このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
深層学習を使用したシーケンスの分類
この例では,長短期記憶(LSTM)ネットワークを使用してシーケンスデータを分類する方法を説明します。
シーケンスデータを分類するよう深層ニューラルネットワークに学習させるために,LSTMネットワークを使用できます。LSTMネットワークでは、シーケンス データをネットワークに入力し、シーケンス データの個々のタイム ステップに基づいて予測を行うことができます。
この例では,[1]および[2]に記載のある日本元音データセットを使用します。この例では,続けて発音された2つの日本語の母音を表す時系列データにおいて,その話者を認識するように,LSTMネットワークに学習させます。学習データには9人の話者の時系列データが含まれています。各シーケンスには12個の特徴があり,長さはさまざまです。270年データセットには個の学習観測値と370個のテスト観測値が含まれています。
シーケンスデータの読み込み
日本元音学習データを読み込みます。XTrainは,次元12の可変の270个のシーケンスが含まれる配列配列です。Yは,9人の话者にするラベル“1”,“2”,......,“9”から成る分类ベクトルベクトル。XTrainのエントリは行で,行数が12(特徴に1行)で,列数が可(タイムステップごとに1列)です。
[Xtrain,Ytrain] = JapanesevowelstrainData;XTrain(1:5)
ans =5×1单元阵列{12×20 double} {12×26 double} {12×22 double} {12×20 double} {12×21 double}
最初の時系列をプロットで可視化します。各ラインは特徴に対応しています。
图绘制(XTrain{1}”)包含(“时间步”)标题(“培训观察1”) numFeatures = size(XTrain{1},1);传奇(“特性”+字符串(1:numFeatures),'地点',“northeastoutside”)

パディング用のデータの準備
既定では,学校中に,学校データはミニバッチにされ,パディングによってシーケンス长过度揃えますますますますはます。
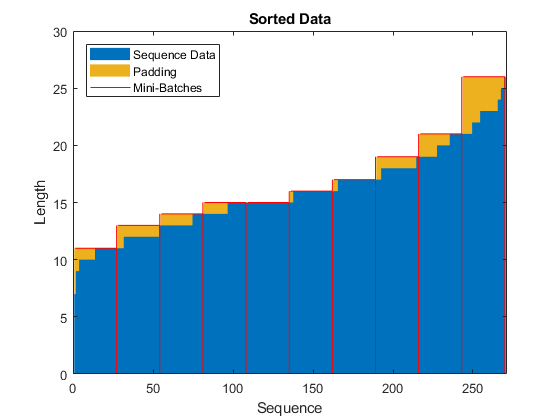
学習プロセスでの過度のパディングを防ぐため,シーケンス長で学習データを並べ替えて,ミニバッチ内のシーケンスが似たような長さになるようにミニバッチのサイズを選択できます。次の図は,データを並べ替える前と後におけるシーケンスのパディングの効果を示しています。

各観測値のシーケンス長を取得します。
numObservations =元素个数(XTrain);为i = 1:numobservations sequence = xtrain {i};Sequencelengths(i)=大小(序列,2);结束
シーケンス長でデータを並べ替えます。
[sequenceLengths, idx] = (sequenceLengths)进行排序;XTrain = XTrain (idx);YTrain = YTrain (idx);
並べ替えられたシーケンス長を棒グラフで表示します。
图栏(Sequencelength)Ylim([030])XLabel(“序列”)ylabel(“长度”)标题(“排序数据”)
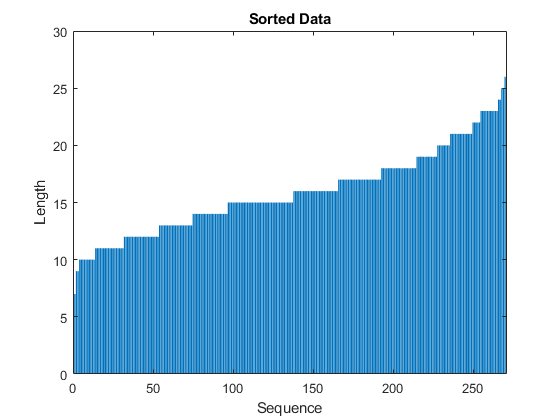
学習データを等分し,ミニバッチ内のパディングの量を減らすため,ミニバッチのサイズに27を選択します。次の図は,シーケンスに追加されたパディングを示しています。
miniBatchSize = 27个;
LSTMネットワークアーキテクチャの定義
LSTMネットワークアーキテクチャを定義します。サイズ12(入力データの次元)のシーケンスになるように入力サイズを指定します。100年隠れユニットが個の双方向LSTM層を指定して,シーケンスの最後の要素を出力します。最後に,サイズが9の全結合層を含めることによって9個のクラスを指定し,その後にソフトマックス層と分類層を配置します。
予測時にシーケンス全体にアクセスする場合は,ネットワークで双方向LSTM層を使用できます。双方向LSTM層は,各タイムステップでシーケンス全体から学習します。予測時にシーケンス全体にアクセスしない場合,たとえば,値を予想していたり一度に1タイムステップを予測していたりする場合は,代わりにLSTM層を使用します。
inputSize = 12;numHiddenUnits = 100;numClasses = 9;层= [...sequenceInputLayer inputSize bilstmLayer (numHiddenUnits,“OutputMode”,“最后一次”)软连接层(numClasses)
图层= 5×1层阵列,图层:1''序列输入序列输入,带12尺寸2''Bilstm Bilstm,具有100个隐藏单元3''完全连接的9完全连接的第4层''softmax Softmax 5''分类输出CrossentRopyex
ここで,学校オプションを指定しますソルバーに“亚当”,勾配のしきい値に1,エポックの最大数に100を指定します。ミニバッチのパディングの量を減らすために,ミニバッチサイズとして27を選択します。データが最長のシーケンスと同じ長さになるようにパディングするために,シーケンスの長さに'最长'を指定します。データをシーケンス長で並べ替えたままにするために,データをシャッフルしないように指定します。
ミニバッチが小さく,シーケンスが短いため,学習にはCPUが適しています。“ExecutionEnvironment”を“cpu”に指定します.GPUが利用できる料,GPUで学习を行う“ExecutionEnvironment”を“汽车”に設定します(これが既定値です)。
maxEpochs = 100;miniBatchSize = 27个;选择= trainingOptions (“亚当”,...“ExecutionEnvironment”,“cpu”,...“GradientThreshold”, 1...“MaxEpochs”maxEpochs,...“MiniBatchSize”miniBatchSize,...“SequenceLength”,'最长',...“洗牌”,“永远”,...“详细”0,...“阴谋”,“训练进步”);
LSTMネットワークの学習
trainNetworkを使用し,指定した学習オプションでLSTMネットワークに学習させます。
net = trainnetwork(xtrain,ytrain,图层,选项);

LSTMネットワークのテスト
テストセットを読み込み,シーケンスを话者别に分享します。
日本元音テストデータを読み込みます。XTest.は,次元12の可変の370个のシーケンスが含まれるれる配列配列。欧美は,9人の话者にするラベル“1”,“2”,......,“9”から成る分类ベクトルベクトル。
[XTest,欧美]= japaneseVowelsTestData;XTest (1:3)
ans =3×1单元阵列{12×19 double} {12×17 double} {12×19 double}
LSTMネットワーク网は,类似类似した长さのののミニバッチを使てて习习しましテストでデータも同じ习ででさささされるようようしししますデータさされるれるようれるれるしししますます习さされるれるれるれるれる并べ替え并べ替えますます
numobservationstest = numel(xtest);为i = 1:numobservationstest序列= xtest {i};SequenceLengdentStest(i)=大小(序列,2);结束[sequenceLengthsTest, idx] = (sequenceLengthsTest)进行排序;XTest = XTest (idx);欧美=欧美(idx);
テストデータを分類します。分類処理で導入されたパディングの量を減らすために,ミニバッチサイズを27に設定します。学習データと同じパディングを適用するために,シーケンスの長さに'最长'を指定します。
miniBatchSize = 27个;XTest YPred =分类(净,...“MiniBatchSize”miniBatchSize,...“SequenceLength”,'最长');
予測の分類精度を計算します。
acc = sum(YPred == YTest)./numel(YTest)
acc = 0.9730
参照
[1] M. Kudo,J. Toyama和M. Shimbo。“使用过度区域的多维曲线分类。”模式识别字母。卷。20,第11-13页,第1103-1111页。
[2] UCI机器学习知识库:日语元音数据集。https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
参考
Bilstmlayer.|lstmLayer|sequenceInputLayer|培训选项|trainNetwork
関連するトピック
你也可以从以下列表中选择一个网站:
