使用贝叶斯优化优化分类器
这个例子展示了如何优化SVM分类使用fitcsvm函数和优化超参数名称-值参数。
生成数据
分类工作在一个高斯混合模型的点的位置。在统计学习的要素,Hastine,Tibshirani和Friedman(2009),第17页描述了该模型。该模型首先为一个“绿色”类生成10个基点,作为平均值(1,0)和单位方差的二维独立正态分布。它还为“红色”类生成10个基点,作为平均值(0,1)和单位方差的二维独立正态分布。对于每个类(绿色和红色),生成100个随机点,如下所示:
选择一个基点M适当的颜色均匀随意。
生成一个独立的具有二维正态分布的随机点M方差I/5,其中I是2 × 2单位矩阵。在本例中,使用方差I/50来更清楚地显示优化的优势。
为每个类生成10个基点。
rng (“默认”)%的再现性grnpop = mvnrnd((1,0)、眼睛(2),10);redpop = mvnrnd([0, 1],眼(2),10);
查看基点。
地块(grnpop(:,1),grnpop(:,2),“开始”)举行在情节(redpop (: 1) redpop (:, 2),“罗”)举行从
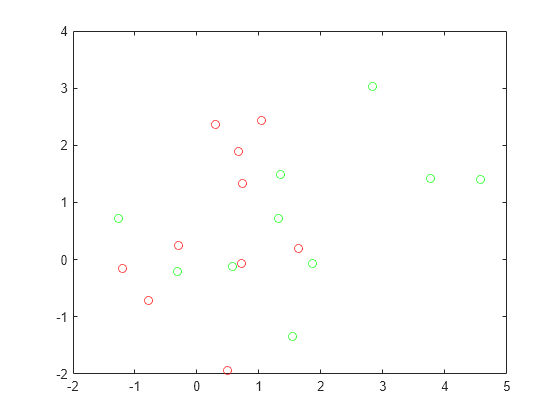
由于一些红色的基准点与绿色的基准点很接近,单凭位置很难对数据点进行分类。
生成每个类的100个数据点。
redpts = 0 (100 2);grnpts = redpts;为i=1:100 GRNPT(i,:)=mvnrnd(grnpop(randi(10),:),眼睛(2)*0.02);redpts(i,:)=mvnrnd(redpop(randi(10),:),眼睛(2)*0.02);结束
查看数据点。
图绘制(grnpts (: 1), grnpts (:, 2),“开始”)举行在情节(redpts (: 1) redpts (:, 2),“罗”)举行从
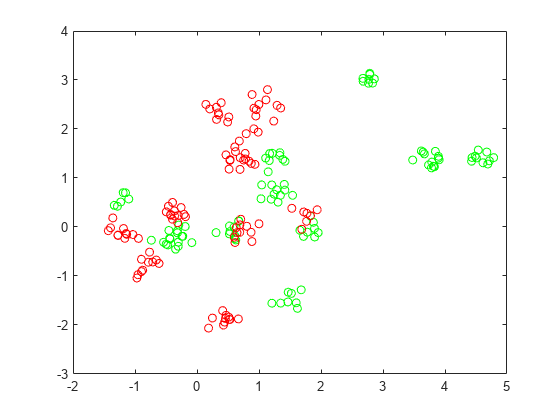
准备分类数据
将数据放入一个矩阵中,并生成一个向量grp标记每个点的类的。1表示绿色等级,-1表示红色等级。
cdata = [grnpts; redpts];grp = 1 (200 1);grp (101:200) = 1;
准备交叉验证
为交叉验证设置分区。
c = cvpartition (200“KFold”10);
此步骤是可选的。如果为优化指定分区,则可以计算返回模型的实际交叉验证损失。
最佳配合
为了找到一个很好的匹配,即具有最优超参数的匹配,以最小化交叉验证损失,可以使用贝叶斯优化。属性指定要优化的超参数列表优化超参数命名值参数,并使用HyperparameterOptimizationOptions名称-值参数。
指定“优化超参数”像“自动”.这个“自动”选项包括一组要优化的典型超参数。fitcsvm的最优值BoxConstraint和KernelScale.设置超参数优化选项以使用交叉验证分区C选择“expected-improvement-plus”再现性的采集功能。默认的采集功能取决于运行时,因此可以给出不同的结果。
选择=结构(“CVPartition”c“AcquisitionFunctionName”,“expected-improvement-plus”);Mdl = fitcsvm (grp cdata,“KernelFunction”,“rbf”,...“优化超参数”,“自动”,“HyperparameterOptimizationOptions”,选项)
|=====================================================================================================| | Iter | Eval客观客观| | | BestSoFar | BestSoFar | BoxConstraint | KernelScale | | |结果| | |运行时(观察)| (estim) | | ||=====================================================================================================| | 最好1 | | 0.345 | 0.29522 | 0.345 | 0.345 | 0.00474 | 306.44 | | 2 |最好| 0.115 | 0.18714 | 0.115 | 0.12678 | 430.31 | 1.4864 | | 3 |接受| 0.52 | 0.27751 | 0.115 | 0.1152 | 0.028415 | 0.014369 | | 4 |接受| 0.61 | 0.297 | 0.115 |0.11504 | 133.94 | 0.0031427 | | 5 |接受| 0.34 | 0.40509 | 0.115 | 0.11504 | 0.010993 | 5.7742 | | 6 |最好| 0.085 | 0.2515 | 0.085 | 0.085039 | 885.63 | 0.68403 | | | 7日接受| 0.105 | 0.25066 | 0.085 | 0.085428 | 0.3057 | 0.58118 | | 8 |接受| 0.21 | 0.26477 | 0.085 | 0.09566 | 0.16044 | 0.91824 | | | 9日接受| 0.085 | 0.23688 | 0.085 |0.08725 | 972.19 | 0.46259 | | 10 | Accept | 0.1 | 0.42455 | 0.085 | 0.090952 | 990.29 | 0.491 | | 11 | Best | 0.08 | 0.35181 | 0.08 | 0.079362 | 2.5195 | 0.291 | | 12 | Accept | 0.09 | 0.2114 | 0.08 | 0.08402 | 14.338 | 0.44386 | | 13 | Accept | 0.1 | 0.20009 | 0.08 | 0.08508 | 0.0022577 | 0.23803 | | 14 | Accept | 0.11 | 0.49489 | 0.08 | 0.087378 | 0.2115 | 0.32109 | | 15 | Best | 0.07 | 0.29763 | 0.07 | 0.081507 | 910.2 | 0.25218 | | 16 | Best | 0.065 | 0.36104 | 0.065 | 0.072457 | 953.22 | 0.26253 | | 17 | Accept | 0.075 | 0.38855 | 0.065 | 0.072554 | 998.74 | 0.23087 | | 18 | Accept | 0.295 | 0.27085 | 0.065 | 0.072647 | 996.18 | 44.626 | | 19 | Accept | 0.07 | 0.31933 | 0.065 | 0.06946 | 985.37 | 0.27389 | | 20 | Accept | 0.165 | 0.27464 | 0.065 | 0.071622 | 0.065103 | 0.13679 | |=====================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | BoxConstraint| KernelScale | | | result | | runtime | (observed) | (estim.) | | | |=====================================================================================================| | 21 | Accept | 0.345 | 0.30824 | 0.065 | 0.071764 | 971.7 | 999.01 | | 22 | Accept | 0.61 | 0.26964 | 0.065 | 0.071967 | 0.0010168 | 0.0010005 | | 23 | Accept | 0.345 | 0.34764 | 0.065 | 0.071959 | 0.0011459 | 995.89 | | 24 | Accept | 0.35 | 0.22277 | 0.065 | 0.071863 | 0.0010003 | 40.628 | | 25 | Accept | 0.24 | 0.46237 | 0.065 | 0.072124 | 996.55 | 10.423 | | 26 | Accept | 0.61 | 0.48664 | 0.065 | 0.072067 | 994.71 | 0.0010063 | | 27 | Accept | 0.47 | 0.20158 | 0.065 | 0.07218 | 993.69 | 0.029723 | | 28 | Accept | 0.3 | 0.17353 | 0.065 | 0.072291 | 993.15 | 170.01 | | 29 | Accept | 0.16 | 0.41714 | 0.065 | 0.072103 | 992.81 | 3.8594 | | 30 | Accept | 0.365 | 0.42269 | 0.065 | 0.072112 | 0.0010017 | 0.044287 |
__________________________________________________________ 优化完成。maxobjective达到30个。总函数计算:30总运行时间:42.6693秒总目标函数计算时间:9.3728BoxConstraint KernelScale _____________ ___________ 953.22 0.26253观测目标函数值= 0.065估计目标函数值= 0.073726函数评估时间= 0.36104最佳估计可行点(根据模型):BoxConstraint KernelScale _____________ ___________ 985.37 0.27389估计的目标函数值= 0.072112估计的函数计算时间= 0.29981
Mdl = ClassificationSVM ResponseName:‘Y’CategoricalPredictors:[]类名:[1]ScoreTransform:“没有一个”NumObservations: 200 HyperparameterOptimizationResults: [1 x1 BayesianOptimization]α:[77 x1双]偏见:-0.2352 KernelParameters: [1 x1 struct] BoxConstraints: x1双[200]ConvergenceInfo: [1 x1 struct] IsSupportVector:金宝app[200x1 logical] Solver: 'SMO'属性,方法
fitcsvm返回一个ClassificationSVM使用最佳估计可行点的模型对象。最佳估计可行点是一组超参数,该超参数使基于贝叶斯优化过程的高斯过程模型的交叉验证损失的上置信界最小。
贝叶斯优化过程内部维持目标函数的高斯过程模型。目标函数为进行分类的交叉验证误分类率。对于每一次迭代,优化过程更新高斯过程模型,并使用该模型寻找一组新的超参数。迭代显示的每一行都显示了新的超参数集和这些列值:
客观的-在新超参数集合处计算的目标函数值。目标运行时-目标函数评估时间。Eval结果—结果报告,指定为接受,最好的或错误.接受表示目标函数返回一个有限值,并且错误指示目标函数返回的值不是有限实标量。最好的指示目标函数返回的有限值低于以前计算的目标函数值。BestSoFar(观察)-迄今为止计算的最小目标函数值。该值是当前迭代的目标函数值(如果Eval结果值为最好的)或者前一个的值最好的迭代。BestSoFar (estim)。-在每次迭代中,软件使用更新的高斯过程模型,在迄今为止尝试的所有超参数集上估计目标函数值的置信上界。然后软件选择置信上界最小的点BestSoFar (estim)。函数返回的目标函数值predictObjective函数在最小点处。
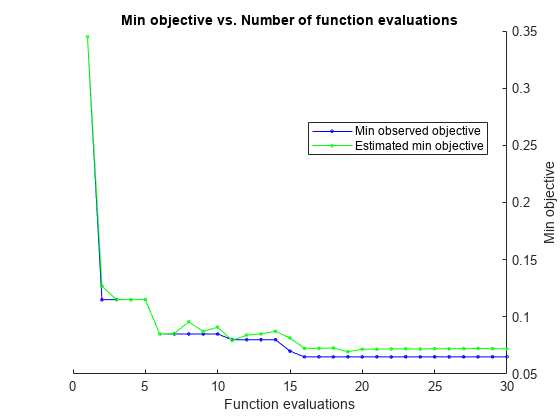
迭代显示下面的图显示了BestSoFar(观察)和BestSoFar (estim)。值分别以蓝色和绿色显示。
返回的对象Mdl使用估计的最佳可行点,即超参数集,产生BestSoFar (estim)。基于最终高斯过程模型的最终迭代中的值。
你可以从超参数优化结果属性或使用最佳点函数。
Mdl.HyperparameterOptimizationResults.XAtMinEstimatedObjective
ans =1×2表BoxConstraint KernelScale _____________ ___________ 985.37 - 0.27389
[x, CriterionValue迭代]= bestPoint (Mdl.HyperparameterOptimizationResults)
x =1×2表BoxConstraint KernelScale _____________ ___________ 985.37 - 0.27389
CriterionValue = 0.0888
迭代= 19
默认情况下,最佳点函数使用“min-visited-upper-confidence-interval”标准。该准则选择第19次迭代得到的超参数作为最佳点。CriterionValue为最终高斯过程模型计算的交叉验证损失的上界。通过使用分区计算实际的交叉验证损失C.
L_MinEstimated = kfoldLoss (fitcsvm (grp cdata,“CVPartition”c“KernelFunction”,“rbf”,...“BoxConstraint”,x.BoxConstraint,“KernelScale”, x.KernelScale))
L_MinEstimated=0.0700
实际交叉验证的损失接近估计值估计目标函数值显示在优化结果图的下方。
您还可以提取观察到的最佳可行点(即最后一个)最好的点在迭代显示)从超参数优化结果属性或通过指定标准像“min观察到”.
Mdl.HyperparameterOptimizationResults.XAtMinObjective
ans =1×2表BoxConstraint KernelScale _____________ ___________ 953.22 - 0.26253
[x_观察到的,标准值_观察到的,迭代_观察到的]=最佳点(Mdl.HyperparameterOptimizationResults,“标准”,“min观察到”)
x_observed =1×2表BoxConstraint KernelScale _____________ ___________ 953.22 - 0.26253
观察到的标准值=0.0650
iteration_observed = 16
这个“min观察到”准则选择从第16次迭代中获得的超参数作为最佳点。观察到的标准值是使用选定的超参数计算的实际交叉验证损失。有关更多信息,请参阅标准名称-值参数最佳点.
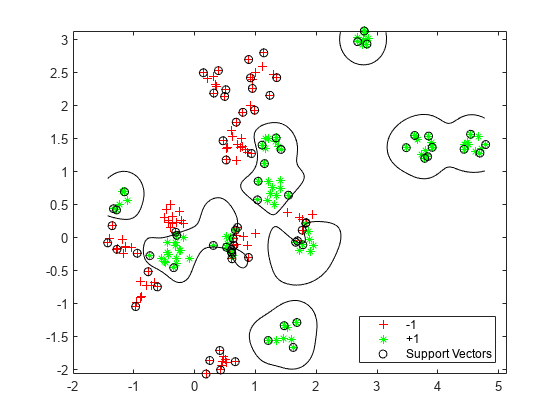
可视化优化的分类器。
d = 0.02;[x1Grid, x2Grid] = meshgrid (min (cdata (: 1)): d:马克斯(cdata (: 1)),...分钟(cdata (:, 2)): d:马克斯(cdata (:, 2)));xGrid = [x1Grid (:), x2Grid (:));[~,分数]=预测(Mdl xGrid);图h (1:2) = gscatter (cdata (: 1), cdata (:, 2), grp,“rg”,' + *’);持有在h(3) =情节(cdata (Mdl.IsSu金宝apppportVector, 1),...cdata (Mdl.I金宝appsSupportVector, 2),“柯”);轮廓(x1Grid x2Grid,重塑(分数(:,2),大小(x1Grid)), [0 0),“k”);传奇(h, {' 1 ',“+ 1”,“金宝app支持向量”},“位置”,‘东南’);
评估新数据的准确性
生成和分类新的测试数据点。
grnobj = gmdistribution (grnpop。2 *眼(2));redobj = gmdistribution (redpop。2 *眼(2));newData =随机(grnobj 10);newData = [newData;随机(redobj 10)];grpData = 1(20日1);% green = 1grpData (11) = 1;% red = -1v =预测(Mdl newData);
计算测试数据集的误分类率。
L_Test =损失(Mdl newData grpData)
L_测试=0.3500
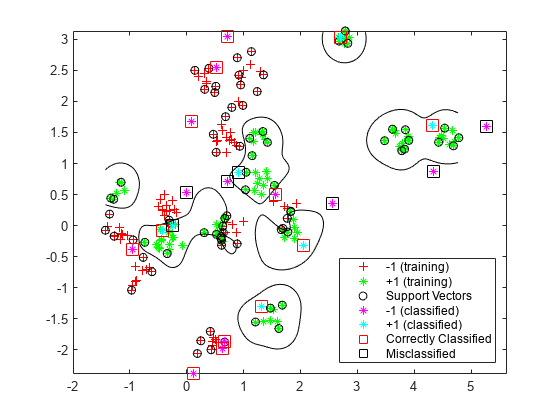
确定哪些新数据点被正确分类。将正确分类的点用红色方格表示,错误分类的点用黑色方格表示。
h (4:5) = gscatter (newData (: 1), newData (:, 2), v,“mc”,“* *”);mydiff = (v == grpData);%正确分类为2 = mydiff%在正确的点周围绘制红色方块h(6) =情节(newData (ii, 1), newData (ii, 2),“rs”,“MarkerSize”12);结束为2 =不(mydiff)%在不正确的pts周围绘制黑色方框h(7)=绘图(新数据(ii,1),新数据(ii,2),“ks”,“MarkerSize”12);结束传奇(h, {“-1(培训)”,“+1(培训)”,“金宝app支持向量”,...“-1(已分类)”,“+1(已分类)”,...“正确分类”,“是不是”},...“位置”,‘东南’);持有从
另见
相关的话题
你也可以从以下列表中选择一个网站:
