fscchi2
使用卡方检验进行单变量特征排序分类
语法
描述
idx= fscchi2 (资源描述,ResponseVarName)资源描述包含预测变量和响应变量,以及ResponseVarName响应变量的名称在吗资源描述。函数返回idx,其中包含按预测因子重要性排序的预测因子指标,即idx (1)是指数最重要的预测指标。你可以使用idx为分类问题选择重要的预测因子。
例子
矩阵中的秩预测器
在数值矩阵中排列预测因子,并创建预测因子重要性分数的条形图。
加载样例数据。
负载电离层
电离层包含预测变量(X)和响应变量(Y).
使用卡方检验对预测因子进行排序。
[idx,scores] = fscchi2(X,Y);
中的值分数是负对数吗p值。如果一个p-value小于每股收益(0),则对应的得分值为正。在创建条形图之前,确定是否分数包括正值。
找到(isinf(分数)
Ans = 1x0空双行向量
分数不包括正值。如果分数包括正值,可以替换正通过一个大的数字,然后创建一个条形图,以实现可视化的目的。详细信息请参见在表中排名预测器。
创建预测器重要性分数的条形图。
栏(分数(idx))包含(“预测排名”) ylabel (“预测者重要性评分”)
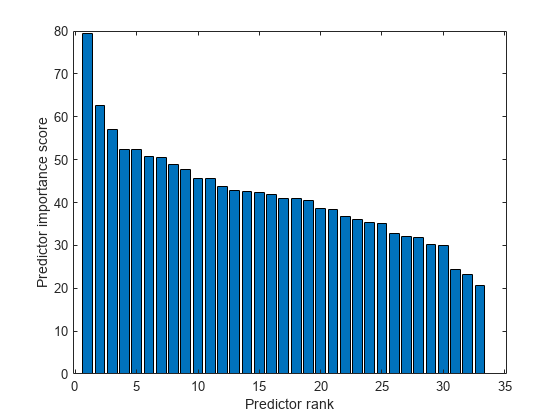
选择前五个最重要的预测因素。找到这些预测因子的列X。
idx (1:5)
ans =1×55 7 3 8 6
第五列X最重要的预测因素是什么Y。
在表中排名预测器
在表格中对预测因子排序,并创建预测因子重要性分数的条形图。
如果数据在一个表中fscchi2对表中的变量子集进行排序,然后函数仅使用该子集对变量进行索引。因此,一个好的实践是将您不希望排列的预测器移动到表的末尾。移动响应变量和观察权重向量。然后,输出参数的索引与表的索引一致。
加载census1994数据集。
负载census1994
表adultdata在census1994包含美国人口普查局的人口数据,以预测一个人的年收入是否超过5万美元。显示表的前三行。
头(adultdata, 3)
ans =3×15表年龄workClass fnlwgt教育education_num marital_status种族职业关系性capital_gain capital_loss hours_per_week native_country薪水 ___ ________________ __________ _________ _____________ __________________ _________________ _____________ _____ ____ ____________ ____________ ______________ ______________ ______ 39 State-gov 77516单身汉13未婚Adm-clerical家族的白人男性2174 0 40美国< = 50 k 50 Self-emp-not-inc 83311单身汉13已婚-公民-配偶-行政-管理-丈夫-白人男性0 0 13美国<=50K 38二等兵2.1565e+05 hs -毕业生9离婚处理人-清洁工没有家庭的白人男性0 0 40美国<=50K
在表格中adultdata,第三列fnlwgt是样本的权重,和最后一列工资是响应变量。移动fnlwgt在的左边工资通过使用movevars函数。
成人数据= movevars(成人数据,“fnlwgt”,“之前”,“工资”);头(adultdata, 3)
ans =3×15表种族性别年龄workClass教育education_num marital_status职业关系capital_gain capital_loss hours_per_week native_country fnlwgt薪水 ___ ________________ _________ _____________ __________________ _________________ _____________ _____ ____ ____________ ____________ ______________ ______________ __________ ______ 39 State-gov单身汉13未婚Adm-clerical家族的白人男性2174 0 77516美国< = 50 k 50 Self-emp-not-inc单身汉13已婚-公民-配偶-行政-管理-丈夫-白人男性0 0 13美国83311 <=50K 38私人hs -毕业生9离婚处理-清洁工-非家庭白人男性0 0 40美国2.1565e+05 <=50K
对预测因子进行排序adultdata。指定列工资作为响应变量,并指定列fnlwgt作为观察权重。
[idx,scores] = fscchi2(成人数据,“工资”,“重量”,“fnlwgt”);
中的值分数是负对数吗p值。如果一个p-value小于每股收益(0),则对应的得分值为正。在创建条形图之前,确定是否分数包括正值。
idxInf = find(isinf(scores))
idxInf =1×81 3 4 5 6 7 10 12
分数包括八个正值。
创建一个预测器重要性分数的条形图。的预测器名称x-轴标记标签。
图形栏(scores(idx))“预测排名”) ylabel (“预测者重要性评分”) xticklabels (strrep (adultdata.Properties.VariableNames (idx),“_”,“\ _”) xtickangle (45)
的酒吧函数不为正值。为正值,与最大有限分数具有相同长度的图条。
持有在酒吧(分数(idx(长度(idxInf) + 1) *(长度(idxInf), 1))传说(“有限的分数”,“正分数”)举行从
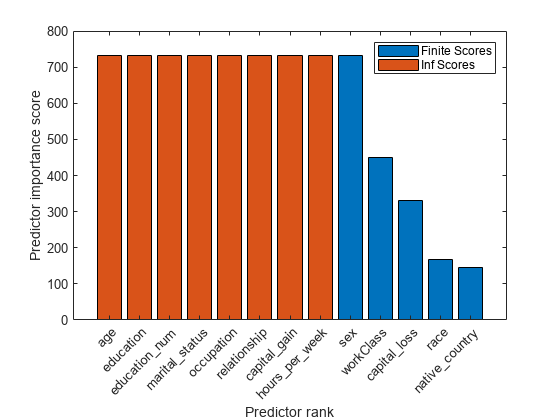
条形图使用不同的颜色显示有限分数和Inf分数。
输入参数
输出参数
算法
版本历史
您也可以从以下列表中选择一个网站: