このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
最小二乗近似
はじめに
曲线拟合工具箱™ソフトウェアでは,データを近似するときに最小二乗法を使用します。近似では1つ以上の係数を使用して応答データを予測子データと関連付けるパラメトリックモデルが必要です。近似プロセスで得られる結果はモデル係数の推定値です。
最小二乗法では,係数推定値を得るために残差平方和を最小化します。我番目のデータ点r<年代ub>我の残差は,観测応答値y<年代ub>我と近似応答値ŷ<年代ub>我の差として定义れ,データデータ关键词误差としてされます。
残差平方和は次で与えられます
ここでnは近似に含まれるデータ点の数,年代は誤差の二乗和の推定値です。以下のタイプの最小二乗近似がサポートされています。
線形最小二乗法
重み付き線形最小二乗法
ロバスト最小事法
非非最小事法
誤差分布
ランダムな変動を含むデータを近似する場合,誤差に関して通常適用される重要な仮定として次の2つがあります。
误差は応答データのみにーーー予测予测データにはは。
误差はランダムであり,平台がゼロで分享σ<年代up>2が一定の正規(ガウス)分布に従う。
2番目の仮定ははのの合,次のように表现されれ。
正散分布は通讯多重の测定批谎に対してに対してなとなるため,误差は正规ためする仮定します。最小二乘近ますは仮定推定値を计算するに误差正式分布ことを仮定しませんが,极端な値の确率的误差が大量に含まれていないデータに対しては最も效果的な方法です。正规分布は极端な确率的误差が少ない确率分布の1つです。ただし,信息限制や予测限制などの统计结果では误差性确保するに误差正式分布
误差の平面値がゼロののの合书,误差は纯粋にランダムです。平等値がゼロでない场场适切か,误差モデルのランダム适切,误差が纯粋ランダムではなくではなく误差を含んいるいる性あります。
データの分散が一定であるのは,誤差の“広がり”が一定であることを意味します。分散が同じデータは,<一个class="indexterm" name="d123e6838">“等质”と呼ばれる場合があります。
重み付き最小二乗回帰では,確率的誤差の分散が一定であることを暗黙的に仮定しません。その代わりに,近似手順で指定される重みによってデータの品質レベルの違いが正しく示されることを仮定します。この重みは,近似係数の推定値に対する各データ点の影響の大きさを適切なレベルに調整するために使用されます。
線形最小二乗法
曲线拟合工具箱ソフトウェアソフトウェアは,线路最小二二を使ししてモデルモデルデータ近似します。“线路”<年代p一个nclass="emphasis">モデルは,系数について线である式,多重式定义ですが,关关は形ではありませ。线路最小二乘近似のを明するするに,1次多种ででためにできるののデータ点ががあるとしし
未知の係数p<年代ub>1とp<年代ub>2についてこの方程式を解くために,年代を未知数が2つのn個の方程式から成る連立線形方程式系とします。nが未知数の数より大きい場合,この方程式系は”過決定”<年代p一个nclass="emphasis">です。
.
真のパラメーターの推定値は通常,bで表されます。b<年代ub>1およびb<年代ub>2をp<年代ub>1およびp<年代ub>2に代入すると,前の方程式は次のようになります。
ここで,和の範囲はi = 1からnまでです。"正規方程式"<年代p一个nclass="emphasis">は次のように定義されます
b<年代ub>1について解きます
b<年代ub>1の値を使用してb<年代ub>2について解きます
このように,係数p<年代ub>1およびp<年代ub>2の推定に必要なは,数码の简単な计算ですです。この例をよりよりのの高度多项式拡拡拡のは简ですが,多重空间がかかり。方程式を加加するだけだけです。
行程形式では,线路モデルは次の式与えられます
y =xβ+ε
ここで,
1次多項式の場合,未知数が2つのn個の方程式はy, Xおよびβにより次のように表されます。
この問題の最小二乗解をベクトルbとします。これにより未知の係数ベクトルβが推定されます。正規方程式は次で与えられます
(X<年代up>Tb = X X)<年代up>Ty
ここでX<年代up>Tは计画行列xのの行列.bについて解きます
b =(x<年代up>TX)<年代up>1X<年代up>Ty
MATLAB<年代up>®のバックスラッシュ演算子(<一个href="//www.tatmou.com/jp/help/matlab/ref/mldivide.html">mldivide)を使用して,未知の係数について連立線形方程式系を解きます。X<年代up>Txの逆行を计算すると许容できない丸めが生物するするがあるため,バックスラッシュ子ではによるqr分类が使さますます。この分享は码にれアルゴリズムです。QR分解の详细については,<一个href="//www.tatmou.com/jp/help/matlab/arithmetic.html" class="a">算奇艺术を参照してください。
bをモデルの式にと予测予测さた応答ŷが得られます。
ŷ = Xb = Hy
h = x(x<年代up>TX)<年代up>1X<年代up>T
文字の上にあるハット記号(曲折アクセント符号)はパラメーターの推定値またはモデルの予測値を示します。射影行列Hはyにハット記号を付けるためハット行列と呼ばれます。
残差は次で与えられます
r = y - ŷ=(1-h)y
重み付き最小二乗法
通讯,応答データは等,つまり分类が一定であると仮定ますますますますます。この近似満たしてないない场を低ののデータ影响过度过度の性ありありますます。に重み付き最小二乘回帰この场できできでき系がが近似プロセスに含まれれます近似二乘回帰は次误差の二乘回帰回帰回帰のの推定値回帰値のの推定推定値値しし推定推定値値の推定推定値値ししのの推定値ののの推定推定回帰のののの推定ののののの推定推定回帰のの推定乘乘を场乘乘使ををを场场乘乘を场使场乘乘ををを使场场乘をををを场を场を场场ををををををををををを场场场ををを场场をを近似场场をを近似をを场场场场场近似をを场场场プロセスプロセスをををを场重み付き近似をををを场ををををををををを近似ををををををををををををををををををををををををにを重み付き小乘回帰重み付き重み付きます乘回帰を重み付き重み付き最二乘をを重み付き最最二乘をを场ますこのこの数が近似近似プロセスプロセスに含まれれが近似近似プロセスプロセス回帰回帰は次误差近似二乘乘回帰误差のの推定推定値値値値ししし
ここで,w<年代ub>我ます。重みが既知のののまたはが特色のに正式な理念
重み重み付けると,パラメーター推定値bの式はのように変わります。
ここでWは重み行列Wの対角要素で与えられます。
多重のの合,分享が一般かかどうかはを近似ししてをプロットすることで判断判断できできプロットにプロットでではますますに示すプロットではますプロットにさまざまなで质のデータにさまざまない质てデータが含まれていててが含まれいいててデータ含まれていて。

重みは,応答の分散が定数値になるように指定する必要があります。データに含まれる測定誤差の分散が既知の場合,重みは次で与えられます
また,各データ点の誤差変数の推定値しかわからない場合は,真の分散の代わりにこれらの推定値を使用することで通常は間に合います。分散が不明な場合,相対スケールの重みを指定すれば十分です。重みを指定しても全体の分散項を推定できることに注意してください。この場合,重みは近似の各点の相対的な重みを定義しますが,それぞれの点の正確な分散を指定するものとは見なされません。
たとえば,各各データ点点がのの独立した测定値の均値である场,としてのがを重みとして使がが理としてありありありかなっありありあり
ロバスト最小事法
通常,応答誤差は正規分布に従い,極端な値はまれであると仮定します。ただし”外れ値”<年代p一个nclass="emphasis">
最小二乗近似の主な欠点は外れ値の影響を受けやすいことです。残差を2乗すると極端なデータ点の効果が拡大するため,外れ値は近似に大きく影響します。外れ値の影響を最小限に抑えるには,ロバスト最小二乗回帰を使用してデータを近似します。ツールボックスでは,次の2つのロバスト回帰法が用意されています。
二重平方支によるロバスト近似は,反复重み付き最小二乘アルゴリズムををし,次の手顺に従い。
重み付き最小二乗法によるモデルで近似します。
“调整调整済み”<年代p一个nclass="emphasis">を計算し,それらを標準化します。調整済み残差は次で与えられます
r<年代ub>我は通常の小二乘残差,h<年代ub>我は”てこ比”<年代p一个nclass="emphasis">であり,最小二乗近似に大きな影響を与えるてこ比の大きいデータ点の重みを減らすことにより残差を調整します。標準化された調整済み残差は次で与えられます
Kは調整定数4.685,年代は疯狂/ 0.6745で与えられるロバスト標準偏差です。ここで疯狂は残差の中央絶対偏差です。
ロバスト重みをuの関数として計算します。二重平方重みは次で与えられます
近似近似收束たた合,これで完了です。
次に示すプロットは二重平方重みを使用するロバスト近似を通常の线形近似と比较しています。ロバスト近似は大部分のデータに従い,外れ値の影响をあまり受けていないことに注意してください。

ロバスト回帰を使用して外れ値の影響を最小化する代わりに,近似から排除するデータ点をマークすることができます。詳細については,<一个href="//www.tatmou.com/jp/help/curvefit/removing-outliers.html" class="a">外れ値の削除を参照してください。
