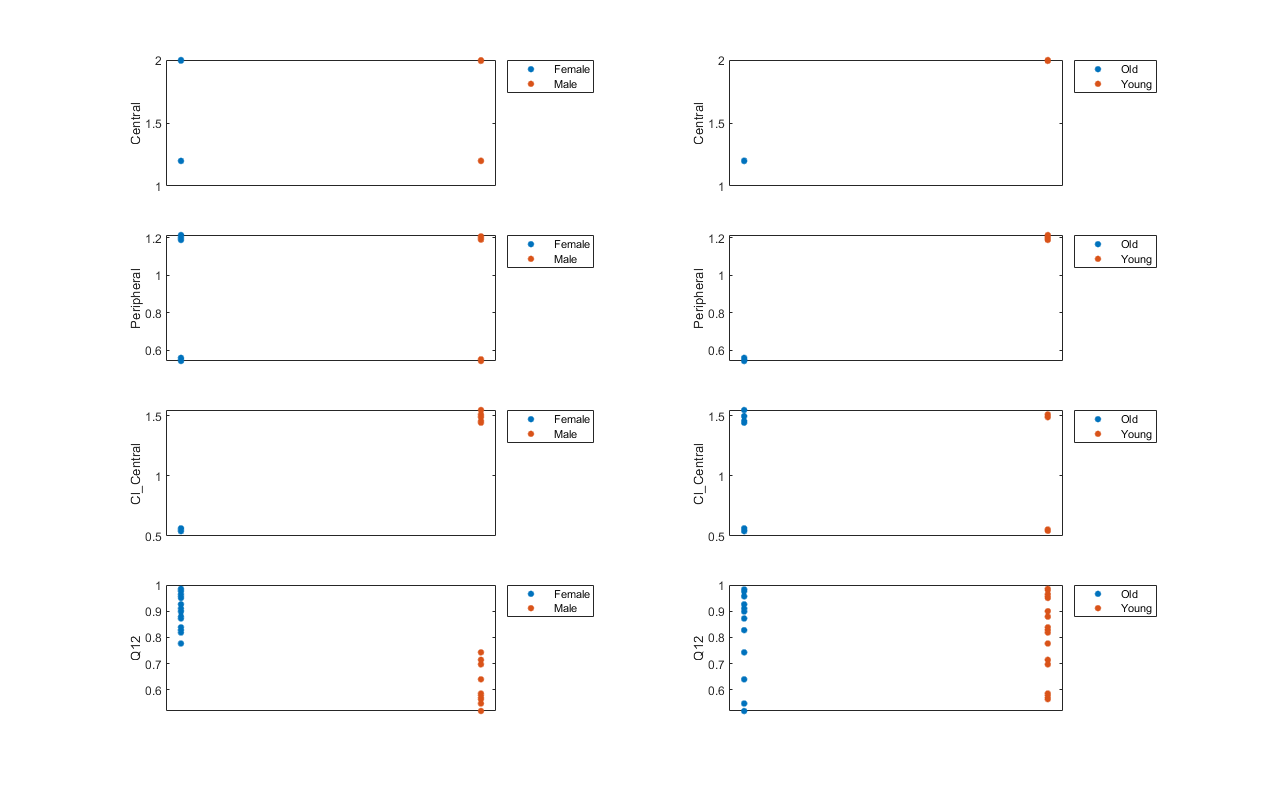
根据情节,似乎年轻个体倾向于有更高的中央和周边隔间(中央,外围比旧的个人(即卷似乎不同年龄组)。此外,男性较低间隙率(Cl_Central为12个参数)比女性但相反的(也就是说,间隙和Q12似乎性别)。
估计的参数
使用“CategoryVariableName”财产的estimatedInfo在拟合对象指定使用哪个类别。使用“性”集团为间隙配合Cl_Central和12个参数。使用“年龄”随着集团适合中央和外围参数。
estimatedParam (1)。C一个tegoryVariableName =“年龄”;estimatedParam (2)。C一个tegoryVariableName =“年龄”;estimatedParam (3)。C一个tegoryVariableName =“性”;estimatedParam (4)。C一个tegoryVariableName =“性”;categoryFit = sbiofit(模型、gData responseMap estimatedParam,剂量)
categoryFit = OptimResults属性:ExitFlag: 3输出:[1 x1 struct] GroupName:[]β:[8 x5表]ParameterEstimates: [120 x6表]:[240 x8x2双]COVB:[8×8双]CovarianceMatrix:[8×8双]R: [240 x2双]MSE: 0.4362上交所:205.8690重量:[]LogLikelihood: -477.9195 AIC: 971.8390 BIC: 1.0052 e + 03 DFE: 472 DependentFiles: {1} x3细胞EstimatedParameterNames:{“中央”“外围”“12”的Cl_Central} ErrorModelInfo: [1 x3表]EstimationFunction:“lsqnonlin”
当配件按类别(或一组),sbiofit总是返回一个结果对象,而不是一个为每个类别的水平。这是因为雄性和雌性个体被认为是部分相同的优化使用相同的误差模型和误差参数,同样的年轻和年老的人。
阴谋的结果
情节的估计结果。
情节(categoryFit);
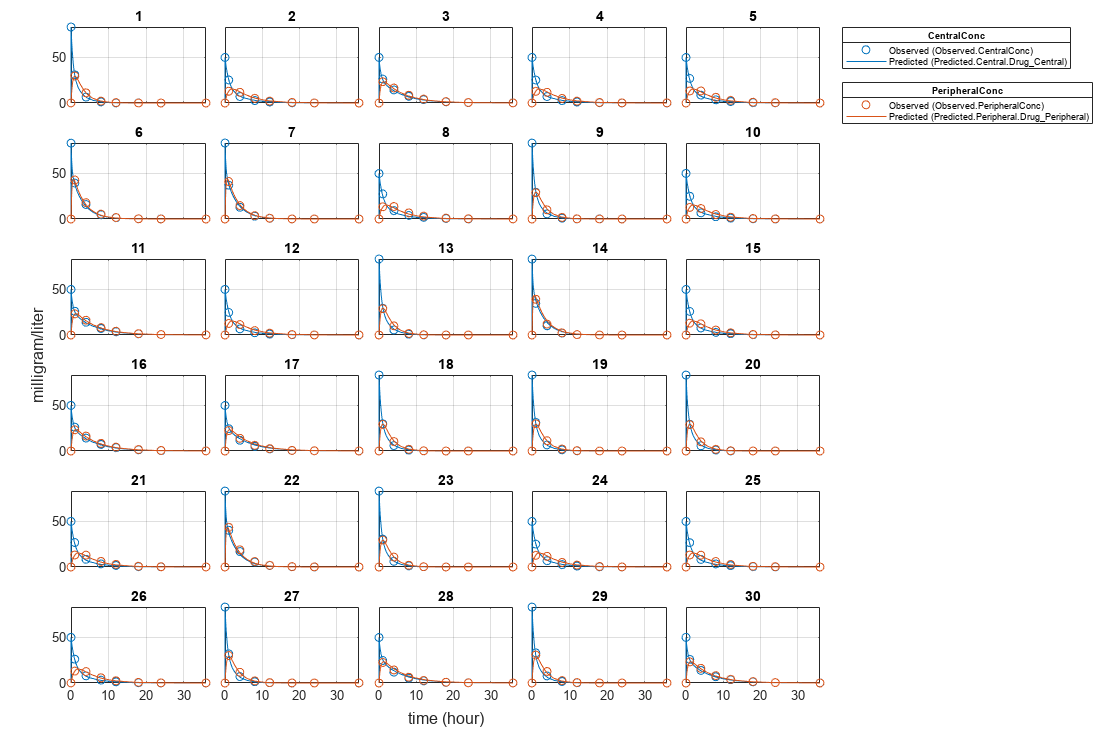
为Cl_Central和12个参数,所有男性有相同的估计,和类似的女性。为中央和外围参数,所有年轻的个人有相同的估计,和同样的人。
全民参数估计
为了更好的比较结果,符合模型的所有数据汇集在一起,也就是说,估计参数的一组个人通过设置“池”名称-值对参数真正的。警告消息告诉你,这个选项会忽略任何范畴特定信息(如果存在的话)。
pooledFit = sbiofit(模型、gData responseMap estimatedParam,剂量,“池”,真正的);
警告:CategoryVariableName estimatedInfo对象的属性使用“汇集”选项时将被忽略。
阴谋的结果
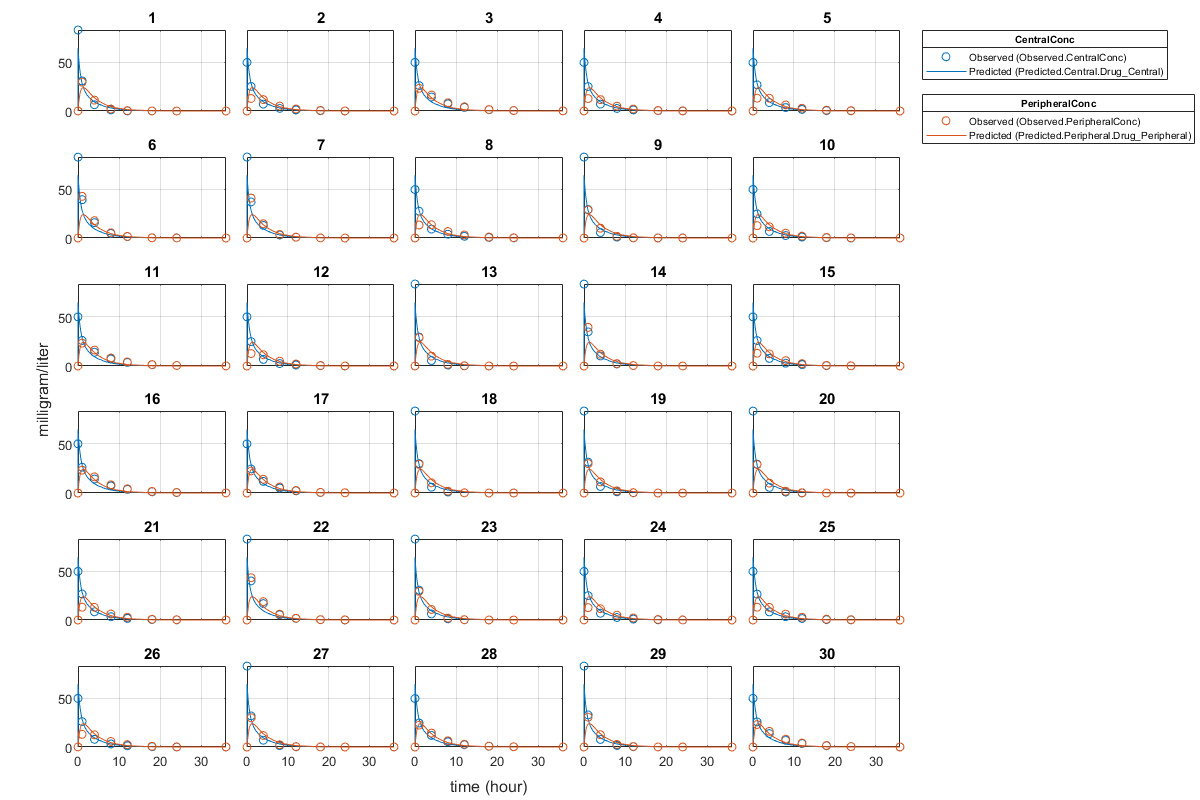
拟合结果与原始数据的阴谋。虽然单独的情节是为每个生成,数据拟合使用同一组参数(也就是说,所有人有同样的安装线)。
情节(pooledFit);
比较残差
比较残差的CentralConc和PeripheralConc为每一个合适的反应。
t = gData.Time;allResid (:,: 1) = pooledFit.R;allResid (:: 2) = categoryFit.R;allResid (:: 3) = vertcat (unpooledFit.R);h =图;responseList = {“CentralConc”,“PeripheralConc”};为i = 1:2次要情节(2,1,我);oneResid =挤压(allResid(:,我,:));情节(t, oneResid“o”);refline (0,0);%的参考线代表零残留标题(sprintf (“残差(% s)”我,responseList {}));包含(“时间”);ylabel (“残差”);传奇({“池”,“的”,未共享的});结束%调整图。h.Position (:) = (100 100 1280 800);
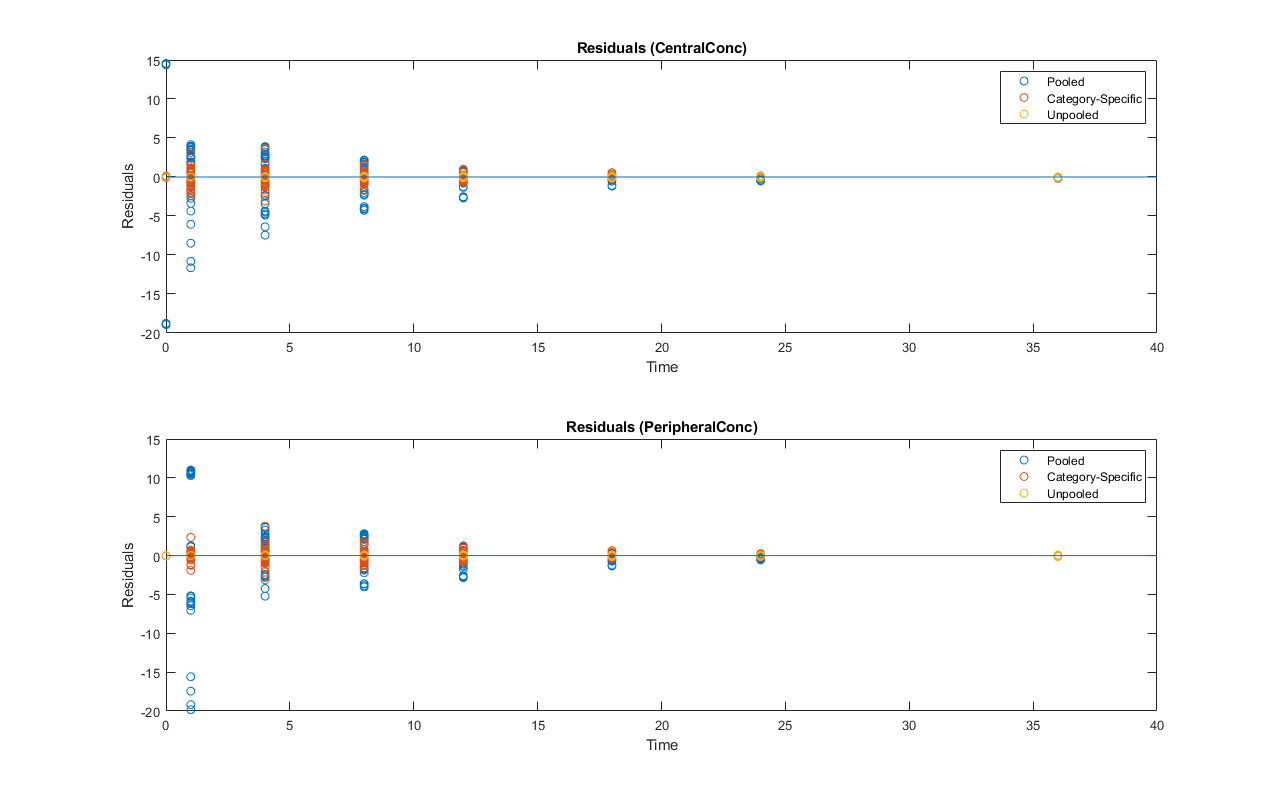
如情节所示,未共享适应生产最适合的数据,因为它适合每个人的数据。这是预期的,因为它使用了最多的自由度。category-fit减少自由度的数量,通过拟合数据两类(性别和年龄)。因此,残差大于未共享健康,但仍小于population-fit,估计只有一个为所有个人设定的参数。category-fit可能是一个很好的妥协未共享和集中之间的拟合提供任何层次模型存在于您的数据。