使用i向量的说话人验证
说话人验证或身份验证是确认说话人的身份是他们声称的那个人的任务。说话人验证多年来一直是一个活跃的研究领域。早期的性能突破是使用高斯混合模型和通用背景模型(GMM-UBM)。[1]关于声学特征(通常)mfcc)。使用示例请参见基于高斯混合模型的说话人验证。GMM-UBM系统的主要困难之一涉及会话间的可变性。联合因子分析(Joint factor analysis, JFA)通过分别模拟说话人间的变异和信道或会话的变异来补偿这种变异[2][3]。然而,[4]发现JFA中的通道因子也包含了关于说话人的信息,并提出将通道和说话人空间组合成一个总变化空间。然后通过使用后端程序(如线性判别分析(LDA)和类内协方差归一化(WCCN))来补偿会话间的可变性,然后进行评分,如余弦相似度评分。[5]提出用概率LDA (PLDA)模型代替余弦相似度评分。[11]和[12]提出了一种在PLDA中对i向量进行高斯化处理从而做出高斯假设的方法,称为G-PLDA或简化PLDA。虽然i向量最初是为说话人验证而提出的,但它们已经应用于许多问题,如语言识别、说话人拨号、情绪识别、年龄估计和反欺骗[10]。最近,有人提出用深度学习技术来代替i向量d-vectors或x-vectors[8][6]。
使用i-Vector系统
Audio Toolbox提供ivectorSystem它封装了训练i-vector系统,注册演讲者或其他音频标签,评估系统的决策阈值,以及识别或验证演讲者或其他音频标签的能力。看到ivectorSystem使用此特性并将其应用于多个应用程序的示例。
要了解有关i-vector系统如何工作的更多信息,请继续下面的示例。
开发i-Vector系统
在本例中,您将开发一个用于说话人验证的标准i向量系统,该系统使用带有余弦相似度评分或G-PLDA评分的LDA-WCCN后端。
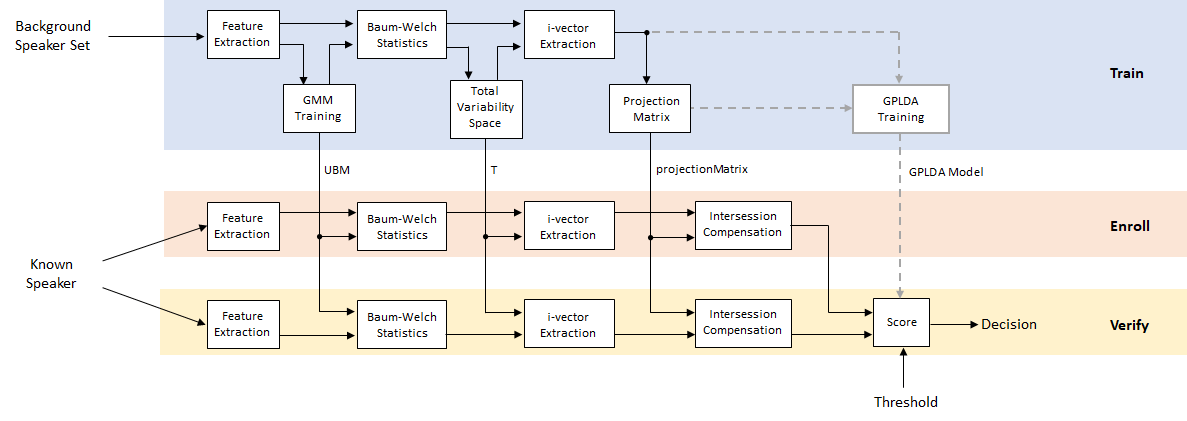
在整个示例中,您将发现可调参数上的活动控件。更改控件不会重新运行示例。如果更改控件,则必须重新运行示例。
数据集管理
这个例子使用了格拉茨科技大学的音调跟踪数据库(PTDB-TUG)。[7]。该数据集由20名英语母语人士阅读来自TIMIT语料库的2342个语音丰富的句子组成。下载并提取数据集。根据您的系统,下载和提取数据集可能需要大约1.5小时。
url =“https://www2.spsc.tugraz.at/databases/PTDB-TUG/SPEECH_DATA_ZIPPED.zip”;downloadFolder = tempdir;datasetFolder = fullfile(下载文件夹,“PTDB-TUG”);如果~ datasetExists datasetFolder disp (“下载PTDB-TUG (3.9 G)…”解压缩(url, datasetFolder)结束
创建一个audioDatastore对象,该对象指向数据集。该数据集最初用于音高跟踪训练和评估,包括喉镜读数和基线音高决策。请只使用原始录音。
ads = audioDatastore([fullfile(datasetFolder),“语音数据”,“女性”,“麦克风”), fullfile (datasetFolder,“语音数据”,“男性”,“麦克风”)),…IncludeSubfolders = true,…FileExtensions =“wav”);filename = ads.Files;
文件名包含说话人的id。解码文件名以设置上的标签audioDatastore对象。
speakerIDs = extractBetween(文件名,“mic_”,“_”);ads.Labels = categorical(speakerIDs);countEachLabel(广告)
ans =20×2表标签计数_____ _____ F01 236 F02 236 F03 236 F04 236 F05 236 F06 236 F07 236 F08 234 F09 236 F10 236 M01 236 M02 236 M03 236 M04 236 M05 236 M06 236
分离audioDatastore对象分为训练集、评估集和测试集。训练集包含16个演讲者。评估集包含四个说话人,并进一步分为注册集和评估训练后的i向量系统的检测误差权衡的集,以及测试集。
developmentLabels = categorical([“M01”,“M02”,“M03”,“M04”,“M06”,“M07”,“M08”,“M09”,“F01”,“F02”,“F03”,“F04”,“F06”,“F07”,“F08”,“F09”]);evaluationLabels = categorical([“M05”,“M10”,“F05”,“F10”]);adsTrain =子集(ads,ismember(ads. labels,developmentLabels));adsEvaluate =子集(ads,ismember(ads. labels,evaluationLabels));numFilesPerSpeakerForEnrollment =3.;[adsEnroll,adsTest,adsDET] = splitEachLabel(adsEvaluate,numFilesPerSpeakerForEnrollment,2);

显示结果的标签分布audioDatastore对象。
countEachLabel (adsTrain)
ans =16×2表标签数量_____ _____ F01 236 F02 236 F03 236 F04 236 F06 236 F07 236 F08 234 F09 236 M01 236 M02 236 M03 236 M04 236 M06 236 M07 236 M08 236 M09 236
countEachLabel (adsEnroll)
ans =4×2表标签计数_____ _____ F05 3 F10 3 M05 3 M10 3
countEachLabel (adsDET)
ans =4×2表标签计数_____ _____ F05 231 F10 231 M05 231 M10 231
countEachLabel (adsTest)
ans =4×2表标签计数_____ _____ F05 2 F10 2 M05 2 M10 2
从训练数据集中读取音频文件,听它,并绘制它。重置数据存储。
[audio,audioInfo] = read(adsTrain);fs = audioInfo.SampleRate;T = (0:size(audio,1)-1)/fs;Sound (audio,fs) plot(t,audio) xlabel(“时间(s)”) ylabel (“振幅”)轴([0 t(end) -1 1])“来自训练集的话语样本”)

重置(adsTrain)
您可以减少本示例中使用的数据集和参数数量,以牺牲性能为代价加快运行时速度。一般来说,减少数据集是开发和调试的良好实践。
speedUpExample =假;如果adsTrain = splitEachLabel(adsTrain,30);adsDET = splitEachLabel(adsDET,21);结束

特征提取
创建一个audioFeatureExtractor目的提取20个mfc、20个delta- mfc和20个delta-delta mfc。使用增量窗口长度为9。以10毫秒的跳跃从25毫秒的Hann窗口中提取特征。
numCoeffs =20.;deltaWindowLength =
9;windowDuration =
0.025;hopDuration =
0.01;windowSamples = round(windowDuration*fs);hopSamples = round(hopDuration*fs);overlapSamples = windowSamples - hopSamples;afe = audioFeatureExtractor(…SampleRate = fs,…窗口=损害(windowSamples,“周期”),…OverlapLength = overlapSamples,……mfcc = true,…mfccDelta = true,…mfccDeltaDelta = true);setExtractorParameters (afe“mfcc”DeltaWindowLength = DeltaWindowLength NumCoeffs = NumCoeffs)




从训练数据存储中读取的音频中提取特征。特性返回为numHops——- - - - - -numFeatures矩阵。
feature = extract(afe,audio);[numHops,numFeatures] = size(features)
numHops = 797
numFeatures = 60
培训
训练一个i向量系统在计算上是昂贵且耗时的。如果您有Parallel Computing Toolbox™,您可以将工作分散到多个核心上,以加快示例的速度。确定系统的最佳分区数量。如果您没有Parallel Computing Toolbox™,请使用单个分区。
如果~ isempty(版本(“平行”)) && ~speedUpExample pool = gcp;numPar = numpartitions(adsTrain,pool);其他的numPar = 1;结束
使用“本地”配置文件启动并行池(parpool)…连接到并行池(工人数量:6)。
特征归一化因子
使用辅助函数,helperFeatureExtraction,从数据集中提取所有特征。的helperFeatureExtraction函数从音频中的语音区域提取MFCC。语音检测由detectSpeech函数。
featureall = {};抽搐parfor(1); (1); (2);featuresPart = cell(0,numel(adsPart.Files));为iii = 1:numel(adsPart. files) audioData = read(adsPart);featuresPart{iii} = helperFeatureExtraction(audioData,afe,[]);结束featuresAll = [featuresAll,featuresPart];结束allFeatures = cat(2,featuresAll{:});disp ("训练集特征提取完成("+ toc +“秒)。”)
训练集特征提取完成(64.0731秒)。
计算每个特征的全局均值和标准差。类的调用中将使用这些helperFeatureExtraction函数对特征进行规范化。
normFactors。米ean = mean(allFeatures,2,“omitnan”);normFactors。年代TD = std(allFeatures,[],2,“omitnan”);
通用背景模型(UBM)
初始化高斯混合模型(GMM),它将成为i-vector系统中的通用背景模型(UBM)。组件权重初始化为均匀分布。在TIMIT数据集上训练的系统通常包含大约2048个组件。
numComponents =64;如果numComponents = 32;结束alpha = ones(1,numComponents)/numComponents;mu = randn(numFeatures,numComponents);vari = rand(numFeatures,numComponents) + eps;ubm = struct(ComponentProportion=alpha,mu=mu,sigma=vari);

使用期望最大化(EM)算法训练UBM。
麦克斯特=10;如果maxIter = 2;结束抽搐为iter = 1:maxIter%的期望N = 0 (1,numComponents);F = 0 (numFeatures,numComponents);S = 0 (numFeatures,numComponents);L = 0;parfor(1); (1); (2);而hasdata(adsPart) audioData = read(adsPart)%提取功能Y = helperFeatureExtraction(audioData,afe,normFactors);计算后验对数似然logLikelihood = helperGMMLogLikelihood(Y,ubm);计算后验归一化概率amax = max(logLikelihood,[],1);loglikelihood = amax + log(sum(exp(logLikelihood-amax),1));gamma = exp(logLikelihood - loglikehoodsum)';%计算鲍姆-韦尔奇统计N = sum(gamma,1);f = Y *;s = (Y *Y) * gamma;更新话语的足够统计数据N = N + N;F = F + F;S = S + S;%更新日志可能性L = L + sum(loglikehoodsum);结束结束%打印当前日志可能性disp (“培训UBM:”+ iter +“/”+ maxIter +"完成("+圆(toc) +, Log-likelihood = "+圆(L))%最大化N = max(N,eps);于是。ComponentProportion = max(N/sum(N),eps); ubm.ComponentProportion = ubm.ComponentProportion/sum(ubm.ComponentProportion); ubm.mu = F./N; ubm.sigma = max(S./N - ubm.mu.^2,eps);结束

训练UBM: 1/10完成(57秒),Log-likelihood = -75180473训练UBM: 2/10完成(57秒),Log-likelihood = -75115244训练UBM: 3/10完成(57秒),Log-likelihood = -75064164训练UBM: 4/10完成(57秒),Log-likelihood = -75024270训练UBM: 5/10完成(57秒),Log-likelihood = -74994504训练UBM: 6/10完成(57秒),Log-likelihood = -74970605训练UBM: 7/10完成(55秒),Log-likelihood = -74950526训练UBM:8/10完成(58秒),Log-likelihood = -74933181训练UBM: 9/10完成(58秒),Log-likelihood = -74917145训练UBM: 10/10完成(55秒),Log-likelihood = -74901292
计算鲍姆-韦尔奇统计
鲍姆-韦尔奇统计数据是N(零阶)和FEM算法中使用的(一阶)统计量,使用最终的UBM计算。
特征向量在时间点上吗 。
,在那里 是发言人数。为了训练总可变性空间,每个音频文件被认为是一个单独的扬声器(无论它是否属于物理上的单个扬声器)。
是UBM分量的后验概率 说明特征向量 。
计算训练集上的零阶和一阶Baum-Welch统计量。
numSpeakers = numel(adsTrain.Files);Nc = {};Fc = {};抽搐parfor(1); (1); (2);numFiles = numel(adsPart.Files);Npart = cell(1,numFiles);Fpart = cell(1,numFiles);为jj = 1:numFiles audioData = read(adsPart);%提取功能Y = helperFeatureExtraction(audioData,afe,normFactors);计算后验对数似然logLikelihood = helperGMMLogLikelihood(Y,ubm);计算后验归一化概率amax = max(logLikelihood,[],1);loglikelihood = amax + log(sum(exp(logLikelihood-amax),1));gamma = exp(logLikelihood - loglikehoodsum)';%计算鲍姆-韦尔奇统计N = sum(gamma,1);f = Y *;Npart{jj} =重塑(n,1,1,numComponents);Fpart{jj} = shape(f,numFeatures,1,numComponents);结束Nc = [Nc,Npart];Fc = [Fc,Fpart];结束disp ("鲍姆-韦尔奇统计数据已完成("+ toc +“秒)。”)
鲍姆-韦尔奇统计完成(57.5179秒)。
将统计数据展开为矩阵并居中 ,如[3],这样
是一个 对角矩阵,其块为 。
是一个 通过连接获得的超向量 。
为UBM中组件的数量。
是特征向量中特征的个数。
N = Nc;F = Fc;多=重塑(ubm.mu,numFeatures,1,[]);为N{s} = reelem(重塑(Nc{s},1,[]),numFeatures);F{s} = (Fc{s} - Nc{s}.*muc,[],1);结束
因为这个例子假设了UBM的对角协方差矩阵,N也是对角矩阵,并保存为矢量以便高效计算。
总变异空间
在i向量模型中,理想的说话人超向量由一个说话人无关分量和一个说话人相关分量组成。说话人相关分量由总变异性空间模型和说话人的i向量组成。
说话者的话语是超向量吗
是与说话者和信道无关的超向量,可以取为UBM超向量。
是一个低秩矩形矩阵,表示总变异性子空间。
是说话者的i向量吗
向量i的维数, ,通常比C - F维说话者话语超向量低得多,这使得i-向量或i-向量成为更紧凑和易于处理的表示。
为了训练总的可变性空间,
,首先随机初始化T,然后迭代地执行这些步骤[3]:
计算隐变量的后验分布。
2.收集演讲者的统计数据。
3.更新总可变性空间。
[3]提出初始化 通过UBM方差,然后更新 根据公式:
其中S(S)为居中二阶Baum-Welch统计量。然而,更新 在实践中经常被放弃,因为它没有什么效果。此示例不更新 。
创建变量。
Sigma = ubm.sigma(:);
指定总可变性空间的维度。用于TIMIT数据集的典型值是1000。
numTdim =32;如果numTdim = 16;结束

初始化T单位矩阵,以及预分配单元阵列。
T = randn(nummel (ubm.sigma),numTdim);T = T/norm(T);I = eye(numTdim);Ey = cell(numSpeakers,1);Eyy = cell(numSpeakers,1);Linv = cell(numSpeakers,1);
设置训练的迭代次数。报告的典型值为20。
numIterations = 5;
5;

运行训练循环。
为iterIdx = 1:表示迭代数% 1。计算隐变量的后验分布TtimesInverseSSdiag = (t /Sigma)';parfors = 1:numSpeakers L = (I + TtimesInverseSSdiag.*N{s}*T);Linv{s} = pinv(L);Ey{s} = Linv{s}*TtimesInverseSSdiag*F{s};y{s} = Linv{s} + y{s}* y{s}';结束% 2。累积演讲者的统计数据Eymat = cat(2,Ey{:});FFmat = cat(2,F{:});Kt = FFmat*Eymat';K = mat2cell(Kt',numTdim, reelem (numFeatures,numComponents));newT = cell(numComponents,1);为c = 1:numComponents AcLocal = 0 (numTdim);为s = 1:numSpeakers AcLocal = AcLocal + Nc{s}(:,:,c)*Eyy{s};结束% 3。更新总可变性空间newT{c} = (pinv(AcLocal)*K{c})';结束T = cat(1,newT{:});disp (“训练总变异空间:”+ iterIdx +“/”+ numIterations +"完成("+ round(toc,2) +“秒)。”)结束
训练总变异性空间:1/5完成(1.97秒)。训练总变异性空间:2/5完成(1.69秒)。训练总变异性空间:3/5完成(1.79秒)。训练总变异性空间:4/5完成(1.56秒)。训练总变异性空间:5/5完成(1.74秒)。
i矢量提取
一旦计算出总可变性空间,就可以将i向量计算为[4]:
在这一点上,您仍然将每个培训文件视为一个单独的演讲者。然而,在下一步中,当你训练一个投影矩阵来降低维数并增加说话者之间的差异时,必须用适当的、不同的说话者id来标记i向量。
创建一个单元格数组,其中单元格数组的每个元素都包含针对特定说话人的跨文件的i向量矩阵。
speakers = unique(adsTrain.Labels);numSpeakers = nummel (speakers);ivectorPerSpeaker = cell(numSpeakers,1);TS = t /Sigma;TSi = TS';ubmMu = ubm.mu;抽搐parforspeakerIdx = 1:numSpeakers将数据存储子集设置为您正在适应的演讲者。adsPart =子集(adsTrain,adsTrain. labels ==speakers(speakerIdx));numFiles = numel(adsPart.Files);ivectorPerFile = 0 (numTdim,numFiles);为fileIdx = 1:numFiles audioData = read(adsPart);%提取功能Y = helperFeatureExtraction(audioData,afe,normFactors);计算后验对数似然logLikelihood = helperGMMLogLikelihood(Y,ubm);计算后验归一化概率amax = max(logLikelihood,[],1);loglikelihood = amax + log(sum(exp(logLikelihood-amax),1));gamma = exp(logLikelihood - loglikehoodsum)';%计算鲍姆-韦尔奇统计N = sum(gamma,1);f = Y * γ - n.*(ubmMu);ivectorPerFile(:,fileIdx) = pinv(I + (TS.*repelem(n(:),numFeatures))' * T) * TSi * f(:);结束ivectorPerSpeaker{speakerIdx} = ivectorPerFile;结束disp (从训练集()中提取的i个向量+ toc +“秒)。”)
从训练集中提取i个向量(65.8347秒)。
投影矩阵
许多不同的后端已经提出了i-vectors。最直接和仍然表现良好的一种是线性判别分析(LDA)和类内协方差归一化(WCCN)的组合。
创建一个训练向量矩阵和一个映射,表示哪个i向量对应于哪个说话者。将投影矩阵初始化为单位矩阵。
w = ivectorPerSpeaker;utterancePerSpeaker = cellfun(@(x)size(x,2),w);ivectorsTrain = cat(2,w{:});projectionMatrix = eye(size(w{1},1));
LDA试图最小化类内方差,最大化说话者之间的方差。它的计算方法如[4]:
鉴于:
在哪里
是每个说话人的i向量的均值。
是所有扬声器i向量的平均值。
为每个说话者的说话次数。
解决最佳特征向量的特征值方程:
最好的特征向量是那些具有最高特征值的向量。
performLDA =真正的;如果performLDA tic nummeigenvectors =
16;Sw = 0 (size(projectionMatrix,1));Sb = 0 (size(projectionMatrix,1));Wbar = mean(cat(2,w{:}),2);为Ii = 1:numel(w) ws = w{Ii};Wsbar = mean(ws,2);(wsbar - wbar)*(wsbar - wbar)';Sw = Sw + cov(ws',1);结束[A,~] = eigs(Sb,Sw,numEigenvectors);A = (A /vecnorm(A))';ivectorsTrain = A * ivectorsTrain;w = mat2cell(ivectorsTrain,size(ivectorsTrain,1),utterancePerSpeaker);projectionMatrix = A * projectionMatrix;disp (LDA投影矩阵计算+ round(toc,2) +“秒)。”)结束


计算LDA投影矩阵(0.22秒)。
WCCN试图将i向量空间与类内协方差反向缩放,以便在i向量比较中不强调高说话人内部可变性的方向[9]。
鉴于类内协方差矩阵:
在哪里
是每个说话人的i向量的均值。
为每个说话者的说话次数。
解决对B采用Cholesky分解:
performWCCN =真正的;如果performWCCN tic alpha =
0.9;W = 0 (size(projectionMatrix,1));为ii = 1:numel(w) w = w + cov(w{ii}',1);结束W = W/numel(W);W = (1 - alpha)*W + alpha*eye(size(W,1));B = chol(pinv(W))“低”);projectionMatrix = B * projectionMatrix;disp (“WCCN投影矩阵计算(”+ round(toc,4) +“秒)。”)结束


计算出WCCN投影矩阵(0.0096秒)。
训练阶段现在已经完成。您现在可以使用通用背景模型(UBM)、总可变性空间(T)和投影矩阵来登记和验证说话者。
训练G-PLDA模型
将投影矩阵应用于列车集。
ivtors = cellfun(@(x)projectionMatrix*x,ivectorPerSpeaker,UniformOutput=false);
在本例中实现的算法是高斯PLDA,概述如下[13]。在高斯PLDA中,i向量用下式表示:
在哪里 是i个向量的全局均值, 是噪声项的全精度矩阵吗 , 是因子加载矩阵,也称为特征声。
指定要使用的特征声音的数量。通常数字在10到400之间。
numEigenVoices = 16;
16;

确定不相交的人的数量,特征向量的维度数量,以及每个说话人的话语数量。
K = numel(向量);D = size(向量{1},1);utterancePerSpeaker = cellfun(@(x)size(x,2),向量);
找出样本总数并将i向量居中。
ivectorsMatrix = cat(2, ivvectors {:});N = size(ivectorsMatrix,2);mu = mean(ivectorsMatrix,2);ivectorsMatrix = ivectorsMatrix - mu;
从训练i-向量中确定一个白化矩阵,然后对i-向量进行白化。可以选择ZCA美白、PCA美白或不美白。
whiteningType =“ZCA”;如果strcmpi (whiteningType“ZCA”) S = cov(ivectorsMatrix');[~,sD,sV] = svd(S);W = diag(1./(sqrt(diag(sD)) + eps))*sV';ivectorsMatrix = W * ivectorsMatrix;elseifstrcmpi (whiteningType“主成分分析”) S = cov(ivectorsMatrix');[sV,sD] = eig(S);W = diag(1./(sqrt(diag(sD)) + eps))*sV';ivectorsMatrix = W * ivectorsMatrix;其他的W = eye(size(ivectorsMatrix,1));结束

应用长度归一化,然后将训练i向量矩阵转换回单元数组。
ivectorsMatrix = ivectorsMatrix./vecnorm(ivectorsMatrix);
计算全局二阶矩为
S = ivectorsMatrix*ivectorsMatrix';
将训练i向量矩阵转换回单元数组。
ivvectors = mat2cell(ivectorsMatrix,D,utterancePerSpeaker);
根据样本数量对人进行排序,然后根据每个说话人的话语数量对i向量进行分组。预先计算的一阶矩 - the person as
uniqueLengths = unique(utterancePerSpeaker);numUniqueLengths = numel(uniqueLengths);speakerIdx = 1;f = 0 (D,K);为uniqueLengthIdx = 1: numuniquelelengths idx = find(utterancePerSpeaker== uniqueLengthIdx));Temp = {};为speakerIdxWithinUniqueLength = 1:num (idx) rho = ivvectors (idx(speakerIdxWithinUniqueLength));Temp = [Temp;rho];% #好< AGROW >f(:,speakerIdx) = sum(rho{:},2);speakerIdx = speakerIdx+1;结束ivectorsSorted{uniqueLengthIdx} = temp;% #好< SAGROW >结束
初始化特征语音矩阵V和逆噪声方差项, 。
V = randn(D,numEigenVoices);Lambda = pinv(S/N);
指定EM算法的迭代次数,以及是否应用最小散度。
numIter =5;minimumDivergence =
真正的;


使用EM算法训练G-PLDA模型[13]。
为iter = 1:numIter%的期望gamma = 0 (numEigenVoices,numEigenVoices);EyTotal = 0 (nummeigenvoices,K);R = 0 (numEigenVoices,numEigenVoices);Idx = 1;为lengthIndex = 1:numUniqueLengths;%分离相同长度的i个向量iv = ivectorsSorted{lengthIndex};%计算MM = pinv(ivectorLength*(V'*(Lambda*V)) + eye(nummeigenvoices));%式(A.7)中的[13]%循环每个扬声器的当前i向量长度为speakerIndex = 1:numel(iv)V的潜在变量的第一矩y = M*V'*Lambda*f(:,idx);%式(A.8)中的[13]%计算第二力矩。Eyy = Ey * Ey';%更新RyyR = R + ivectorLength*(M + y);%式(A.13)中的[13]%追加EyTotalEyTotal(:,idx) = Ey;Idx = Idx + 1;如果使用最小散度,更新伽马值。如果minimumDivergence = γ + (M + Eyy);%式(A.18)中的[13]结束结束结束%计算TTT = EyTotal*f';%式(A.12)中的[13]%最大化V = TT'*pinv(R);%式(A.16)中的[13]Lambda = pinv((S - V*TT)/N);%式(A.17)中的[13]最小散度%如果minimumDivergence = γ /K;%式(A.18)中的[13]V = V*chol(,“低”);%式(A.22)中的[13]结束结束
一旦您训练了G-PLDA模型,您就可以使用它来计算基于对数似然比的分数,如[14]。给定两个被居中、白化和长度归一化的i向量,得分计算为:
在哪里 和 登记和测试是i向量, 是噪声项的方差矩阵, 是特征语音矩阵。的 项是可因式分解的常数,在实践中可以省略。
speakerIdx =2;utteranceIdx =
1;w1 = ivvectors {speakerIdx}(:,utteranceIdx);speakerIdx =
1;utteranceIdx =
10;wt = ivvectors {speakerIdx}(:,utteranceIdx);VVt = V*V';SigmaPlusVVt = pinv(Lambda) + VVt;term1 = pinv([SigmaPlusVVt;VVt]);term2 = pinv(SigmaPlusVVt);W1wt = [w1;wt];得分= w1wt'*term1*w1wt - w1'*term2*w1 - wt'*term2*wt




得分= 56.2336
在实践中,G-PLDA模型的训练中不使用测试i向量,根据您的系统,也不使用登记向量。在下面的评估部分中,您将使用以前未见过的数据进行注册和验证。配套功能金宝app,gpldaScore封装了上面的评分步骤,并额外执行定心、白化和规范化。将训练好的G-PLDA模型保存为结构体,以便与支持函数一起使用金宝appgpldaScore。
gpldammodel = struct(mu=mu,…WhiteningMatrix = W,…EigenVoices = V,…σ= pinv(λ));
招收
招募不在训练数据集中的新演讲者。
使用以下步骤为报名集合中的每个演讲者的每个文件创建i-vector:
特征提取
鲍姆-韦尔奇统计量:确定零阶和一阶统计量
i矢量提取
Intersession补偿
然后对文件中的i向量求平均值,为扬声器创建一个i向量模型。对每个说话者重复上述内容。
speakers = unique(adsEnroll.Labels);numSpeakers = nummel (speakers);registrledspeakersbyidx = cell(numSpeakers,1);抽搐parforspeakerIdx = 1:numSpeakers将数据存储子集设置为您正在适应的演讲者。adsPart =子集(adsEnroll,adsEnroll. labels ==speakers(speakerIdx));numFiles = numel(adsPart.Files);ivectorMat = 0 (size(projectionMatrix,1),numFiles);为fileIdx = 1:numFiles audioData = read(adsPart);%提取功能Y = helperFeatureExtraction(audioData,afe,normFactors);计算后验对数似然logLikelihood = helperGMMLogLikelihood(Y,ubm);计算后验归一化概率amax = max(logLikelihood,[],1);loglikelihood = amax + log(sum(exp(logLikelihood-amax),1));gamma = exp(logLikelihood - loglikehoodsum)';%计算鲍姆-韦尔奇统计N = sum(gamma,1);f = Y * γ - n.*(ubmMu);% i矢量提取w = pinv (I + (TS。* repelem (n (:), numFeatures))的f * T * TSi * (:);会话间补偿%w = projectionMatrix*w;ivectorMat(:, filidx) = w;结束向量模型registrledspeakersbyidx {speakerIdx} = mean(ivectorMat,2);结束disp (“报名的演讲者(”+ round(toc,2) +“秒)。”)
演讲者注册(0.44秒)。
出于记账的目的,将i-vector的单元格数组转换为一个结构,演讲者id作为字段,i-vector作为值
registrledspeakers = struct;为s = 1:numSpeakers registrledspeakers .(string(speakers(s))) = registrledspeakersbyidx {s};结束
验证
指定CSS或G-PLDA评分方法。
scoringMethod = “GPLDA”;
“GPLDA”;

误拒率(FRR)
说话人错误拒绝率(FRR)是给定说话人被错误拒绝的比率。为已登记的演讲者i-向量和同一演讲者的i-向量创建分数数组。
speakersToTest = unique(adsde . labels);numSpeakers = nummel (speakersToTest);scorefr = cell(numSpeakers,1);抽搐parforspeakerIdx = 1:numSpeakers adsPart =子集(adsDET,adsDET. labels ==speakersToTest(speakerIdx));numFiles = numel(adsPart.Files);ivectorToTest = registrledspeakers .(string(speakersToTest(speakerIdx)));% #好< PFBNS >score = 0 (numFiles,1);为fileIdx = 1:numFiles audioData = read(adsPart);%提取功能Y = helperFeatureExtraction(audioData,afe,normFactors);计算后验对数似然logLikelihood = helperGMMLogLikelihood(Y,ubm);计算后验归一化概率amax = max(logLikelihood,[],1);loglikelihood = amax + log(sum(exp(logLikelihood-amax),1));gamma = exp(logLikelihood - loglikehoodsum)';%计算鲍姆-韦尔奇统计N = sum(gamma,1);f = Y * γ - n.*(ubmMu);%提取i向量w = pinv (I + (TS。* repelem (n (:), numFeatures))的f * T * TSi * (:);会话间补偿%w = projectionMatrix*w;%的分数如果strcmpi (scoringMethod“CSS”) score(fileIdx) = dot(ivectorToTest,w)/(norm(w)*norm(ivectorToTest));其他的score(fileIdx) = gpldaScore(gpldammodel,w,ivectorToTest);结束结束scorefr {speakerIdx} =分数;结束disp (FRR计算("+ round(toc,2) +“秒)。”)
FRR计算(20.77秒)。
误取取率(FAR)
说话人错误接受率(FAR)是指不属于已登记说话人的话语被错误地接受为属于已登记说话人的比率。创建已注册演讲者的分数数组和不同演讲者的i向量。
speakersToTest = unique(adsde . labels);numSpeakers = nummel (speakersToTest);scoreFAR = cell(numSpeakers,1);抽搐parforspeakerIdx = 1:numSpeakers adsPart =子集(adsDET,adsDET. labels ~=speakersToTest(speakerIdx));numFiles = numel(adsPart.Files);ivectorToTest = registrledspeakers .(string(speakersToTest(speakerIdx)));% #好< PFBNS >score = 0 (numFiles,1);为fileIdx = 1:numFiles audioData = read(adsPart);%提取功能Y = helperFeatureExtraction(audioData,afe,normFactors);计算后验对数似然logLikelihood = helperGMMLogLikelihood(Y,ubm);计算后验归一化概率amax = max(logLikelihood,[],1);loglikelihood = amax + log(sum(exp(logLikelihood-amax),1));gamma = exp(logLikelihood - loglikehoodsum)';%计算鲍姆-韦尔奇统计N = sum(gamma,1);f = Y * γ - n.*(ubmMu);%提取i向量w = pinv (I + (TS。* repelem (n (:), numFeatures))的f * T * TSi * (:);会话间补偿%w = projectionMatrix * w;%的分数如果strcmpi (scoringMethod“CSS”) score(fileIdx) = dot(ivectorToTest,w)/(norm(w)*norm(ivectorToTest));其他的score(fileIdx) = gpldaScore(gpldammodel,w,ivectorToTest);结束结束scoreFAR{speakerIdx} =得分;结束disp ("FAR计算("+ round(toc,2) +“秒)。”)
FAR计算(58.14秒)。
等错误率(EER)
为了比较多个系统,您需要一个结合FAR和FRR性能的单一度量。为此,需要确定相等错误率(EER),这是FAR和FRR曲线相交的阈值。在实践中,EER阈值可能不是最佳选择。例如,如果将说话人验证作为多身份验证方法的一部分用于电汇,那么FAR的权重很可能比FRR更大。
amin = min(cat(1, scorefr {:},scoreFAR{:}));amax = max(cat(1, scorefr {:},scoreFAR{:}));thresholdsToTest = linspace(amin,amax,1000);%计算每个阈值的FRR和FAR。如果strcmpi (scoringMethod“CSS”)%在CSS中,较大的分数表示注册向量和测试向量%相似。FRR = mean(cat(1, scorefr {:})thresholdsToTest);其他的%在G-PLDA中,较小的分数表示入组和测试载体%相似。FRR = mean(cat(1, scorefr {:})>thresholdsToTest);FAR = mean(cat(1,scoreFAR{:})结束[~,EERThresholdIdx] = min(abs(FAR - FRR));EERThreshold = thresholdsToTest(EERThresholdIdx);EER = mean([FAR(EERThresholdIdx),FRR(EERThresholdIdx)]);图绘制(thresholdsToTest,,“k”,…thresholdsToTest FRR,“b”,…EERThreshold,无论何时,“罗”MarkerFaceColor =“r”)标题("相等错误率= "+(无论何时,4),"Threshold = "+ round(EERThreshold,4)]) xlabel(“阈值”) ylabel (“出错率”)传说(“误取取率(FAR)”,误拒率(FRR),“相等错误率(EER)”位置=“最佳”网格)在轴紧

金宝app支持功能
特征提取与归一化
函数[features,numFrames] = helperFeatureExtraction(audioData,afe,normFactors)%的输入:% audioData -音频数据的列向量% afe - audioFeatureExtractor对象% normFactors -用于归一化的特征的平均值和标准差。%如果normFactors为空,表示不应用规范化。%%输出% features -提取的特征矩阵% numFrames -返回的帧数(特征向量)%正常化audioData = audioData/max(abs(audioData(:)));%防止nanaudioData(isnan(audioData)) = 0;%隔离语音段idx = detectSpeech(audioData,afe.SampleRate);特征= [];为f = extract(afe,audioData(idx(ii,1):idx(ii,2)));Features = [Features;f];% #好< AGROW >结束%特征归一化如果~isempty(normFactors) features = (features-normFactors. mean ')./normFactors. std ';结束Features = Features ';%倒谱平均减法(用于信道噪声)如果~isempty(normFactors) features = features - mean(features,“所有”);结束numFrames = size(features,2);结束
高斯多组分混合对数似然
函数L = helperGMMLogLikelihood(x,gmm) xMinusMu = repmat(x,1,1, nummel (gmm. componentproportion)) - permute(gmm.mu,[1,3,2]);permuteSigma = permute(gmm.sigma,[1,3,2]);Lunweighted = -0.5*(sum(log(permuteSigma),1) + sum(xMinusMu.*(xMinusMu./permuteSigma),1) + size(gmm.mu,1)*log(2*pi));temp = squeeze(permute(Lunweighted,[1,3,2]));如果尺寸(temp, 1) = = 1如果只有一帧,则尾随的单元素维度为%在排列中被删除。这解释了那个边缘情况。Temp = Temp ';结束L = temp + log(gmm.ComponentProportion)';结束
G-PLDA得分
函数score = gpldaScore(gpldammodel,w1,wt)%将数据居中w1 = w1 - gpldammodel .mu;wt = wt - gpldammodel .mu;%漂白数据w1 = gpldammodel . whiteningmatrix *w1;wt = gpldammodel . whiteningmatrix *wt;% length -规范化数据W1 = W1 /vecnorm(W1);Wt = Wt ./vecnorm(Wt);基于对数似然对i向量的相似性进行评分。VVt = gpldammodel。EigenVoices * gpldammodel .EigenVoices';SVVt = gpldammodel。σ + VVt;term1 = pinv([SVVt;VVt SVVt]);term2 = pinv(SVVt);W1wt = [w1;wt];得分= w1wt'*term1*w1wt - w1'*term2*w1 - wt'*term2*wt;结束
参考文献
道格拉斯·A·雷诺兹,等。使用自适应高斯混合模型的说话人验证。数字信号处理,第10卷,第1期。2000年1月,第19-41页。DOI.org (Crossref), doi: 10.1006 / dspr.1999.0361。
[2]肯尼,帕特里克,等。联合因子分析与特征信道在说话人识别中的应用IEEE音频、语音和语言处理汇刊,第15卷,第5期。4, 2007年5月,第1435-47页。DOI.org (Crossref), doi: 10.1109 / TASL.2006.881693。
b[3]肯尼,P.等。“说话人验证中的语际变异研究”。IEEE音频、语音和语言处理汇刊,第16卷,第2期。5, 2008年7月,第980-88页。DOI.org (Crossref), doi: 10.1109 / TASL.2008.925147。
bbb10 Dehak, Najim,等。“说话人验证的前端因素分析”。IEEE音频、语音和语言处理汇刊,第19卷,no。4, 2011年5月,第788-98页。DOI.org (Crossref), doi: 10.1109 / TASL.2010.2064307。
[5] Matejka, Pavel, Ondrej Glembek, Fabio Castaldo, m.j. Alam, Oldrich Plchot, Patrick Kenny, Lukas Burget和Jan cernoky。i-Vector Speaker验证中的全协方差UBM和重尾PLDA2011 IEEE声学、语音与信号处理国际会议(ICASSP), 2011年。https://doi.org/10.1109/icassp.2011.5947436。
David Snyder,等。x向量:用于说话人识别的稳健DNN嵌入。2018 IEEE声学、语音和信号处理国际会议(ICASSP), IEEE, 2018, pp. 5329-33。DOI.org (Crossref), doi: 10.1109 / ICASSP.2018.8461375。
[7]信号处理与语音通信实验室。2019年12月12日发布。https://www.spsc.tugraz.at/databases-and-tools/ptdb-tug-pitch-tracking-database-from-graz-university-of-technology.html。
[10] varani, Ehsan,等。“小尺寸文本依赖说话人验证的深度神经网络”。2014 IEEE声学、语音与信号处理国际会议(ICASSP), IEEE, 2014, pp. 4052-56。DOI.org (Crossref), doi: 10.1109 / ICASSP.2014.6854363。
[9] Dehak, Najim, racimda Dehak, James R. Glass, Douglas A. Reynolds和Patrick Kenny。“没有评分归一化技术的余弦相似度评分。”奥德赛(2010)。
[10] Verma, Pulkit和Pradip K. Das。i -向量在语音处理中的应用综述国际语音技术杂志,第18卷,no。4, 2015年12月,第529-46页。DOI.org (Crossref), doi: 10.1007 / s10772 - 015 - 9295 - 3。
[10]张建军,“基于语音识别的语音识别系统”。Interspeech, 2011, pp. 249-252。
[12]肯尼,帕特里克。“具有重尾先验的贝叶斯说话人验证”。奥德赛2010 -说话者和语言识别研讨会,布尔诺,捷克共和国,2010。
[13] Sizov, Aleksandr, Kong Aik Lee和Tomi Kinnunen。统一生物识别认证中的概率线性判别分析变体。计算机科学:结构、句法和统计模式识别课堂讲稿, 2014, 464-75。https://doi.org/10.1007/978 - 3 - 662 - 44415 - 3 - _47。
[14] Rajan, Padmanabhan, Anton Afanasyev, Ville Hautamäki和Tomi Kinnunen, 2014。从单一到多个注册i -向量:演讲者验证的实用PLDA评分变体。数字信号处理31(八月):93-101。https://doi.org/10.1016/j.dsp.2014.05.001。