调整FIS树的汽油里程预测
这个例子展示了如何调整FIS树的参数,这是一个连接模糊推理系统的集合。这个例子使用粒子群和模式搜索优化,这需要全局优化工具箱™软件。
每加仑数英里(MPG)的汽车燃料消耗预测是典型的非线性回归问题。它使用了多种汽车配置文件属性来预测燃料消耗。培训数据在加州大学欧文提供机器学习库并包含了从不同品牌和型号的汽车中收集的数据。
此示例使用以下六个输入数据属性来预测与FIS树的输出数据属性MPG:
气缸数
位移
马力
重量
加速
模型一年
准备数据
加载数据。从存储库中获得的数据集的每一行表示一个不同的汽车配置文件。
数据= loadGasData;
数据包含7列,其中前6列包含以下输入属性。
气缸数
位移
马力
重量
加速
模型一年
第七列包含输出属性MPG。
创建单独的输入和输出数据集,X和Y,分别。
x =数据(:,1:6);Y =数据(:,7);
将输入和输出数据集划分为训练数据(奇数索引样本)和验证数据(偶数索引样本)。
trnX = X(1:2:最终,);%培训输入数据集trnY = Y(1:2:最终,);%训练输出数据集vldX = X(2:2:最终,);%验证输入数据集vldY = Y(2:2:最终,);%验证输出数据集
提取每个数据属性的范围,您将在FIS构造期间使用它来定义输入/输出范围。
datarange = [min(data)'max(data)'];
构建FIS树
对于本例,使用以下步骤构建FIS树:
根据输入属性与输出属性的相关性对输入属性进行排名。
使用排名输入属性创建多个FIS对象。
从FIS对象构建一个FIS树。
根据相关系数等级输入
计算培训数据的相关系数。在相关矩阵的最终行中,前六个元素显示了六个存储数据属性和输出属性之间的相关系数。
c1 = corrcoef(数据);c1(最终,:)
ans =.1×7-0.7776 -0.8051 -0.7784 -0.8322 0.4233 0.5805 1.0000
前四个输入属性有负值,最后两个输入属性有正值。
通过相关系数的绝对值排列在降序下具有否定相关性的输入属性。
重量
位移
马力
气缸数
将具有正相关性的输入属性按相关系数的绝对值降序排列。
模型一年
加速
这些排名表明,权重和模型年份与MPG的负相关系数最高,正相关系数最高。
创建模糊推理系统
对于本例,使用以下结构实现FIS树。
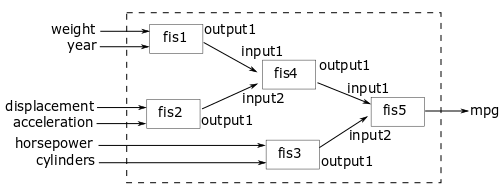
FIS树使用多个双输入一输出的FIS对象来减少推理过程中使用的规则总数。fis1,fis2, 和fis3直接取出输入值并生成中间体英里/加仑值,它们被进一步组合使用fis4和fis5.
具有负相关值和正相关值的输入属性被配对,以结合对输出的积极和消极影响进行预测。输入按其等级分组如下:
重量和型号年
位移和加速度
马力和气缸数量
最后一个组仅包括具有负相关值的输入,因为只有两个具有正相关值的输入。
与Mamdani系统相比,本例使用sugeno类型的FIS对象在调优过程中更快地进行评估。每个FIS包括两个输入和一个输出,其中每个输入包含两个默认的三角隶属函数(MFs),输出包含4个默认常量MFs。使用相应的数据属性范围指定输入和输出范围。
第一个FIS结合了权重和模型年属性。
fis1 = sugfis (“名字”,“fis1”);fis1 = addInput (fis1 dataRange (4:)“NumMFs”2,“名字”,“重量”);fis1 = addInput (fis1 dataRange (6:)“NumMFs”2,“名字”,“年”);fis1 = addOutput (fis1 dataRange (7:)“NumMFs”4);
第二种FIS结合了位移和加速度属性。
fis2 = sugfis (“名字”,“fis2”);fis2 = addInput (fis2, dataRange (2:)“NumMFs”2,“名字”,“位移”);fis2 = addInput (fis2, dataRange (5:)“NumMFs”2,“名字”,“加速”);fis2 = addOutput (fis2, dataRange (7:)“NumMFs”4);
第三个FIS结合了马力和汽缸数量的属性。
fis3 = sugfis (“名字”,“fis3”);fis3 = addinput(fis3,datarange(3,:),“NumMFs”2,“名字”,“马力”);fis3 = addinput(fis3,datarange(1,:),“NumMFs”2,“名字”,“气缸”);fis3 = addOutput (fis3 dataRange (7:)“NumMFs”4);
第四个FIS结合了第一个和第二个FIS的输出。
fis4 = sugfis (“名字”,“fis4”);fis4 = addInput (fis4 dataRange (7:)“NumMFs”2);fis4 = addInput (fis4 dataRange (7:)“NumMFs”2);fis4 = addOutput (fis4 dataRange (7:)“NumMFs”4);
最后的FIS结合第三和第四个FIS的输出,生成估计的MPG。该FIS具有与第四个FIS相同的输入和输出范围。
fis5 = fis4;fis5。Name =“fis5”;fis5.Outputs(1)。Name =“英里”;
构建FIS树
连接模糊系统(fis1,fis2,fis3,fis4, 和fis5),根据FIS树形图。
Fistin = Fistree([FIS1 FIS2 FIS3 FIS4 FIS5],[...“fis1 / output1”“fis4 / input1”;...“fis2 / output1”“fis4 / input2”;...“fis3 / output1”“fis5 / input2”;...“fis4 / output1”“fis5 / input1”])
Fistin = Fistree具有属性:名称:“FistreeModel”FIS:[1x5 Sugfis]连接:[4x2字符串]输入:[6x1字符串]输出:“FIS5 / MPG”DisableStructuralChecks:0请参阅“GetTunablyEts”参数优化方法。
调整与培训数据的FIS树
调优分两个步骤执行。
学习规则库,同时保持输入和输出MF参数不变。
调整输入/输出MFs和规则的参数。
由于规则参数的数量少,第一步是较小的计算昂贵,并且它在训练期间快速收敛到模糊规则库。在第二步中,从第一步中使用规则库作为初始条件提供参数调谐过程的快速收敛。
学习规则
要学习规则库,首先使用TunefisOptions.对象。全局优化方法(遗传算法或粒子群算法)适用于模糊系统所有参数未整定时的初始训练。对于本例,使用粒子群优化方法(“particleswarm”)。
要学习新规则,先设定规则OptimizationType来“学习”.限制规则的最大数量为4个。每个FIS的调优规则数量可以小于这个限制,因为调优过程删除了重复的规则。
选择= tunefisOptions (“方法”,“particleswarm”,...“OptimizationType”,“学习”,...“NumMaxRules”4);
如果您有Parallel Computing Toolbox™软件,您可以通过设置来提高调优过程的速度选项。UseParallel来真的.如果您没有“并行计算工具箱”软件,请设置选项。UseParallel来假.
将最大迭代次数设置为50.为减少规则学习过程中的培训错误,可以增加迭代的数量。但是,使用太多的迭代可以将FIS树过多到培训数据,增加验证错误。
options.MethodOptions.MaxIterations = 50;
由于粒子群优化使用随机搜索,为了获得可重复的结果,将随机数生成器初始化为其默认配置。
rng (“默认”)
使用指定的调优数据和选项调优FIS树。根据FIS树连接设置训练数据的输入顺序,如下所示:重量,一年,移位,加速度,马力, 和气瓶.
inputOrders1 = [4 6 2 5 3 1];orderedTrnX1 = trnX (:, inputOrders1);
学习规则tunefis功能大约需要4分钟。对于本例,通过设置启用调优runtunefis来真的.在不运行的情况下加载佩带的结果tunefis,您可以设置runtunefis来假.
runtunefis = false;
学习新规则时,参数设置可以为空。有关更多信息,请参见tunefis.
如果runtunefis fiout1 = tunefis(fisTin,[],orderedTrnX1,trnY,options);% #好< UNRCH >别的tunedfis =负载(“tunedfistreempgprediction.mat”);fisTout1 = tunedfis.fisTout1;rmseValue = calculateRMSE (fisTout1 orderedTrnX1 trnY);流(’训练RMSE = %。3 f MPG \ n”, rmseValue);结束
训练RMSE = 3.399 MPG
的最好的f (x)列显示训练根均方误差(RMSE)。
学习过程为FIS树生成一组新规则。
流("规则总数= %d\n",numel([fistout1.fis.rules]));
规则总数= 17条
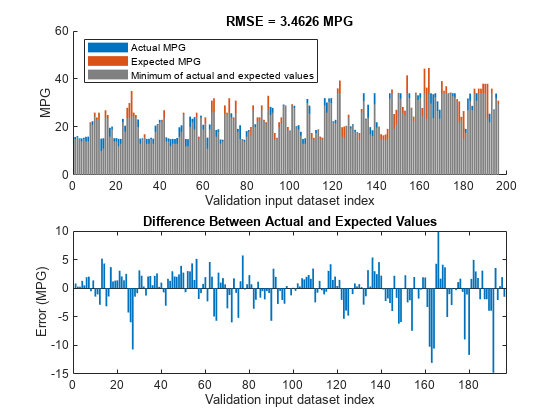
对于训练数据集和验证数据集,学习的系统应该具有相似的RMSE性能。要计算验证数据集的RMSE,请评估fisout1使用验证输入数据集VLDX..若要在计算期间隐藏运行时警告,请将所有警告选项设置为没有一个.
计算生成的输出数据和验证输出数据集之间的RMSEvldy..由于培训和验证错误是相似的,因此学习系统不会过度措施。
orderedVldX1 = vldX (:, inputOrders1);plotActualAndExpectedResultsWithRMSE (fisTout1 orderedVldX1 vldY)
调整所有参数
学习新规则后,根据学习规则的参数调整输入/输出MF参数。如果需要获取FIS树的可调参数,请使用getTunableSettings函数。
[,,规则]= getTunableSettings (fisTout1);
若要在不学习新规则的情况下优化现有FIS树参数设置,请设置OptimizationType来“优化”.
options.optimationtype =.“优化”;
由于FIS树已经使用训练数据学习了规则,使用局部优化方法来快速收敛参数值。对于本示例,使用模式搜索优化方法('patternsearch')。
选项。方法='patternsearch';
与前面的规则学习步骤相比,优化FIS树参数需要更多的迭代。因此,将调优过程的最大迭代次数增加到75次。与第一个调优阶段一样,您可以通过增加迭代次数来减少训练错误。但是,使用过多的迭代可能会对训练数据的参数进行过度调整,从而增加验证错误。
options.MethodOptions.MaxIterations = 75;
为了改善模式搜索结果,设置方法选项UseCompletePoll为真。
options.MethodOptions.UseCompletePoll = true;
使用指定的可调整设置,培训数据和调整选项调整FIS树参数。
用tunefis功能需要几分钟。在不运行的情况下加载佩带的结果tunefis,您可以设置runtunefis来假.
rng (“默认”)如果runtunefis fistrout2 = tunefis(fistrout1,[in;out;rule],orderedTrnX1,trnY,options);% #好< UNRCH >别的fisTout2 = tunedfis.fisTout2;rmseValue = calculateRMSE (fisTout2 orderedTrnX1 trnY);流(’训练RMSE = %。3 f MPG \ n”, rmseValue);结束
训练均方根误差= 3.037 MPG
在调整过程结束时,与上一步相比,训练误差减少。
检查性能
验证优化后的FIS树的性能,fisout2,使用验证输入数据集VLDX..
比较从验证输出数据集获得的预期MPGvldy.和实际的MPG使用fisout2.计算这些结果之间的均方根误差。
plotActualAndExpectedResultsWithRMSE (fisTout2 orderedVldX1 vldY)

与初始学习的规则库的结果相比,调整FIS树参数可以改善RMSE。由于训练和验证错误是相似的,所以参数值不会被调优。
分析中间数据
为了深入了解模糊树的操作,可以将组件模糊系统的输出添加为FIS树的输出。对于本例,要访问中间FIS输出,需要向调优的FIS树添加三个额外的输出。
fistout3 = fistout2;fistout3.outputs(end + 1)=“fis1 / output1”;fistout3.outputs(end + 1)=“fis2 / output1”;fistout3.outputs(end + 1)=“fis3 / output1”;
要生成额外的输出,请评估扩展后的FIS树,fisTout3.
actY = evaluateFIS (fisTout3 orderedVldX1);图(actY(:,[2 3 4 1])) xlabel(“输入数据集指数”)ylabel(“英里”),轴([1 200 0 55])“fis1输出”“fis2输出”“fis3输出”“fis5输出”],...“位置”,“东北”,'numcolumns'2)标题(“中期和最终产出”)
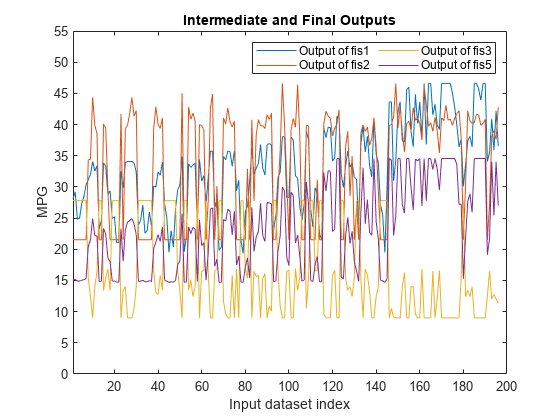
FIS树的最终输出(fis5产出)似乎与产出高度相关fis1和fis3.要验证此评估,请检查FIS输出的相关系数。
C2 = Corrcoef(acty(:,[2 3 4 1]));C2(结束,:)
ans =.1×40.9541 0.8245 -0.8427 1.0000
相关矩阵的最后一行表示fis1和fis3(分别为第一列和第三列)与最终产出的相关性高于fis2(第二列)。这一结果表明,通过删除来简化FIS树fis2和fis4并且可以产生与原始树结构相似的训练结果。
简化和再培训FIS树
消除fis2和fis4从FIS树连接的输出fis1对第一个输入fis5.当您从FIS树中删除一个FIS时,到该FIS的任何现有连接也将被删除。

fisTout3。Fis ([2 4]) = [];fisTout3.Connections (+ 1,:) = (“fis1 / output1”“fis5 / input1”];fis5.Inputs(1)。Name =“fis1out”;
为了使FIS树的输出数量与训练数据中的输出数量相匹配,将FIS树的输出从fis1和fis3.
fisTout3.Outputs(2:结束)= [];
根据新的FIS树输入配置更新输入训练数据顺序。
inputOrders2 = [4 6 3 1];orderedTrnX2 = trnX (:, inputOrders2);
由于FIS树配置已更改,因此必须重新运行学习和调优步骤。在学习阶段,现有的规则参数也被调整以适应FIS树的新配置。
选项。方法=“particleswarm”;options.optimationtype =.“学习”;options.MethodOptions.MaxIterations = 50;[~, ~,规则]= getTunableSettings (fisTout3);rng (“默认”)如果runtunefis fiout4 = tunefis(fiout3,rule,orderedTrnX2,trnY,options);% #好< UNRCH >别的fisTout4 = tunedfis.fisTout4;rmseValue = calculateRMSE (fisTout4 orderedTrnX2 trnY);流(’训练RMSE = %。3 f MPG \ n”, rmseValue);结束
训练RMSE = 3.380 MPG
在训练阶段,对隶属函数和规则的参数进行调整。
选项。方法=“patternsearch”;options.optimationtype =.“优化”;options.MethodOptions.MaxIterations = 75;options.MethodOptions.UseCompletePoll = true;[,,规则]= getTunableSettings (fisTout4);rng (“默认”)如果runtunefis fiout5 = tunefis(fiout4,[in;out;rule],orderedTrnX2,trnY,options);% #好< UNRCH >别的fisTout5 = tunedfis.fisTout5;rmseValue = calculateRMSE (fisTout5 orderedTrnX2 trnY);流(’训练RMSE = %。3 f MPG \ n”, rmseValue);结束
培训RMSE = 3.049 MPG
在调优过程的最后,FIS树包含更新的MF和规则参数值。新FIS树配置的规则库大小小于之前的配置。
流("规则总数= %d\n",numel([fistout5.fis.rules]));
规则总数= 11
检查简化FIS树的性能
使用检查数据集的四个输入属性进行评估更新的FIS树。
orderedVldX2 = vldX (:, inputOrders2);plotActualAndExpectedResultsWithRMSE (fisTout5 orderedVldX2 vldY)
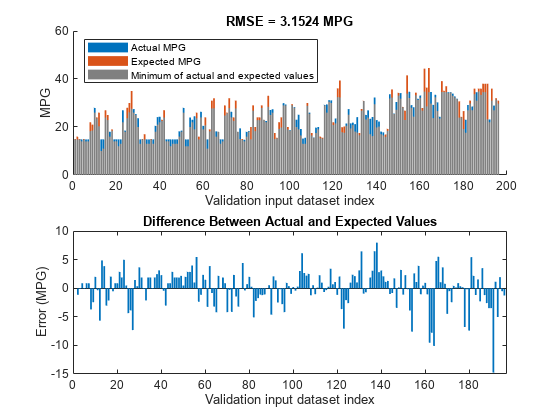
与第一个配置相比,具有四个输入属性的简化FIS树在RMSE方面产生了更好的结果,而第一个配置使用六个输入属性。因此,它表明FIS树可以用较少数量的输入和规则表示,以概括训练数据。
结论
可以通过以下方法进一步改善调整后的FIS树的训练误差:
在规则学习和参数调优阶段不断增加的迭代次数。这样做会增加优化过程的持续时间,还会增加由于训练数据的系统参数过优而导致的验证错误。
使用全局优化方法,例如
遗传算法和particleswarm,在规则学习和参数调优阶段。遗传算法和particleswarm因为它们是全局优化器,所以在较大的参数调优范围内性能更好。另一方面,patternsearch和Simulannealbnd.小参数范围的性能更好,因为它们是局部优化器。如果规则已经使用训练数据添加到FIS树中,则patternsearch和Simulannealbnd.可以产生更快的收敛遗传算法和particleswarm.有关这些优化方法及其选项的更多信息,请参见遗传算法(全局优化工具箱),particleswarm(全局优化工具箱),patternsearch(全局优化工具箱), 和Simulannealbnd.(全局优化工具箱).更改FIS属性,例如FIS类型,输入/输出MFS,MF类型数以及规则数。对于具有大量输入的模糊系统,由于Sugeno系统的输出MF参数较少,Sugeno FIS通常比Mamdani FIS更快地收敛(如果
持续的使用MFS)和更快的Defuzzzine。少量MF和规则减少了调整的参数数量,产生更快的调整过程。此外,大量规则可能会过量训练数据。修改MFs和规则的可调参数设置。例如,您可以在不改变其峰值位置的情况下调优三角形MF的支持。金宝app这样做可以减少可调参数的数量,并为特定的应用程序生成更快的调优过程。对于规则,可以通过设置
AllowEmpty可调设置假,这减少了学习阶段的规则总数。改变FIS树的属性,如模糊系统的数量和模糊系统之间的连接。
使用不同的排名和分组输入到FIS树。
本地函数
功能plotactualandexpectedresultwithrmse(fis,x,y)计算实际结果和预期结果之间的RMSE(rmse actY] = calculateRMSE (fis, x, y);%绘制结果图次要情节(2,1,1)在酒吧(actY)栏(y)栏(min (actY y),'facecholor',[0.5 0.5 0.5])持有离开xlabel([0 200 0 60])“验证输入数据集索引”), ylabel (“英里”)传说([“实际MPG”“预期MPG”“最低实际和预期值”],...“位置”,“西北”)标题(" RMSE = "+ num2str (rmse) +“MPG”) subplot(2,1,2) bar(actY-y) xlabel(“验证输入数据集索引”), ylabel (“错误(MPG)”)标题(“实际值与期望值之差”)结束功能[rmse, actY] = calculateRMSE (fis, x, y)%评估金融中间人actY = evaluateFIS (fis, x);%计算RMSE.del = actY - y;rmse =√意味着(del。^ 2));结束功能x y = evaluateFIS (fis)%指定FIS评估选项持续的evalOptions如果isempty(evalOptions) = evalfisOptions(“EmptyOutputFuzzySetMessage”,“没有任何”,...“NoRuleFiredMessage”,“没有任何”,“OutOfRangeInputValueMessage”,“没有任何”);结束%评估金融中间人x, y = evalfis (fis evalOptions);结束
另请参阅
tunefis|Sugfis.|getTunableSettings|fistree
相关的话题
您还可以从以下列表中选择一个网站:
