Il reinforcement learning è una tecnica di machine learning in cui un computer (agency) impara a svolgere un 'attività tramite ripetute interazioni di tipo " trial-and-error " (eseguite per tentativi error) con un ambiente dinamico。请所有的学徒同意所有的代理人在等级决定中作出决定,在等级决定中给予赔偿,在故事歌剧中给予方案,在故事歌剧中给予干预。
我编了一套人工智能程序来加强学习sono在第一个阶段的学习,在第二个阶段的学习,在第二个阶段的学习。强化学习不是一个概念,最近我在深入学习方面取得了一些进展,我们可以通过计算来了解人工智能。
区分tra强化学习,机器学习和深度学习
强化学习è在机器学习方面的研究(图1)。机器学习在监督下的一个不同之处,强化学习不是在一个静态的环境中进行的,而是在一个学徒的学习环境中进行的。我的经验是,在一个软件环境中进行“试错”(对试验性错误的判断)。加强学习的问题è是最重要的,它可以在结束时得出结论,在开始时的详细说明是必要的,在开始时的指导是必要的。在实践中,ciò显著,con l 'incentivo giusto, un modelello di reinforcement learning è grado di iniziare and appnere un portamento autonomamente, senza supervision (dell 'uomo)。
深度学习是机器学习的一个分支;强化学习和深度学习并不是相互的。我的问题是我不能完全理解强化学习,但是我不能完全理解深度强化学习。
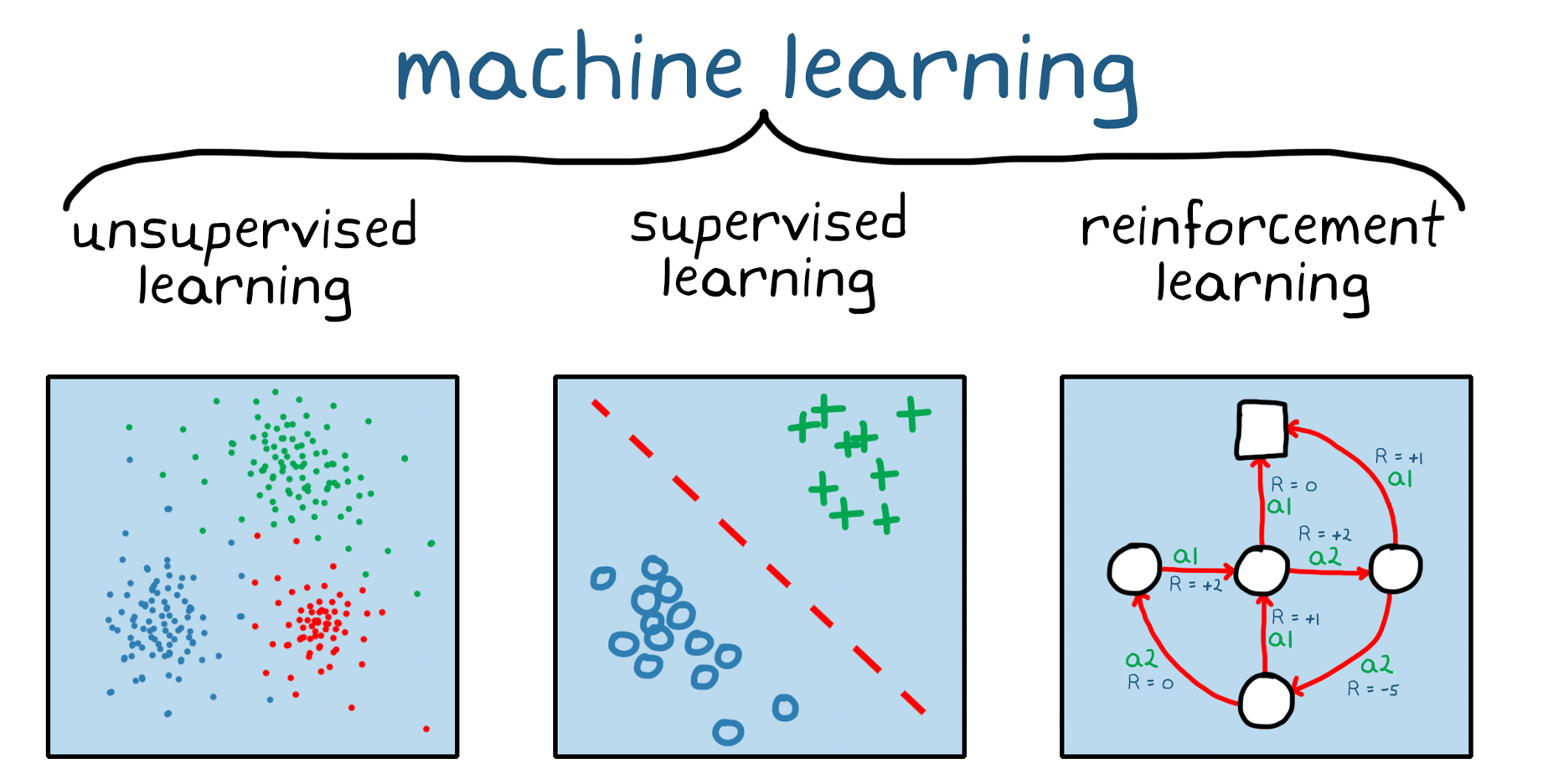
Figura 1。机器学习的分类:监督学习,监督强化学习。

强化学习的应用
勒reti neurali偏远在完整的文本中强调学习的重要性。Ciò consent di adottare un approccio alternative per le applicazioni che, diversamente, sarebbero intrattabili o più difficili da affrontare con metodi più tradizionali。因此,我们可以使用自主神经系统,也可以使用神经系统può所以我们可以决定我们可以使用神经系统più当代感觉系统,把相机和激光雷达框起来。在我们的神经系统中,有一些正常的问题,我们可以在più中找到一些特征,比如镜框和相机,还有一些激光雷达fusion degli输出dei传感器判断的前提是在感官输入的基础上“guida”。
我们将加强学习在生产中使用药物,在工业应用中使用药物,在技术上使用药物。
控制avanzati:控制这个系统的非线性è一个复杂的联合国问题,我们可以把这个系统的非线性控制在不同的操作中。强化学习può是非线性系统的直接应用。
Guida自治:请决定在基础上输入相机è un 'attività进行强化学习,我们认为可以成功地应用神经网络。
Robotica:强化学习può essere实用于应用程序来抓取一个机器人的部分,并将其作为一个独立的机器人,一个不同的拾取和放置工具。机器人的其他应用包括合作机器人、机器人、机器人。
Pianificazione:我的问题是,在不同的情况下,我们的伙伴国的伙伴国的伙伴国的伙伴国的伙伴国的伙伴国的伙伴国的伙伴国的伙伴国的伙伴国的伙伴国的伙伴国的伙伴国的伙伴国的伙伴国的伙伴国的伙伴国的。强化学习è对于解决组合问题的另一个选择是进化的。
Calibrazione:我们的应用程序有一个参数手册,也有一个参数手册unità电子控制(ECU),我们有必要了解所有加强学习的实施。
如果我们在现实的场景中学习强化,我们就可以在现实的场景中学习强化。按照我们的标准,我们要对家畜进行驯化。

Figura 2。它强化了学习用语言表达的能力。
我们可以用强化学习的术语(图2),在这个caso è quello di addestrare un cane(代理)affinché completi un 'attività所有的内部环境,包括ambiente che circonda il cane e persona che occupa del addestramento。我是第一个图托,我的行政长官dà我的长官和我的秘书,我的秘书和秘书。我可以,我可以,我可以,我可以。如果我有一个愿望,我的愿望就会实现,我的愿望很可能是offrirà,如果我有一个愿望,我的愿望就会实现;谢谢你,不是verrà,我想要你的礼物。所有的概率是risponderà con azioni più casual,所有的概率是risponderà con azioni più casual,所有的概率是“seduto”,所有的概率是“seduto”,所有的概率是risponderà con azioni più我有一个共同的想法,我有一个共同的想法,我有一个政治想法。在我们走完这条路的时候,我们的理想是在我们走完这条路的时候,我们的理想是在我们走完这条路的时候,我们的理想是在我们走完这条路的时候。最后一个很好的加强学习的方法是在你的学徒的行为习惯中使用拐杖。他说:“我知道,在我的任期内,我可以和我的老板在一个合适的任期内见面,我可以和我的老板在一个合适的任期内见面,我可以和我的老板在一个合适的任期内见面,我可以和我的老板在一个合适的任期内见面。” A questo punto, i premi sono ben accetti ma, in teoria, non dovrebbero più essere necessari.
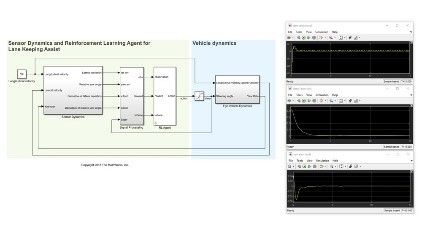
我们可以把它看作是一种强化学习,例如'attività di dover parcheggiare un veicolo usando un sistema di guida autonoma(图3)。l 'obiettivo è quello di seggnare al computer del veicolo(代理)parcheggiare nello spazio corretto con il reinforcement learning。请到甘蔗之家来,我们的氛围è tutto ciò我们所有的客人都是我们的客人,包括我们的葡萄酒家,我们的葡萄酒家,我们的氛围così通过。他说:“我们有一个很好的合作伙伴,我们有一个很好的合作伙伴,我们有一个很好的合作伙伴,我们有一个很好的合作伙伴。根据一个将军的判断,他有一个政党,他有一个政党,他有一个政党,他有一个政党,他有一个政党,他有一个政党,他有一个政党,他有一个政党。我们的价值'idoneità我们的初步研究和初步研究può我们的价值为我们的价值。
Figura 3。Il强化自主学习能力。
我要吃点甘蔗,我要吃点甘蔗。我要把它写在自治文件里,然后把它写在è里。在感官的基础上,在感官的基础上,在嗅觉的基础上,在嗅觉的基础上,在嗅觉的基础上,在嗅觉的基础上,在嗅觉的基础上,在嗅觉的基础上,在嗅觉的基础上,在嗅觉的基础上,在嗅觉的基础上,在嗅觉的基础上。在我们的语言中,我们可以用语言来表达我们的语言,我们可以用语言来表达我们的语言。
我们可以通过这个方法来加强学习,而不是遵循样本效率的原则。Ciò有意义的是,我们可以把它作为一种环境的主体,并把它作为一种环境的主体。根据我们的实际情况,AlphaGo,在每台计算机的空间中,我们可以编写一个最重要的程序,并为我们的围棋编写一个最基本的程序,è我们可以为我们的程序编写一个最基本的程序,我们可以为我们的世界编写一个最基本的程序,我们可以为我们的世界编写一个最基本的程序。每一个应用关系都是简单的,我在拥有所有权的同时,也在没有任何利益的情况下有一分钟的休息时间。在più中,公式中有一个问题,即在所有的情况下都有一个困难的问题,即在所有的情况下都有一个困难的问题,即在所有的情况下都有一个困难的问题。从本质上讲,我们可以看到,在我们的神经系统中,我们有一个合适的建筑结构,我们有一个合适的参数,我们有一个合适的结构。
工作流del强化学习
强化学习包括le seguenti fasi(图4):