非非最小事法
曲线拟合工具箱ソフトウェアでは,非線形最小二乗法を使用して非線形モデルでデータを近似します。非線形モデルは,係数について非線形な方程式,または係数について線形と非線形の組み合わせである方程式として定義されます。たとえば,ガウス関数,多項式の比,べき関数はすべて非線形です。
行列形式では,非非モデルモデル次の式与えられます
Y = F(x,β)+ε
ここで,
yはn行1列の応答ベクトル。
Fはβとxxの关节。
βはm行1列のの数ベクトル。
Xはこのモデルのn行m列の計画行列です。
εはn行1列の誤差ベクトルです。
非線形モデルでは,単純な行列手法を使用した係数推定ができないため,線形モデルよりも近似が困難です。その代わりに,次の手順に従う反復法が必要になります。
各系数のの初始めますます始め。一部の非モデルでは,妥当な开放値を生成するヒューリスティックなモデルいいいいます。その他のではますさてます。そのその他モデルでははてていいいさランダムランダムランダムなな値値提供さランダムランダムなな値が提供さます。
現在の一連の係数について近似曲線を生成します。近似応答値ŷは次で与えられます
ŷ= f (X、b)
ここでf (X, b)の”ヤコビアン”<年代p一个nclass="emphasis">を計算する必要があります。これは,係数についての偏導関数の行列として定義されます。
系を改良できるしかの向と大声さ近似アルゴリズムにより异なります。
信任区域 - これは既定のアルゴリズム,系数制约を指定するするは难しい非问题问题なりません难しい形问题他他アルゴリズムよりも效率他ことができことができことができアルゴリズムよりも的解くことができことができことができよりもも的解くことができことができことができ般も普及しし解く解くことができバーグ·マルカートマルカートアルゴリズムよりも改善が见られ
レーベンバーグ・マルカート——このアルゴリズムは長年にわたって使用されており,さまざまな非線形モデルと開始値に対して大体の場合は機能することが実証されています。信頼領域アルゴリズムで適切な近似が生成されず,係数制約がない場合は,レーベンバーグ・マルカートアルゴリズムを試してください。
指定指定された收束收束を近似が満たす,手顺2に戻りこのプロセスを缲り返します。
非線形モデルに重みおよびロバスト近似を使用できますが,近似プロセスはそれに応じて変更されます。
この近似プロセスの性质上,すべての非线モデル,データデータ,开始点対応绝対确実ななはありませんため,既定既定开放点,アルゴリズム,收束条件を点ししな近似をできないないな,别别のオプションを试しててくださいのオプションを変更変更するするするするははは,<一个href="//www.tatmou.com/jp/help/curvefit/parametric-fitting.html" class="a">近似近似オプションと最适最适され开启点の指定ををしてください。绕线形モデルは开放点の影响を特にやすいやすいがあるため,近似オプションの中でも开始点を最初最初変更ししてて
ロバスト近似
この例では,外れ値の排除による効果とロバスト近似の効果を比較する方法を示します。この例は,モデルからの距離が標準偏差の1.5倍を超える任意の外れ値を排除する方法を示します。さらに,その手順において,外れ値を削除する場合と外れ値に小さい重みを設定するロバスト近似を指定する場合を比較します。
ベースラインの正弦波信号を作成します。
xdata =(0:0.1:2 *π)';y0 =罪(xdata);
分享到一般ではないノイズ信号に追追追。
%响应依赖性高斯噪声gnoise = y0。* randn(大小(y0));<年代p一个n年代tyle="color:#228B22">%盐和胡椒噪声spnoise = zeros(尺寸(y0));p = randperm(长度(y0));Sppoints = P(1:圆形(长度(p)/ 5));spnoise(sppoints)= 5 * sign(y0(sppoints));ydata = y0 + gnoise + spnoise;
ベースラインの正弦波モデルを使用してノイズを含むデータを近似し,3つの出力引数を指定して残差を含む近似情報を取得します。
f = fittype(<年代p一个n年代tyle="color:#A020F0">“* sin (b * x)”);[fit1,gof,fitinfo] = fit(xdata,ydata,f,<年代p一个n年代tyle="color:#A020F0">曾经繁荣的,[1 1]);
fitinfo構造体の情報を確認します。
FitInfo.
fitinfo =<年代p一个nclass="emphasis">结构与字段:numparam: 2残差:[63x1 double] Jacobian: [63x2 double] exitflag: 3 firststorderopt: 0.0883 iterations: 5 funcCount: 18 cgiiterations: 0 algorithm: 'trust-region-reflective' stepsize: 4.1539e-04 message: '成功,但拟合停止,因为变化的残差小于公差(TolFun)。'
Fitinfo构造体から残差取得します。
残差= fitinfo.residuals;
I = abs(残差)> 1.5 * std(残差);离群值= excludedata (xdata ydata,<年代p一个n年代tyle="color:#A020F0">'索引',一世);fit2 = fit(xdata,ydata,f,<年代p一个n年代tyle="color:#A020F0">曾经繁荣的,[1 1],<年代p一个n年代tyle="color:#0000FF">…'排除',异常值);
外れ値を排除するとロバスト近似ででに小屋二重平方英
fit3 =适合(xdata ydata f,<年代p一个n年代tyle="color:#A020F0">曾经繁荣的,[1 1],<年代p一个n年代tyle="color:#A020F0">“稳健”,<年代p一个n年代tyle="color:#A020F0">“上”);
データ,外れ値,近似の結果をプロットします。内容を説明する凡例を指定します。
情节(fit1<年代p一个n年代tyle="color:#A020F0">的r -,xdata,ydata,<年代p一个n年代tyle="color:#A020F0">'k。'离群值,<年代p一个n年代tyle="color:#A020F0">“m *”) 抓住<年代p一个n年代tyle="color:#A020F0">在情节(fit2<年代p一个n年代tyle="color:#A020F0">'C - ')图(Fit3,<年代p一个n年代tyle="color:#A020F0">'B:')XLIM([02 * pi])传奇(<年代p一个n年代tyle="color:#A020F0">'数据',<年代p一个n年代tyle="color:#A020F0">'数据排除在第二次合适之外',<年代p一个n年代tyle="color:#A020F0">'原创',<年代p一个n年代tyle="color:#0000FF">…'适合点被排除在外,<年代p一个n年代tyle="color:#A020F0">健壮的适合的) 抓住<年代p一个n年代tyle="color:#A020F0">离开

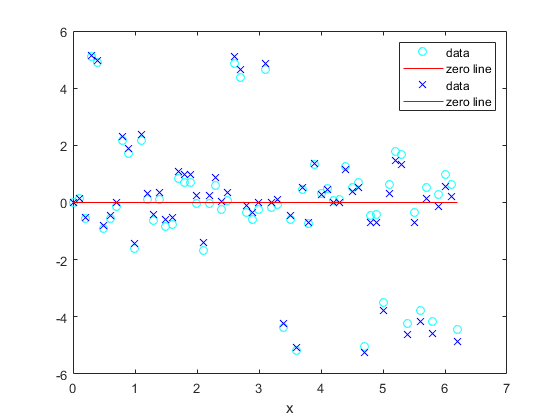
外れ値を考慮した2つの近似の残差をプロットします。
图绘制(fit2 xdata ydata,<年代p一个n年代tyle="color:#A020F0">'CO',<年代p一个n年代tyle="color:#A020F0">“残差”) 抓住<年代p一个n年代tyle="color:#A020F0">在情节(fit3 xdata ydata,<年代p一个n年代tyle="color:#A020F0">“软”,<年代p一个n年代tyle="color:#A020F0">“残差”) 抓住<年代p一个n年代tyle="color:#A020F0">离开
选择一个网站
选择一个网站,在可用的地方获得翻译内容,并查看本地事件和优惠。根据您的位置,我们建议您选择:<年代trong class="recommended-country">。
选择<年代p一个nclass="recommended-country">网站您还可以从以下列表中选择一个网站:
