荷重软化估计使用原则估计模型
预见性维护工具箱™包括一些专业模型设计计算原则从不同类型的测量系统数据。这些模型是非常有用的,当你有历史数据和信息,如:
Run-to-failure历史的机器类似你想诊断
已知的某种条件阈值表示失败
多少时间和多少数据使用了类似的机器达到失败(一生)
荷重软化评估模型提供使用历史数据训练模型的方法和使用它的剩余使用寿命进行预测。这个词一生这里指的是机器的生活定义而言,无论你使用的数量来衡量系统的生活。类似的时间演化可能意味着一个值的进化与使用、距离、周期、数量或其他数量描述一生。
使用原则估算模型的一般工作流程是:
选择最好的类型的荷重软化估计模型数据和系统知识。创建和配置相应的模型对象。
培训使用的历史数据估计模型。为此,使用
适合命令。使用相同类型的测试数据作为历史数据,估计测试组件的原则。为此,使用
predictRUL命令。还可以使用测试数据递归更新一些模型类型,如退化模型,帮助保持预测准确。为此,使用更新命令。
对于一个基本的例子说明这些步骤,明白了更新原则预测数据的到来。
选择一个原则估计量
有三个家庭的荷重软化估计模型。选择家庭和使用哪个模型基于可用的数据和系统信息,如下图所示。
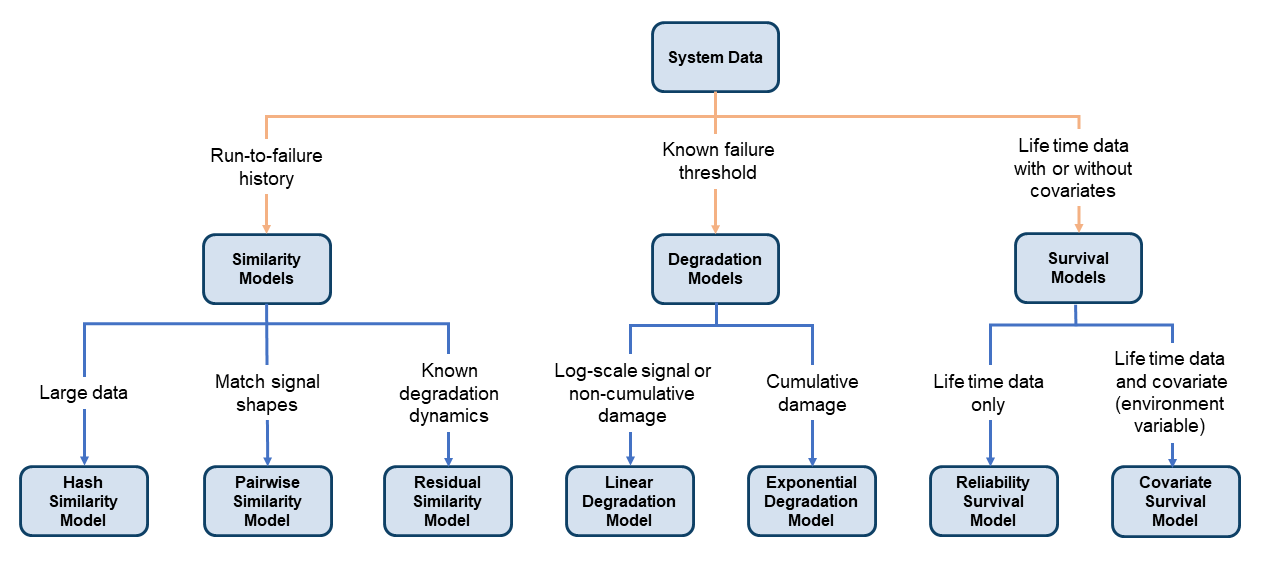
相似模型
相似模型测试机器的荷重软化预测基于已知的行为类似的机器从历史数据库。这样的模型试验数据的比较趋势或工况指示器值从其他相同的信息提取,类似的系统。
相似模型时是有用的:
你有从类似系统run-to-failure数据(组件)。Run-to-failure数据就是数据,开始健康操作期间和结束当机状态接近故障或维护。
run-to-failure数据显示类似的降解行为。即数据变化在某些特有的方式为系统降解。
因此你可以使用相似性模型可以获得退化概要文件从你的数据。退化概要代表一个或多个条件的演化指标在合奏(每个组件),每台机器的机器从健康状态过渡到一个错误的状态。
预见性维护工具箱包括三种类型的相似模型。所有三种类型估计原则通过确定退化之间的相似的历史测试数据集和退化的历史数据集的合奏。对于相似模型,predictRUL估计测试组件的荷重软化大多数类似的组件的平均寿命减去当前测试组件的生命周期价值。这三个模型不同的方式定义和量化相似的概念。
Hashed-feature相似模型(
hashSimilarityModel)——这个模型转换历史退化数据从每个成员的合奏成固定大小,浓缩,等信息的意思是,总功率、最大或最小值,或其他数量。当你打电话
适合在一个hashSimilarityModel对象,软件计算这些散列的功能并将它们存储在相似模型中。当你打电话predictRUL使用数据从一个测试组件,软件计算散列特性和比较结果历史哈希表中的值的特性。hashed-feature相似性模型是有用的,当你有大量的退化数据,因为它减少了存储预测所需的数据量。然而,它的准确性取决于模型使用的哈希函数的准确性。如果你已经确定了良好指标数据,您可以使用
方法财产的hashSimilarityModel对象指定哈希函数使用这些特性。成对相似性模型(
pairwiseSimilarityModel)——成对相似性评估确定原则通过寻找历史的降解路径的组件是最相关的测试组件。换句话说,它计算不同时间序列之间的距离,距离被定义为相关,动态时间扭曲(dtw你提供的),或一个自定义的指标。通过考虑退化概要文件,因为它改变随着时间的推移,成对相似性估计可以给更好的结果比散列相似模型。剩余相似模型(
residualSimilarityModel)——Residual-based估计符合之前的数据模型如ARMA模型或模型是线性或指数的使用时间。然后计算残差数据预测之间的整体模型和测试组件的数据。您可以查看剩余相似模型的变化成对相似性模型,其中残差的大小是距离度量。剩余相似性方法很有用,当你的知识系统包括一种形式的退化模型。
原则为例,利用相似性模型估计,明白了相似性剩余使用寿命的评估。
退化模型
退化模型推断过去的行为来预测未来的情况。这种类型的原则计算符合线性或指数模型退化的条件指标,考虑到退化概要文件在你的合奏。然后使用退化概要测试组件的统计计算剩余时间指标达到规定的阈值。这些模型是最有用的,当有一个已知值表示失败的条件。两个可用退化模型类型是:
线性退化模型(
linearDegradationModel)——描述了降解行为与一个偏移量的线性随机过程。线性退化模型非常有用当你的系统没有经验累积退化。指数退化模型(
exponentialDegradationModel——描述了退化行为作为一个以抵消项指数随机过程。测试组件时,指数退化模型是有用的经验累积退化。
在您创建一个退化模型对象,使用历史数据初始化模型关于健康的一个类似的组件,如多台机器生产的同一规格。为此,使用适合。然后您可以预测类似的组件使用的剩余使用寿命predictRUL。
退化模型只使用一个单一的条件指标。不过,您可以使用主成分分析或其他融合技术来生成熔融条件指标包含信息从多个条件指标。你是否使用一个指标或融合指标,寻找一个指示器显示一个明确的增加或减少的趋势,所以建模和外推法是可靠的。
为例,这种方法使用退化模型和估计荷重软化,明白了风力涡轮机高速轴承的预后。
生存模型
生存分析统计方法用于模型比较数据。它是有用的,当你没有完成run-to-failure历史,而是有:
只有类似的组件的寿命数据。例如,您可能知道每个引擎在你的合奏跑多少英里之前需要维护,或有多少小时的操作每台机器在你的合奏跑之前失败。在本例中,您使用
reliabilitySurvivalModel。鉴于历史故障信息时报的类似的组件,这个模型估计失败的概率分布。用于估计分布荷重软化测试组件。寿命和其他一些变量数据(协变量),与原则。,也叫环境变量或解释变量,包括信息,如组件提供者,政权的组件使用或生产批。在这种情况下,使用
covariateSurvivalModel。这个模型是一个生存比例风险模型协变量的使用寿命和计算的生存概率测试组件。
另请参阅
covariateSurvivalModel|reliabilitySurvivalModel|exponentialDegradationModel|linearDegradationModel|residualSimilarityModel|pairwiseSimilarityModel|hashSimilarityModel|适合|predictRUL