Figura 4。工作流del强化学习。
1.Creazione戴尔'ambiente
首先,我们有必要定义所有的内部环境,andrà以及强化学习的主体,压缩环境的界面。我们的环境può是一种模拟环境的模型,我们的环境是真实的,我们的环境是模拟环境的主要步骤perché sono più sicuri e consentono di sperimentare。
2.德拉Definizione ricompensa
在seguito中,è的具体必要条件是il segnale di ricompensa che '代理利用每一个misurare le prestazioni rispetto agli obiettivi dell 'attività e la modalità di calcolo di questo segnale dall 'ambiente。如果你想要一个更复杂的产品,你可以选择一个更适合你的产品,你可以选择不同的产品。
3.Creazione戴尔'agente
一个问题是è必须有代理,我们可以在强化学习的基础上建立政治和算法。如果产品开发:
a)对每一位代表的看法都是政治上的。
b)选择恰当的addestramento算法。不同的表达方式代表了一个特定的分类算法。在一般情况下,però,在神经网络中,如果一个复杂的问题存在于一个大的维度中,那么我们就可以使用强化学习算法。
4.我的代理康复了
在制定政策之前,必须有一个确定的条件,必须有一个确定的政治主体。如果不确定最后一层是什么,就不能确定最后一层是什么。这是必要的,è是可能的,我们可以看到我们的规划,我们可以看到我们的规划,我们的建筑,我们的政治,我们的新程序。强化学习è一般不遵循样本效率原则;我很高兴能给你买到我们想要的东西。根据应用程序的复杂性,并行化的图形处理器可以访问più CPU, GPU集群可以访问renderà il processso più velocity(图5)。

Figura 5。为了解决这一问题,我们可以将抽样效率的原理平行地计算出来。
5.德拉Distribuzione politica
本程序是在C/ c++生成程序的基础上编写的。一个问题punto, la politica è un sistema decisionale independente。
通过迭代来加强学习。我们的决定是为了让我们能在工作流程中有一个更好的先例。然后,我们将这个过程不收敛于政治上的可接受程度然后我们将这个过程不收敛于政治上的可接受程度,我们有必要在这个过程中我们将最基本的要素在这个过程中我们将最基本的要素在这个过程中
- Impostazioni di addestramento
- 强化学习的一种算法
- 德拉Rappresentazione politica
- 定义为ricompensa
- 我是一个孤独的人
- Dinamica戴尔'ambiente
MATLAB®e强化学习工具箱™Semplificano le attività di强化学习。È可能的实现控制器和算法,根据决策,通过完成机器人的自治,通过加强学习的工作流程。Nello specifico, è可能:
1.我们可以用MATLAB和Simulink来模拟环境金宝app®
2.我们是神经网络的忠实忠实者,我们是强化学习的忠实忠实的忠实者
Insegnare一个双足机器人和一个强化学习工具箱™
3.强化学习的算法più consciuti come DQN, DDPG, PPO e SAC apando solo modifici di piccola entità al codice, oppure il自营算法personalizato
4.Usare并行计算工具箱™eMATLAB并行服务器™per adstrare le politiche di reinforcement learning più velocemente servendosi di più GPU, più CPU, cluster di computer e rise Cloud
5.Generare code e distribuire politiche di reinforcement learning su dispositivi embedded con MATLAB Coder™e GPU Coder™
6.这是一个加强学习的好方法esempi di riferimento.
Per saperne di più sul强化学习








我要30杯咖啡

海una domanda吗?
你也可以从以下列表中选择一个网站: