ClassificationPartitionedECOC
交叉验证多类ECOC模型支持向量机(svm)和其他分类器金宝app
描述
ClassificationPartitionedECOC是一组在交叉验证折叠上训练的纠错输出码(ECOC)模型。通过使用一个或多个“kfold”函数来评估交叉验证分类的质量:kfoldPredict,kfoldLoss,kfoldMargin,kfoldEdge,kfoldfun.
每个“kfold”方法都使用在训练折叠(折叠内)观测上训练的模型来预测验证折叠(折叠外)观测的响应。例如,假设使用五次折叠进行交叉验证。在这种情况下,软件将每个观察结果随机分配到五个大小相等的组(大致)。的培训褶皱包含四组(大约4/5的数据),和验证褶皱包含另一组(大约1/5的数据)。在这种情况下,交叉验证的过程如下:
软件训练第一个模型(存储在
CVMdl。训练有素的{1}),使用后四组的观测值,保留第一组的观测值进行验证。软件训练第二个模型(存储在
CVMdl。训练有素的{2})利用第一组和后三组的观察结果。软件保留第二组的观察结果以供验证。该软件以类似的方式处理第三、第四和第五个模型。
如果您通过使用验证kfoldPredict,该软件计算组内观测结果的预测我通过使用我模型。简而言之,该软件通过使用在没有该观察的情况下训练的模型来估计每个观察的响应。
创建
您可以创建ClassificationPartitionedECOC建模方法有两种:
属性
对象的功能
收集 |
收集属性统计和机器学习工具箱来自GPU的对象 |
kfoldEdge |
交叉验证ECOC模型的分类边缘 |
kfoldLoss |
交叉验证ECOC模型的分类损失 |
kfoldMargin |
交叉验证ECOC模型的分类边际 |
kfoldPredict |
在交叉验证的ECOC模型中对观测数据进行分类 |
kfoldfun |
使用交叉验证ECOC模型的交叉验证函数 |
例子
交叉验证ECOC分类器
对ECOC分类器与SVM二元学习器进行交叉验证,并估计广义分类误差。
加载费雪的虹膜数据集。指定预测器数据X以及响应数据Y.
负载fisheririsX = meas;Y =物种;rng (1);%用于再现性
创建SVM模板,并标准化预测器。
t = templateSVM(“标准化”,真正的)
t =拟合分类支持向量机模板。Alpha: [0x1 double] BoxConstraint: [] CacheSize: [] CachingMethod: " ClipAlphas: [] DeltaGradientTolerance: [] Epsilon: [] GapTolerance: [] kkttolance: [] IterationLimit: [] KernelFunction: " KernelScale: [] KernelOffset: [] kernelpoliialorder: [] NumPrint: [] Nu: [] OutlierFraction: [] removeduplicate: [] ShrinkagePeriod: [] Solver: " StandardizeData: 1 SaveSupportVe金宝appctors: [] VerbosityLevel: [] Version: 2 Method: 'SVM' Type: 'classification'
t为支持向量机模板。大多数模板对象属性是空的。在训练ECOC分类器时,软件将适用的属性设置为默认值。
训练ECOC分类器,并指定分类顺序。
Mdl = fitcecoc(X,Y,“学习者”t...“类名”, {“setosa”,“多色的”,“virginica”});
Mdl是一个ClassificationECOC分类器。您可以使用点表示法访问它的属性。
旨在Mdl使用10倍交叉验证。
CVMdl = crossval(Mdl);
CVMdl是一个ClassificationPartitionedECOC交叉验证ECOC分类器。
估计广义分类误差。
genError = kfoldLoss(cvdl)
genError = 0.0400
广义分类误差为4%,说明ECOC分类器泛化效果较好。
使用宾宁和并行计算加速训练ECOC分类器
训练一个单一对所有的ECOC分类器GentleBoost具有代理分割的决策树集合。为了加快训练速度,将数值预测器放入垃圾箱,并使用并行计算。Binning仅在以下情况有效fitcecoc使用树学习器。训练结束后,使用10倍交叉验证估计分类误差。注意,并行计算需要并行计算工具箱™。
加载样例数据
装载和检查心律失常数据集。
负载心律失常[n,p] = size(X)
N = 452
P = 279
isLabels =唯一的(Y);nLabels = number (isLabels)
nLabels = 13
汇总(分类(Y))
数值计数百分比1 245 54.20% 2 44 9.73% 3 15 3.32% 4 15 3.32% 5 13 2.88% 6 25 5.53% 73 0.66% 8 2 0.44% 99 1.99% 10 50 11.06% 14 4 0.88% 15 5 1.11% 16 22 4.87%
数据集包含279的预测因子和样本量452相对较小。在16个不同的标签中,只有13个在响应中表示(Y).每个标签描述了不同程度的心律失常,54.20%的观察是在课堂上进行的1.
训练一对全ECOC分类器
创建集成模板。您必须指定至少三个参数:一个方法、若干个学习器和学习器的类型。对于本例,请指定“GentleBoost”对于这个方法,One hundred.对于学习者的数量,以及使用代理分割的决策树模板,因为存在缺失的观察。
树= templateTree(“代孕”,“上”);tEnsemble =模板集成(“GentleBoost”, 100年,tTree);
tEnsemble模板对象。它的大部分属性都是空的,但在训练期间,软件会用默认值填充它们。
使用决策树集合作为二叉学习器来训练一个单一对所有ECOC分类器。为了加快训练速度,可以使用宾箱和并行计算。
装箱(
“NumBins”,50岁) -当你有一个大的训练数据集,你可以通过使用加速训练(潜在的准确性下降)“NumBins”名称-值对参数。此论点仅当fitcecoc使用树学习器。如果您指定“NumBins”值,然后软件将每个数值预测器放入指定数量的等概率容器中,然后在容器索引上生长树,而不是原始数据。你可以试试“NumBins”,50岁先改,再改“NumBins”值取决于准确性和训练速度。并行计算(
“选项”,statset (UseParallel,真的)-使用并行计算工具箱许可证,您可以通过使用并行计算来加快计算速度,它将每个二进制学习器发送给池中的工作器。worker的数量取决于您的系统配置。当你对二叉学习器使用决策树时,fitcecoc并行训练使用英特尔®线程构建块(TBB)双核及以上系统。因此,指定“UseParallel”选项在单台计算机上没有帮助。在集群上使用此选项。
此外,指定先验概率为1/K,在那里K= 13是不同类的数量。
选项= statset(“UseParallel”,真正的);Mdl = fitcecoc(X,Y,“编码”,“onevsall”,“学习者”tEnsemble,...“之前”,“统一”,“NumBins”, 50岁,“选项”、选择);
使用“本地”配置文件启动并行池(parpool)…连接到并行池(工人数:6)。
Mdl是一个ClassificationECOC模型。
交叉验证
使用10倍交叉验证交叉验证ECOC分类器。
CVMdl = crossval(Mdl,“选项”、选择);
警告:一个或多个折叠不包含所有组中的点。
CVMdl是一个ClassificationPartitionedECOC模型。该警告表明,当软件至少训练一次时,某些类没有被表示。因此,这些折叠不能预测缺失类的标签。可以使用单元格索引和点表示法检查折叠的结果。例如,通过输入访问第一次折叠的结果CVMdl。训练有素的{1}.
使用交叉验证的ECOC分类器来预测验证折叠标签。计算混淆矩阵的方法为confusionchart.通过更改内部位置属性来移动图表并调整其大小,以确保百分比显示在行摘要中。
oolabel = kfoldPredict(cvdl,“选项”、选择);ConfMat =混淆表(Y, oolabel,“RowSummary”,“total-normalized”);ConfMat。InnerPosition = [0.10 0.12 0.85 0.85];
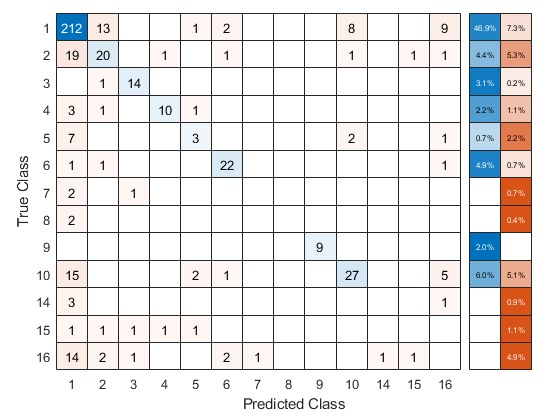
复制二进制数据
方法重新生成已分箱的预测器数据BinEdges属性离散化函数。
X = Mdl.X;预测数据Xbinned = 0(大小(X));edges = mld . binedges;查找已分类预测符的索引。idxNumeric = find(~cellfun(@isempty,edges));如果iscolumn(idxNumeric) idxNumeric = idxNumeric';结束为j = idxNumeric x = x (:,j);如果x是一个表,则将x转换为数组。如果stable(x) x = table2array(x);结束使用离散化函数将x分组到箱子中。Xbinned =离散化(x,[-inf;边缘{};正]);Xbinned(:,j) = Xbinned;结束
Xbinned包含数值预测器的容器索引,范围从1到容器数。Xbinned值是0对于分类预测器。如果X包含南S,然后是对应的Xbinned值是南年代。
扩展功能
您也可以从以下列表中选择一个网站:
