基于深度学习的语音指令识别
此示例显示如何训练检测音频中的语音命令的存在的深度学习模型。该示例使用语音命令数据集[1]培训卷积神经网络以识别给定的一组命令。
要从头开始训练网络,必须先下载数据集。如果不想下载数据集或训练网络,则可以加载本示例提供的预训练网络,并执行示例的下两部分:通过预先训练的网络识别命令和使用麦克风中的流音频检测命令.
通过预先训练的网络识别命令
在进入详细的训练过程之前,您将使用预先训练过的语音识别网络来识别语音命令。
加载预先训练的网络。
加载(“commandNet.mat”)
对网络进行培训,以识别以下语音命令:
“是的”
“不”
“向上”
“向下”
“左”
“正确”
“关于”
“离开”
“停止”
“走”
在有人说“停止”的地方加载一个简短的语音信号。
[x,fs] = audioread(“stop_command.flac”);
听指挥。
声音(x, fs)
预先训练的网络以基于听觉的谱图作为输入。首先将语音波形转换为基于听觉的声谱图。
使用功能extractAuditoryFeature来计算听觉谱图。在稍后的示例中,您将了解特征提取的细节。
听觉探测= PerverextractAutiveFeatures(X,FS);
根据命令的声谱图对其进行分类。
命令=分类(trainedNet auditorySpect)
命令=分类停止
培训网络以对不属于此设置的单词进行分类为“未知”。
现在您将对命令列表中没有包含的单词(“play”)进行分类以识别。
加载语音信号并收听它。
x = audioread(“play_command.flac”);声音(x, fs)
计算听觉谱图。
听觉探测= PerverextractAutiveFeatures(X,FS);
分类信号。
命令=分类(trainedNet auditorySpect)
命令=分类未知
培训网络以将背景噪声分类为“背景”。
创建由随机噪声组成的一秒信号。
x = pinknoise (16 e3);
计算听觉谱图。
听觉探测= PerverextractAutiveFeatures(X,FS);
对背景噪声进行分类。
命令=分类(trainedNet auditorySpect)
命令=分类背景
使用麦克风中的流音频检测命令
在麦克风的流音频上测试预先训练的命令检测网络。例如,试着说出其中一条命令,是的,不或停止.然后,试着说出其中一个不认识的单词,比如马文,希拉,床上,房屋,猫,鸟,或者从0到9的任何数字。
以Hz为单位指定分类率,并创建可以从麦克风读取音频的音频设备读取器。
classificationRate = 20;adr = audioDeviceReader (“采样器”fs,“SamplesPerFrame”、地板(fs / classificationRate));
初始化音频缓冲区。提取网络的分类标签。为流音频的标签和分类概率初始化半秒的缓冲区。使用这些缓冲区来比较较长一段时间内的分类结果,并在检测到命令时构建“一致”。为决策逻辑指定阈值。
audioBuffer = dsp.AsyncBuffer (fs);. class标签= trainedNet.Layers(结束);YBuffer (1: classificationRate / 2) =分类(“背景”);probbuffer = zeros([numel(标签),分类符号/ 2]);countthreshold = ceil(分类符号* 0.2);probthreshold = 0.7;
只要创建的图形存在,就创建一个图形并检测命令。要无限期地运行循环,请设置时限到正.要停止活检测,只需关闭图形。
h =图(“单位”,“归一化”,“位置”,[0.2 0.1 0.6 0.8]);期限= 20;抽搐尽管ishandle(h)和&toc<时限%从音频设备中提取音频样本并将样本添加到%缓冲区。x=adr();write(audioBuffer,x);y=read(audioBuffer,fs,fs adr.SamplesPerFrame);spec=helperExtractAuditoryFeatures(y,fs);%对当前光谱图进行分类,将标签保存到标签缓冲区,%并将预测的概率保存到概率缓冲区。[YPredicted,聚合氯化铝]=分类(trainedNet,规范,“ExecutionEnvironment”,“cpu”);YBuffer = [YBuffer(2:结束),YPredicted);probBuffer = [probBuffer(:, 2:结束)、聚合氯化铝(:));%绘制当前波形和频谱图。子地块(2,1,1)绘图(y)轴紧Ylim ([-1,1]) subplot(2,1,2) pcolor(spec') caxis([-4 2.6445])底纹平现在通过执行一个非常简单的命令来进行实际的命令检测%阈值操作。声明检测并在%数字标题,如果所有以下持有:1)最常见的标签%不是背景。2)至少是最新帧的countThreshold%标签一致。3)预测标签的最大概率为at% probThreshold最少。否则,不要声明检测。[YMODE,COUNT] =模式(YBUFFER);maxprob = max(probbuffer(标签== ymode,:));子图(2,1,1)如果YMode = =“背景”||计数”“)其他的标题(字符串(YMode),“字形大小”,20)结束drawnow结束


加载语音命令数据集
此示例使用Google Speech Commands数据集[1]。下载该数据集并卸载下载的文件。将PathToDatabase设置为数据的位置。
url =“https://ssd.mathworks.com/金宝appsupportfiles/audio/google_speech.zip”;downloadFolder=tempdir;dataFolder=fullfile(downloadFolder,“google_speech”);如果~存在(dataFolder“dir”) disp ('下载数据集(1.4 GB)...'解压缩(url, downloadFolder)结束
创建培训数据存储
创建一个audioDatastore(音频工具箱)指向训练数据集。
ads=音频数据存储(完整文件(数据文件夹,'火车'),...'insertumbfolders',真的,...“FileExtensions”,“wav”,...'labelsource',“foldernames”)
ads = audioDatastore与属性:文件:{'…\AppData\Local\Temp\google_speech\train\bed\00176480_nohash_0.wav';’……\ AppData \当地\ Temp \床google_speech \培训\ \ 004 ae714_nohash_0.wav;’……\ AppData \当地\ Temp \床google_speech \培训\ \ 004 ae714_nohash_1.wav……{'C:\Users\jibrahim\AppData\Local\Temp\google_speech\train'}标签:[bed;床上;床上……alteratefilesystemroots: {} OutputDataType: 'double' SupportedOutputFormats: ["wav金宝app" "flac" "ogg" "mp4" "m4a"] DefaultOutputFormat: "wav"
选择要识别的单词
指定希望模型识别为命令的单词。将所有非命令的单词标记为命令未知的.标记不是命令的单词未知的创建一组单词,它近似于除命令之外的所有单词的分布。网络使用这个组来学习命令和所有其他单词之间的区别。
为了减少已知和未知单词之间的类别不平衡,加快处理速度,只在训练集中包含一小部分未知单词。
使用子集(音频工具箱)创建只包含命令和未知单词子集的数据存储。计算属于每个类别的例子的数量。
命令=分类([“是的”,“不”,“向上”,“向下”,“左”,“正确”,“关于”,“离开”,“停止”,“走”]);IsCommand = ISMember(Ads.Labels,命令);isUnknown = ~ isCommand;includeFraction = 0.2;mask = rand(numel(ads.Labels),1) < includeFraction;isUnknown = isUnknown & mask;Ads.Labels(Isunknown)=分类(“未知”);adstrain =子集(广告,iscommand | isunknown);CountAckeLabel(adstrain)
ans = 11×2表标签计数_______ _____下调1842年1861年离开1839年1839年1839年1864年1864右1885年未知6483 UP 1843是1843
创建验证数据存储
创建一个audioDatastore(音频工具箱)这指向验证数据集。遵循用于创建培训数据存储的相同步骤。
ads=音频数据存储(完整文件(数据文件夹,“验证”),...'insertumbfolders',真的,...“FileExtensions”,“wav”,...'labelsource',“foldernames”) isCommand = ismember(ads.Labels,commands);isUnknown = ~ isCommand;includeFraction = 0.2;mask = rand(numel(ads.Labels),1) < includeFraction;isUnknown = isUnknown & mask;Ads.Labels(Isunknown)=分类(“未知”);adsValidation =子集(广告,isCommand | isUnknown);countEachLabel (adsValidation)
广告=具有属性的AudioDataStore:文件:{'... \ appdata \ local \ temp \ google_speech \验证\ bick \ 026290a7_nohash_0.wav';'... \ appdata \ local \ temp \ google_speech \验证\ boad \ 060cd039_nohash_0.wav';'... \ appdata \ local \ temp \ google_speech \ viguration \ bick \ 060cd039_nohash_1.wav'...和6795更多}文件夹:{'c:\ users \ jibrahim \ appdata \ local \ temp \ google_speech \验证'}标签:[床;床上;床......和6795更多分类]替代文件系统:{} outputDatatype:'double'supportedOutputFormats:[“WAV”“FLAC”“OGG金宝app”“MP4”“M4A”] DefaultOutputFormat:“WAV”ANS = 11×2表标签计数_______ _____ _____下降264转260左247 op 256 op 257 off 256右256秒钟,未知850 up 260是261
要用整个数据集训练网络,并达到尽可能高的精度,集合逃守血统到假.要快速运行此示例,请设置逃守血统到真的.
reducedastatset=false;如果reduceDataset numUniqueLabels = nummel (unique(adsTrain.Labels));%将数据集减少20倍adsTrain = splitEachLabel(adsTrain,round(numel(adsTrain. files) / numUniqueLabels / 20));adsValidation = splitEachLabel(adsValidation,round(numel(adsValidation. files) / numUniqueLabels / 20));结束
计算听觉谱图
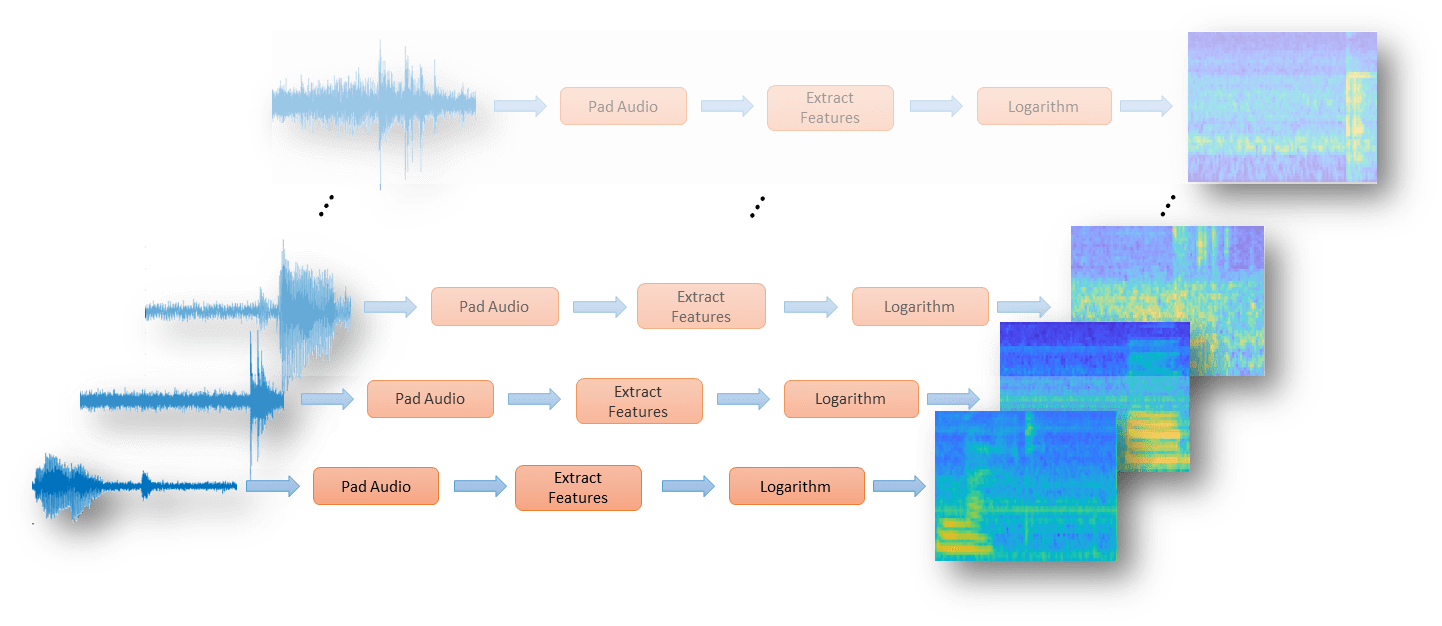
为了准备有效训练卷积神经网络的数据,将语音波形转换为基于听觉的谱图。
定义特征提取的参数。segmentDuration是每个语音剪辑的持续时间(以秒为单位)。框架是频谱计算的每个帧的持续时间。hopDuration是每个光谱之间的时间步长。numBands为听觉声谱图中过滤器的数量。
创建一个audioFeatureExtractor(音频工具箱)对象进行特征提取。
fs = 16 e3;%数据集的已知抽样率。segmentDuration = 1;frameDuration = 0.025;hopDuration = 0.010;segmentSamples =圆(segmentDuration * fs);frameSamples =圆(frameDuration * fs);hopSamples =圆(hopDuration * fs);overlapSamples = framessamples - hopSamples;FFTLength = 512;numBands = 50;afe = audioFeatureExtractor (...“采样器”fs,...“FFTLength”,fftlength,...“窗口”损害(frameSamples“周期”),...“重叠长度”overlapSamples,...“barkSpectrum”,真的);setExtractorParams(AFE,“barkSpectrum”,“NumBands”numBands,“窗口规范化”,错误的);
从数据集读取文件。训练卷积神经网络需要输入大小一致。数据集中的一些文件长度小于1秒。在音频信号的前面和后面应用零填充,使其具有长度SEGMANSEMPLES..
x=读取(adsTrain);numSamples=大小(x,1);numToPadFront=地板((分段采样-numSamples)/2);numToPadBack=天花板((分段采样-numSamples)/2);xPadded=[零(numToPadFront,1,“喜欢”,x);x;零(numToPadBack,1,“喜欢”,x)];
要提取音频功能,请调用摘录.输出是跨行带有时间的Bark谱。
特征=提取(afe,xPadded);[numHops,numFeatures]=大小(特征)
numHops = 98 numFeatures = 50
在本例中,通过应用对数对听觉声谱图进行后处理。取小数字的对数会导致四舍五入错误。
要加快处理速度,可以使用parfor.
首先,确定数据集的分区数。如果您没有并行计算工具箱™,请使用单个分区。
如果~ isempty(版本(“平行”))&&&~reducedasetpool=gcp;numPar=numpartitions(adsTrain,pool);其他的numPar = 1;结束
对于每个分区,从数据存储中读取,填充信号零,然后提取特征。
parforii = 1:numPar subds = partition(adsTrain,numPar,ii);XTrain = 0 (numHops numBands 1,元素个数(subds.Files));为idx = 1:numel(subds. files) x = read(subds);xPadded =[0(地板(segmentSamples-size (x, 1)) / 2), 1); x; 0(装天花板((segmentSamples-size (x, 1)) / 2), 1)];XTrain (:,:,:, idx) =提取(afe xPadded);结束XTrainC{ii}=XTrain;结束
将输出转换为沿第四维度的听觉光谱图的四维阵列。
XTrain=cat(4,XTrainC{:});[numHops,numBands,numChannels,numSpec]=size(XTrain)
numHops=98 numBands=50 numChannels=1 numSpec=25021
根据窗户功率缩放特征,然后取日志。为了获得分布更平滑的数据,使用小偏移量对谱图取对数。
epsil = 1 e-6;XTrain = log10(XTrain + epsil);
执行上面描述的特征提取步骤到验证集。
如果~ isempty(版本(“平行”))pool = gcp;numpar = numpartitions(adsvalidation,pool);其他的numPar = 1;结束parforii = 1:numPar subds = partition(adsValidation,numPar,ii);XValidation = 0 (numHops numBands 1,元素个数(subds.Files));为idx = 1:numel(subds. files) x = read(subds);xPadded =[0(地板(segmentSamples-size (x, 1)) / 2), 1); x; 0(装天花板((segmentSamples-size (x, 1)) / 2), 1)];XValidation (:,:,:, idx) =提取(afe xPadded);结束XValidationC {2} = XValidation;结束XValidation=cat(4,XValidationC{:});XValidation=log10(XValidation+epsil);
隔离列车和验证标签。删除空的类别。
YTrain = removecats (adsTrain.Labels);YValidation = removecats (adsValidation.Labels);
可视化数据
绘制一些训练样本的波形和听觉谱图。播放相应的音频片段。
specMin = min (XTrain [],“所有”);specMax = max (XTrain [],“所有”);idx = randperm(元素个数(adsTrain.Files), 3);图(“单位”,“归一化”,“位置”,[0.2 0.2 0.6 0.6]);为i = 1:3 [x,fs] = audioread(adsTrain.Files{idx(i)});次要情节(2、3、i)情节(x)轴紧标题(string (adsTrain.Labels (idx (i))))次要情节(2 3 i + 3) spect = (XTrain (:,: 1, idx(我)');cxis ([specMin specMax])阴影平声音(x, fs)暂停(2)结束
添加背景噪声数据
该网络不仅要能够识别不同的语音,还必须能够检测输入是否包含沉默或背景噪声。
使用中的音频文件_background_文件夹以创建一秒钟背景噪音片段的示例。从每个背景噪音文件创建相同数量的背景噪音片段。您也可以创建自己的背景噪音录制并将其添加到_background_ 文件夹。在计算频谱图之前,该函数重新分配每个音频剪辑,其中因子从所提供的范围中的日志均匀分布中采样volumeRange.
adsBkg = audioDatastore (fullfile (dataFolder“背景”))numbkgclips = 4000;如果SDENTATASET NUMBKGCLIPS = NUMBKGCLIPS / 20;结束volumeRange = log10([1的军医,1]);numBkgFiles =元素个数(adsBkg.Files);numClipsPerFile = histcounts (1: numBkgClips, linspace (1 numBkgClips numBkgFiles + 1);Xbkg = 0(大小(XTrain, 1),大小(XTrain, 2), 1, numBkgClips,“单一”);bkgAll = readall (adsBkg);印第安纳州= 1;为count = 1:numbkgfiles bkg = bkgall {count};idxstart = randi(numel(bkg)-fs,numclipsperfile(count),1);idxend = idxstart + fs-1;增益= 10. ^((volumerange(2)-volumerange(1))* rand(numclipsperfile(count),1)+ volumerange(1));为j = 1:numClipsPerFile(count) x = bkg(idxStart(j):idxEnd(j)))*gain(j); / /统计x = max (min (x, 1), 1);Xbkg(:,:,:,印第安纳州)=提取(afe x);如果国防部(印第安纳州,1000)= = 0 disp (“加工”(印第安纳州)+ +字符串“背景剪辑退出”+字符串(numBkgClips))结束ind=ind+1;结束结束Xbkg = log10(Xbkg + epsil);
adsbkg = audiodataStore具有属性:文件:{'... \ appdata \ local \ temp \ google_speech \ background \ dope_the_dishes.wav';'... \ appdata \ local \ temp \ google_speech \ background \ dude_miaowing.wav';'... \ appdata \ local \ temp \ google_speech \ background \ strotting_bike.wav'...和3更多}文件夹:{'c:\ users \ jibrahim \ appdata \ local \ temp \ google_speech \ background'} learstefilesystemroots:{} OutputDataType:'Double'标签:{} Support金宝appedOutputFormats:[“WAV”“FLAC”“ogg”“MP4”“M4a”] DefaultOutputFormat:“WAV”处理1000个背景剪辑中的4000个加工2000个背景剪辑中的4000个已加工40003000个背景剪辑中的4000个4000个背景夹子为4000
在训练集、验证集和测试集之间分割背景噪声谱图。因为_背景噪音_文件夹只包含约5分半钟的背景噪声,不同数据集中的背景样本具有高度相关性。为了增加背景噪音的变化,您可以创建自己的背景文件,并将它们添加到文件夹中。为了提高网络对噪声的鲁棒性,您还可以尝试在语音文件中混合背景噪声。
numTrainBkg =地板(0.85 * numBkgClips);numValidationBkg =地板(0.15 * numBkgClips);XTrain(:,:,: + 1:终端+ numTrainBkg) = Xbkg (:,:,:, 1: numTrainBkg);YTrain(+ 1:结束+ numTrainBkg) =“背景”;XValidation(:,:,: + 1:终端+ numValidationBkg) = Xbkg (:,:,:, numTrainBkg + 1:结束);YValidation(+ 1:结束+ numValidationBkg) =“背景”;
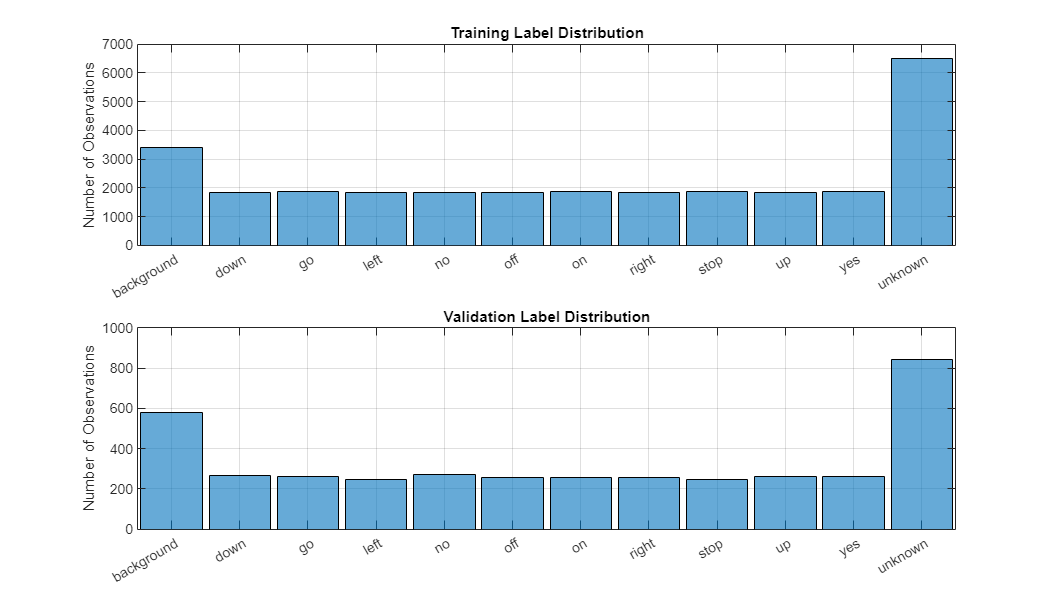
绘制不同类别标签在训练和验证集中的分布。
图(“单位”,“归一化”,“位置”,[0.2 0.2 0.5 0.5])子批次(2,1,1)直方图(YTrain)标题(“培训标签分配”)子图(2,1,2)直方图(YValidation)标题(“验证标签分配”)

定义神经网络结构
创建一个简单的网络架构,作为一组层。使用卷积和批处理归一化层,并使用最大池化层在“空间上”(即在时间和频率上)对特征映射进行向下采样。添加一个最终的最大池化层,随着时间的推移将输入特征映射全局池化。这在输入谱图中强制了(近似)时间平移不变性,允许网络执行相同的分类,而不依赖于语音在时间上的确切位置。全局池还显著减少了最终完全连接层中的参数数量。为了减少网络记忆训练数据的特定特征的可能性,在最后一个完全连接层的输入中添加少量的dropout。
这个网络很小,因为它只有五个卷积层和几个过滤器。numf.控制卷积层中的过滤器数量。为了提高网络的准确性,尝试通过添加相同的卷积块、批处理归一化块和ReLU层来增加网络深度。你也可以通过增加来增加卷积滤波器的数量numf..
使用加权交叉熵分类损失。weightedClassificationLayer (classWeights)创建一个自定义分类层,计算交叉熵损失与观测加权classWeights.按照类出现的顺序指定类权重类别(YTrain).为了使每个类在损失中具有相等的总权重,使用与每个类中的训练示例数量成反比的类权重。使用Adam优化器训练网络时,训练算法独立于类权值的整体归一化。
Classweights = 1./countcats(itrain);classweights = classweights'/均值(类别级);numclasses = numel(类别(YTrain));timepoolsize = ceil(numhops / 8);dropoutprob = 0.2;numf = 12;图层= [imageInputLayer([numhops numbands])卷积2dlayer(3,numf,“填充”,'相同的'maxPooling2dLayer(3,“步”2,“填充”,'相同的') convolution2dLayer (3 2 * numF“填充”,'相同的'maxPooling2dLayer(3,“步”2,“填充”,'相同的') convolution2dLayer(3、4 * numF,“填充”,'相同的'maxPooling2dLayer(3,“步”2,“填充”,'相同的') convolution2dLayer(3、4 * numF,“填充”,'相同的') batchNormalizationLayer reluLayer卷积2dlayer (3,4*numF,“填充”,'相同的') batchNormalizationLayer reluLayer maxPooling2dLayer([timePoolSize,1]) dropoutLayer(dropoutProb) fulllyconnectedlayer (numClasses) softmaxLayer weightedClassificationLayer(classWeights)];
列车网络的
指定训练选项。使用最小批量为128的Adam优化器。训练25个阶段,20个阶段后将学习率降低10倍。
miniBatchSize = 128;validationFrequency =地板(元素个数(YTrain) / miniBatchSize);选择= trainingOptions (“亚当”,...“InitialLearnRate”3的军医,...'maxepochs',25,...“MiniBatchSize”miniBatchSize,...“洗牌”,'每个时代',...“阴谋”,“培训进度”,...“详细”,错误的,...'vightationdata'{XValidation, YValidation},...'验证职业'validationFrequency,...“LearnRateSchedule”,“分段”,...“LearnRateDropFactor”, 0.1,...'学习ropperiod', 20);
培训网络。如果你没有GPU,那么训练网络可能会花费一些时间。
trainedNet=列车网络(XTrain、YTrain、图层、选项);
评估培训网络
在训练集(无数据扩充)和验证集上计算网络的最终精度。网络在此数据集上非常精确。但是,训练、验证和测试数据都具有类似的分布,不一定反映真实环境。此限制尤其适用于未知的类别,它只包含少量单词的话语。
如果reduceDataset负载(“commandNet.mat”,“训练网”);结束YValPred =分类(trainedNet XValidation);validationError = mean(YValPred ~= YValidation);YTrainPred =分类(trainedNet XTrain);= mean(YTrainPred ~= YTrain);disp (“训练错误:”+ trainError * 100 +“%”) disp ("验证错误:"+验证错误*100+“%”)
训练错误:1.907%验证错误:5.5376%
绘制混淆矩阵。通过使用列和行摘要显示每个类的精度和召回率。对混淆矩阵的类进行排序。最大的混淆是在未知的单词和命令之间,向上的和从,下来和不, 和去和不.
图(“单位”,“归一化”,“位置”,[0.2 0.2 0.5 0.5]);厘米= confusionchart (YValidation YValPred);厘米。Title =“验证数据的混淆矩阵”;厘米。ColumnSummary =“column-normalized”;厘米。RowSummary =“row-normalized”;sortClasses(厘米,[命令,“未知”,“背景”])

当对具有诸如移动应用的受限硬件资源的应用程序工作时,考虑可用内存和计算资源的限制。使用千兆字节计算网络的总大小,并在使用CPU时测试其预测速度。预测时间是对单个输入图像进行分类的时间。如果输入,如果将多个图像传输到网络,则可以同时对这些图像进行分类,从而缩短每个图像的预测时间。但是,在对流媒体音频进行分类时,单个图像的预测时间是最相关的。
信息=谁(“训练网”); disp(“网络大小:”+info.bytes/1024+“知识库”)为i = 1:100 x = randn([numHops,numBands]);tic [YPredicted,probs] = classification(训练网,x,“ExecutionEnvironment”,“cpu”);时间(i) = toc;结束disp (“CPU上的单映像预测时间:”+的意思是(时间(11:结束))* 1000 +“女士”)
网络大小:286.7402 kB CPU上的单张图像预测时间:2.5119 ms
参考文献
[1] Warden P.“语音命令:单词语音识别的公共数据集”,2017年。可从https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz.版权所有Google 2017.语音命令DataSet在Creative Commons归因4.0许可下许可,可在此处提供:https://creativecommons.org/licenses/by/4.0/legalcode.
参考文献
[1] Warden P.“语音命令:单词语音识别的公共数据集”,2017年。可从http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz.版权所有Google 2017.语音命令DataSet在Creative Commons归因4.0许可下许可,可在此处提供:https://creativecommons.org/licenses/by/4.0/legalcode.
另请参阅
trainNetwork|分类|analyzeNetwork
相关话题
您还可以从以下列表中选择一个网站:
