支持向量机预测的定点代码生成
这个例子展示了如何为支持向量机(SVM)模型的预测生成定点C/ c++代码。金宝app与一般的C/ c++代码生成工作流相比,定点代码生成需要一个额外的步骤,定义预测所需的变量的定点数据类型。使用。创建定点数据类型结构generatelearnerdatatypefcn.,并使用该结构作为输入参数loadLearnerForCoder在入口点函数中。您还可以在生成代码之前优化定点数据类型。
此流程图显示了定点代码生成工作流程。

训练支持向量机模型。
通过使用保存训练的模型
Savelarnerforcoder..通过使用生成的数据类型函数定义预测所需变量的定点数据类型
generatelearnerdatatypefcn..定义一个入口点函数加载模型同时使用
loadLearnerForCoder和结构,然后调用预测函数。(可选的)优化的定点数据的类型。
产生定点C / C ++代码。
验证生成的代码。
第5步是可选的步骤,以改善所产生的定点代码的性能。要做到这一点,重复这两个步骤,直到您满意的代码性能:
通过使用用于预测的变量的记录的最小值和最大值
buildInstrumentedMex(定点设计师).使用仪器使用
showInstrumentationResults(定点设计师).然后,调优定点数据类型(如果必要的话),以防止溢出和下流,并提高定点代码的精度。
在此工作流中,通过使用生成的数据类型函数定义定点数据类型generatelearnerdatatypefcn..将变量的数据类型从算法中分离出来可以使测试更简单。通过使用数据类型函数的输入参数,可以通过编程在浮点和定点之间切换数据类型。此外,这个工作流是兼容的手动固定点转换工作流程(定点设计师).
数据预处理
加载census1994数据集。这个数据集由美国人口普查局的人口统计数据组成,用来预测一个人的年收入是否超过5万美元。
负载census1994
考虑一个模型,它根据员工的年龄、工人阶级、教育水平、资本损益和每周工作时间来预测员工的工资类别。提取感兴趣的变量并使用表保存它们。
台= adultdata (:, {“时代”那'education_num'那'capital_gain'那“capital_loss”那“hours_per_week”});
打印表格的摘要。
总结(台)
变量:年龄:32561x1双值:最小17中值37最大90 education_num:32561x1双值:敏1中值10最大16 capital_gain:32561x1双值:最小0平均0最大值99999 capital_loss:32561x1双值:最小0平均0最大4356hours_per_week:32561x1双重价值:分1位数40最大99
变量的尺度并不一致。在这种情况下,你可以使用一个标准化的数据集通过指定训练模型“标准化”的名称-值对参数fitcsvm.然而,添加的操作标准化到定点代码可以降低精度和提高内存的使用。相反,你可以手动标准化的数据集,如本例所示。这个例子也说明了如何检查在最后的内存使用。
代码生成不支持表或分类阵列。金宝app因此,界定预测数据X.使用数字矩阵,并定义类标签y使用逻辑矢量。逻辑向量中的二元分类问题最有效地使用存储器。
X = table2array(TBL);Y = adultdata.salary =='<= 50K';
定义观测权值W..
w = adultdata.fnlwgt;
存储器使用的作为支持向量的模型中的增加数目的训练的模型增加。金宝app为了减少支持向量的数量,可以增加箱约束使用训练的金宝app时候'BoxConstraint'名称-值对参数或使用下采样的代表性数据集进行训练。注意,增加方框约束会导致训练时间变长,而使用下采样数据集会降低训练模型的准确性。在本例中,从数据集中随机抽取1000个观察数据,并使用下采样的数据进行训练。
rng (“默认”)%的再现性[x_sampled,idx] = datasample(x,1000,“替换”、假);Y_sampled = Y (idx);w_sampled = w (idx);
查找使用训练模型的加权平均值和标准偏差“重量”和“标准化”名称-值对参数。
tempMdl = fitcsvm (X_sampled Y_sampled,“重量”w_sampled,“KernelFunction”那“高斯”那“标准化”,真的);亩= tempMdl.Mu;差= tempMdl.Sigma;
如果你不使用“费用”那“之前”或者“重量”的名称-值对参数,然后可以通过使用zscore函数。
[standardizedX_sampled、μ、σ]= zscore (X_sampled);
通过使用标准化预测数据μ和Sigma..
standardizedX =(X-MU)./西格玛;standardizedX_sampled = standardizedX(IDX,:);
您可以使用测试数据集来验证培训的模型并测试仪表后的MEX功能。指定测试数据集并通过使用标准化测试预测器数据μ和Sigma..
XTest = table2array(成人(:{“时代”那'education_num'那'capital_gain'那“capital_loss”那“hours_per_week”}));standardizedXTest = (XTest-mu)。/σ;欧美=成人。工资= ='<= 50K';
火车模型
培训二进制SVM分类模型。
MDL = fitcsvm(standardizedX_sampled,Y_sampled,“重量”w_sampled,“KernelFunction”那“高斯”);
Mdl是A.ClassificationSVM模型。
计算训练数据集和测试数据集的分类误差。
损失(Mdl standardizedX_sampled Y_sampled)
ANS = 0.1663
损失(Mdl standardizedXTest、欧美)
ans = 0.1905
支持向量机分类器误分类了大约17%的训练数据和19%的测试数据。
保存模型
将SVM分类模型保存到文件中myMdl.mat通过使用Savelarnerforcoder..
saveLearnerForCoder(MDL,'myMdl');
定义固定点数据类型
使用generatelearnerdatatypefcn.生成一个函数,定义支持向量机模型预测所需变量的定点数据类型。使用所有可用的预测器数据来获得定点数据类型的真实范围。
generateLearnerDataTypeFcn('myMdl'[standardizedX;standardizedXTest])
generatelearnerdatatypefcn.生成myMdl_datatype函数。显示的内容mymdl_datatype.m.通过使用type函数。
typemymdl_datatype.m.
函数t = mymdl_datatype(dt)%mymdl_datatype定义了固定点代码生成%t = mymdl_datatype(dt)的数据类型返回数据类型结构t,该数据类型结构t,其定义生成固定点C / C ++所需的变量的%数据类型代码%用于机器学习模型的预测。的T每个字段都包含通过网络连接的返回%定点对象。输入参数DT指定定点对象的%DataType属性。指定作为DT“固定”(默认)%定点代码生成或指定DT为“双重”的定点代码的模拟%浮点行为。%%使用输出结构T作为一个入口点%函数的两个输入参数和%入口点函数内loadLearnerForCoder的第二输入参数。欲了解更多信息,请参见loadLearnerForCoder。%文件:mymdl_datatype.m%统计和机器学习工具箱版本12.0(发布r2020b)%由matlab生成,03-oct-2020 19:20:23如果nargin <1 dt ='固定';端%设定定点数学设置FM = fimath( 'RoundingMethod', '地面',... 'OverflowAction', '环绕',... 'ProductMode', 'FullPrecision',... 'MaxProductWordLength',128,... 'SumMode', 'FullPrecision',... 'MaxSumWordLength',128);预测器数据的%数据类型t.xdatatype = fi([],true,16,11,fm,'datatype',dt); % Data type for output score T.ScoreDataType = fi([],true,16,14,fm,'DataType',dt); % Internal variables % Data type of the squared distance dist = (x-sv)^2 for the Gaussian kernel G(x,sv) = exp(-dist), % where x is the predictor data for an observation and sv is a support vector T.InnerProductDataType = fi([],true,16,6,fm,'DataType',dt); end
注意:如果您单击位于这个例子中的右上部分的按钮,并在打开的MATLAB®例如,然后打开MATLAB的例子文件夹。此文件夹包含入口点函数文件。
当myMdl_datatype函数使用默认字长(16),并根据每个变量的默认字长(16)和安全裕度(10%)提出最大分数长度以避免溢出。
创建一个结构T.通过使用定义定点数据类型myMdl_datatype.
T = myMdl_datatype('固定')
T =结构体字段:XDataType: [0 x0嵌入。FI.] ScoreDataType: [0x0 embedded.fi] InnerProductDataType: [0x0 embedded.fi]
结构T.方法所需的已命名变量和内部变量的字段预测函数。每个字段包含一个定点对象,由FI.(定点设计师).例如,显示预测器数据的定点数据类型属性。
t.xdatatype.
ANS = [] DataTypeMode:定点:二进制点缩放符号性:签字字长:16 FractionLength:11 RoundingMethod:地板OverflowAction:裹ProductMode:FullPrecision MaxProductWordLength:128 SumMode:FullPrecision MaxSumWordLength:128
有关生成的功能和结构的详细信息,请参阅数据类型功能.
定义入口点函数
定义一个入口点函数名为myfixedpointpredict它的作用如下:
接受预测数据
X.和定点数据类型结构T..加载一个定点版本的训练支持向量机分类模型使用两者
loadLearnerForCoder和结构T.预测使用所加载的模型标签和分数。
函数(标签,分数)= myFixedPointPredict (X, T)%#codegen.MDL = loadLearnerForCoder('myMdl'那“数据类型”T);(标签,分数)=预测(Mdl X);结束
(可选)优化定点数据类型
使用以下方法优化定点数据类型buildInstrumentedMex和showInstrumentationResults.通过使用记录所有命名和内部变量的最小值和最大值buildInstrumentedMex.使用仪器使用showInstrumentationResults;然后,根据结果,调整变量的定点数据类型属性。
指定入口点函数的输入参数类型
的输入参数类型myfixedpointpredict使用2 × 1单元阵列。
ARGS =细胞(2,1);
第一输入参数是预测数据。当XDataType结构场T.指定所述预测数据的定点数据类型。转换X.的类型指定在t.xdatatype.通过使用铸(定点设计师)函数。
X_fx =投(standardizedX,“喜欢”,T.XDataType);
测试数据集与训练数据集的大小不相同。指定ARGS {1}通过使用coder.typeof(MATLAB编码器)以便MEX函数可以接受大小可变的输入。
ARGS {1} = coder.typeof (X_fx、大小(standardizedX) [1,0]);
第二输入参数是结构T.,它必须是一个编译时间常数。使用编码器。常数(MATLAB编码器)指定T.作为代码生成过程中的常数。
ARGS {2} = coder.Constant (T);
创建仪表MEX功能
通过使用创建仪器化的MEX功能buildInstrumentedMex(定点设计师).
属性指定入口点函数的输入参数类型
- args.选择。属性指定MEX函数名
-O选择。通过使用来计算直方图
-histogram选择。支持完整的代码生成金宝app
-coder选择。
buildInstrumentedMexmyfixedpointpredict- args.ARGS-OmyFixedPointPredict_instrumented-histogram-coder
测试仪表MEX功能
运行仪表MEX功能,记录仪表结果。
[labels_fx1, scores_fx1] = myFixedPointPredict_instrumented (X_fx T);
您可以多次运行录音MEX功能以从各种测试数据集记录结果。使用仪器化的MEX功能使用standardizedXTest.
Xtest_fx =铸造(standardizedXTest,“喜欢”,T.XDataType);[labels_fx1_test,scores_fx1_test] = myFixedPointPredict_instrumented(Xtest_fx,T);
查看仪表型MEX功能的结果
打电话showInstrumentationResults(定点设计师)打开包含仪器结果的报告。查看模拟最小值和最大值,提出分数长度,电流范围的百分比,和整数的状态。
showInstrumentationResults(“myFixedPointPredict_instrumented”)
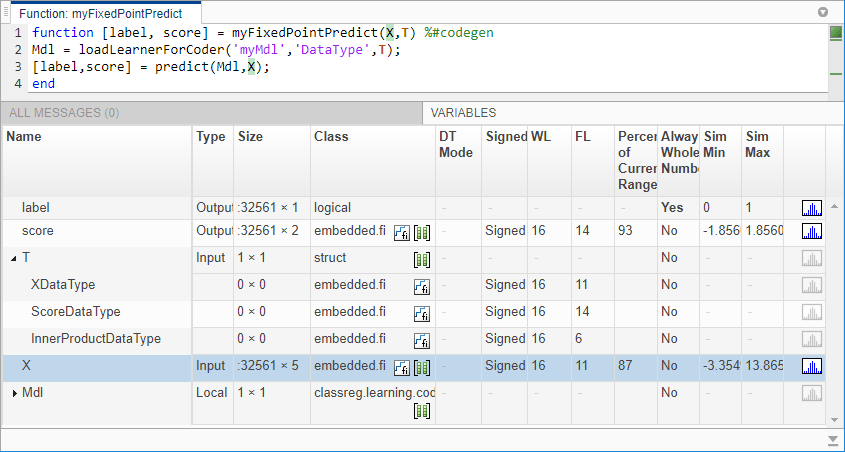
中建议的单词长度和分数长度X.是相同的那些XDataType在结构T..
通过单击查看变量的直方图 在变量标签。
在变量标签。
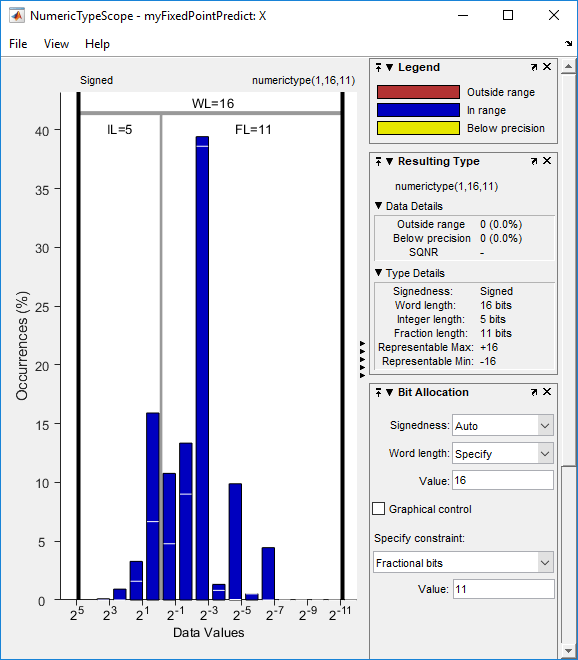
该窗口包含直方图和带有变量信息的对话框面板。有关此窗口的信息,请参阅numerictyPescope.(定点设计师)参考页面。
通过使用清除结果clearInstrumentationResults(定点设计师).
clearInstrumentationResults (“myFixedPointPredict_instrumented”)
验证仪器函数
从比较的输出预测和myFixedPointPredict_instrumented.
[标签,分数] =预测(MDL,standardizedX);verify_labels1 = ISEQUAL(标签,labels_fx1)
verify_labels1 =逻辑0.
ISEQUAL返回逻辑1(真),如果标签和labels_fx1是平等的。如果标签不相等,就可以计算错误分类标签的百分比如下。
diff_labels1 =总和(比较字符串(字符串(labels_fx1),字符串(标签))= = 0)/长度(labels_fx1) * 100
diff_labels1 = 0.1228
寻找最大的得分输出之间的相对差异。
diff_scores1 = max (abs (scores_fx1.double(: 1)分数(:1))。/分数(:1)))
diff_scores1 = 83.0713.
调定点数据类型
如果记录的结果显示溢出或下溢,或者希望提高生成代码的精度,则可以调优定点数据类型。的方法来修改定点数据类型myMdl_datatype工作,并创建一个新的结构,然后生成使用新的结构的代码。要更新myMdl_datatype功能,可以手动修改在功能文件定点数据类型(mymdl_datatype.m.)。或者,您可以生成使用功能generatelearnerdatatypefcn.并指定较长的单词长度,如本例所示。有关详细信息,请参见提示.
生成一个新的数据类型函数。指定单词长度为32和名称myMdl_datatype2为生成的函数。
generateLearnerDataTypeFcn('myMdl'[standardizedX;standardizedXTest]“字”,32,“OutputFunctionName”那“myMdl_datatype2”)
显示的内容myMdl_datatype2.m.
typemyMdl_datatype2.m
函数T = myMdl_datatype2(DT)%MYMDL_DATATYPE2定义数据类型为固定点代码生成%%T = MYMDL_DATATYPE2(DT)返回数据类型结构T,它定义为变量%的数据类型需要生成定点C / C ++代码%用于机器学习模型的预测。的T每个字段都包含通过网络连接的返回%定点对象。输入参数DT指定定点对象的%DataType属性。指定作为DT“固定”(默认)%定点代码生成或指定DT为“双重”的定点代码的模拟%浮点行为。%%使用输出结构T作为一个入口点%函数的两个输入参数和%入口点函数内loadLearnerForCoder的第二输入参数。欲了解更多信息,请参见loadLearnerForCoder。%文件:myMdl_datatype2.m%统计和机器学习工具箱12.0版(版本R2020b)%的MATLAB生成,03-OCT-2020 19时21分37秒,如果nargin <1 DT = '固定';端%设定定点数学设置FM = fimath( 'RoundingMethod', '地面',... 'OverflowAction', '环绕',... 'ProductMode', 'FullPrecision',... 'MaxProductWordLength',128,... 'SumMode', 'FullPrecision',... 'MaxSumWordLength',128);%数据类型为预测数据T.XDataType =音响([],真实,32,27,FM, '数据类型',DT); % Data type for output score T.ScoreDataType = fi([],true,32,30,fm,'DataType',dt); % Internal variables % Data type of the squared distance dist = (x-sv)^2 for the Gaussian kernel G(x,sv) = exp(-dist), % where x is the predictor data for an observation and sv is a support vector T.InnerProductDataType = fi([],true,32,22,fm,'DataType',dt); end
当myMdl_datatype2功能指定字长32并提出了最大比例的长度,以避免溢出。
创建一个结构T2通过使用定义定点数据类型myMdl_datatype2.
T2 = myMdl_datatype2 ('固定')
T2 =结构体字段:XDataType: [0 x0嵌入。FI.] ScoreDataType: [0x0 embedded.fi] InnerProductDataType: [0x0 embedded.fi]
创建一个新的仪表函数,记录结果,并通过使用查看结果buildInstrumentedMex和showInstrumentationResults.
X_fx2 =铸造(standardizedX,“喜欢”, T2.XDataType);buildInstrumentedMexmyfixedpointpredict- args.{x_fx2,coder.constant(t2)}-OmyFixedPointPredict_instrumented2-histogram-coder[labels_fx2,scors_fx2] = myfixedpointpredict_instrumented2(x_fx2,t2);showInstrumentationResults('myFixedPointPredict_instrumented2')
查看仪表报告,然后清除结果。
clearInstrumentationResults ('myFixedPointPredict_instrumented2')
验证myFixedPointPredict_instrumented2.
verify_labels2 = ISEQUAL(标签,labels_fx2)
verify_labels2 =逻辑0.
diff_labels2 = sum(strcmp(string(labels_fx2),string(标签))== 0)/ length(labels_fx2)* 100
diff_labels2 = 0.0031
diff_scores2 = max(abs((scores_fx2.double(:,1)-scores(:,1))./ scores(:1)))
diff_scores2 = 2.0602
错误分类标签的百分比diff_labels2和得分值的相对差diff_scores2.小于使用默认字长度生成的先前MEX函数(16)的那些。
有关通过插MATLAB®代码优化定点数据类型的更多详情,请参见参考页buildInstrumentedMex(定点设计师)那showInstrumentationResults(定点设计师),clearInstrumentationResults(定点设计师),以及例子一组数据类型使用最小/最大仪器仪表(定点设计师).
生成代码
使用生成入口点函数的代码Codegen..而不是指定用于预测器数据集的可变大小输入,请通过使用指定固定大小的输入coder.typeof.如果您知道传递给生成的代码的预测器数据集的大小,则优选为固定大小输入的代码用于代码的简单性。
Codegen.myfixedpointpredict- args.{coder.typeof(X_fx2,[1,5],[0,0]),coder.Constant(T2)}
Codegen.生成MEX函数myFixedPointPredict_mex与平台相关的扩展。
验证生成的代码
您可以验证myFixedPointPredict_mex函数的方法与验证仪表化的MEX函数的方法相同。看到验证仪器函数部分细节。
[labels_sampled, scores_sampled] =预测(Mdl standardizedX_sampled);n =大小(standardizedX_sampled, 1);labels_fx = true (n, 1);scores_fx = 0 (n, 2);对于I = 1:N [labels_fx(i)中,scores_fx(I,:)] = myFixedPointPredict_mex(X_fx2(IDX(i)中,:),T2);结束verify_labels = ISEQUAL(labels_sampled,labels_fx)
verify_labels =逻辑1
diff_labels =总和(比较字符串(字符串(labels_fx),字符串(labels_sampled)) = = 0) /长度(labels_fx) * 100
diff_labels = 0
diff_scores = MAX(ABS((scores_fx(:,1)-scores_sampled(:,1))./ scores_sampled(:,1)))
diff_scores = 0.0638
内存使用
良好做法是在培训模型之前手动标准化预测器数据。如果你使用“标准化”名称 - 值对的参数,而不是,然后将所生成的定点代码包括标准化的操作,这会导致精度的损失和增加的内存使用。
如果您生成一个静态库,您可以通过使用一个代码生成报告找到的内存使用生成的代码。指定配置:自由要生成静态库,并使用-report.选项生成的代码生成报告。
Codegen.myfixedpointpredict- args.{coder.typeof(X_fx2,[1,5],[0,0]),coder.Constant(T2)}-OmyFixedPointPredict_lib配置:自由-report.
在这一点总结代码生成报告的选项卡,单击代码指标.函数信息部分显示累积的堆栈大小。
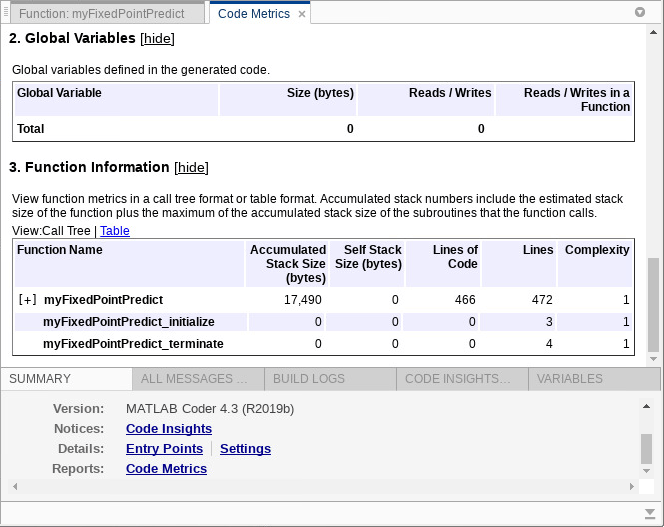
要查找内存使用与培养了模型'标准化','真',您可以运行以下代码。
MDL = fitcsvm(X_sampled,Y_sampled,“重量”w_sampled,“KernelFunction”那“高斯”那“标准化”,真的);saveLearnerForCoder(MDL,'myMdl');generateLearnerDataTypeFcn('myMdl'[X;XTest),“字”,32,“OutputFunctionName”那“myMdl_standardize_datatype”)T3 = myMdl_standardize_datatype('固定');X_fx3 =铸造(X_sampled,“喜欢”, T3.XDataType);Codegen.myfixedpointpredict- args.{coder.typeof (X_fx3 [1,5], [0]), coder.Constant (T3)}-OmyFixedPointPredict_standardize_lib配置:自由-report.
另请参阅
generatelearnerdatatypefcn.|loadLearnerForCoder|Savelarnerforcoder.|buildInstrumentedMex(定点设计师)|铸(定点设计师)|clearInstrumentationResults(定点设计师)|FI.(定点设计师)|showInstrumentationResults(定点设计师)|Codegen.(MATLAB编码器)
相关主题
- 定点数据类型(定点设计师)
- 创建MATLAB定点数据(定点设计师)
- 一组数据类型使用最小/最大仪器仪表(定点设计师)
你也可以从以下列表中选择一个网站:
