用copula建模默认值
本例探讨如何使用多因素copula模型模拟相关交易对手违约。
根据交易对手的违约风险敞口、违约概率和违约信息损失,估计交易对手组合的潜在损失。A.连词对象用于使用潜在变量对每个债务人的信用价值进行建模。潜在变量由一系列加权的基础信用因素以及每个债务人的特殊信用因素组成。潜在变量根据其违约概率映射到每个场景中债务人的违约或非违约状态。投资组合风险度量、交易对手层面的风险贡献以及模拟趋同信息在金宝app连词对象。
这个例子还探讨了风险度量对联系符类型的敏感性(高斯联系符vsTCopula)用于模拟。
加载并检查投资组合数据
该投资组合包含100个交易对手及其相关的违约信用风险敞口(含铅)、违约概率(PD),以及默认损失(LGD).使用一个连词对象时,可以模拟某个固定时间段(例如,一年)的默认值和损失。这个含铅,PD,LGD输入必须针对特定的时间范围。
在本例中,每个交易对手都映射到两个基础信用因素,并具有一组权重。这个Weights2F变量是一个NumCounterparties-by-3矩阵,其中每行包含单个交易对手的权重。前两列是两个信贷因素的权重,最后一列是每个交易对手的特殊权重。本例中还提供了两个基本因素的相关矩阵(FactorCorr2F).
负载CreditPortfolioData.mat谁含铅PDLGDWeights2FFactorCorr2F
名称大小字节类属性EAD 100x1 800双因子CORR2F 2x2 32双LGD 100x1 800双PD 100x1800双权重2F 100x3 2400双
初始化连词对象与投资组合信息和因素相关性。
rng (“默认”);cc = creditDefaultCopula (EAD、PD、乐金显示器,Weights2F,“因素相关性”, FactorCorr2F);%将VaR级别修改为99%。cc.VaRLevel=0.99;显示(cc)
creditDefaultCopula with properties: Portfolio: [100x5 table] FactorCorrelation: [2x2 double] VaRLevel: 0.9900 UseParallel: 0 portfolioloss: []
: cc.Portfolio (1:5)
ans =5×5表中国政府官员称其权重权重为“UUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUU0.65
模拟模型并绘制潜在损失
用。模拟多因素模型模拟函数。默认情况下,使用高斯copula。这个函数在内部将实现的潜在变量映射到默认状态,并计算相应的损失。仿真结束后连词对象填充PortfolioLosses和反对党属性与仿真结果。
cc=模拟(cc,1e5);显示(cc)
creditDefaultCopula with properties: Portfolio: [100x5 table] FactorCorrelation: [2x2 double] VaRLevel: 0.9900 UseParallel: 0 PortfolioLosses:[30.1008 3.6910 3.2895 19.2151 7.5761 44.5088…]
这个portfolioRisk函数返回总投资组合损失分布的风险度量,以及可选的,它们各自的置信区间。中设置的水平报告风险值(VaR)和条件风险值(CVaR)VaRLevel财产连词对象。
[公关,pr_ci] = portfolioRisk (cc);fprintf(“投资组合风险措施:\ n”);
投资组合风险措施:
disp (pr)
EL标准VaR CVaR 24.876 23.778 102.4 121.28
fprintf('\n\n风险度量的置信区间:\n');
风险度量的置信区间:
disp (pr_ci)
EL Std VaR CVaR_uuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu24.729 25.0223.101.885.122.122
看看投资组合损失的分布。预期损失(EL)、VaR和CVaR标记为垂直线。由VaR和EL之间的差异得出的经济资本显示为EL和VaR之间的阴影区域。
直方图(cc.PortfolioLosses)标题(“投资组合损失”);xlabel(的损失(美元)) ylabel (“频率”)举行在%在直方图上覆盖风险度量。xlim([0 1.1*pr.CVaR])绘图线=@(x,颜色)绘图([x x],ylim,“线宽”2,“颜色”、颜色);情节(公关。埃尔,“b”);情节(公关。VaR,“r”);cvarline =情节(公关。CVaR,“米”);%对预期损失和经济资本的区域进行遮蔽。pltband = @(x,color) patch([x fliplr(x)],[0 0 repmat(max(ylim),1,2)],...颜色“FaceAlpha”, 0.15);elband = plotband([0 pr.EL],“蓝”);ulband=plotband([pr.EL pr.VaR],“红色”);图例([elband、ulband、cvarline],...{“预期损失”,“经济资本”,“CVaR(99%)”},...“位置”,“北”);
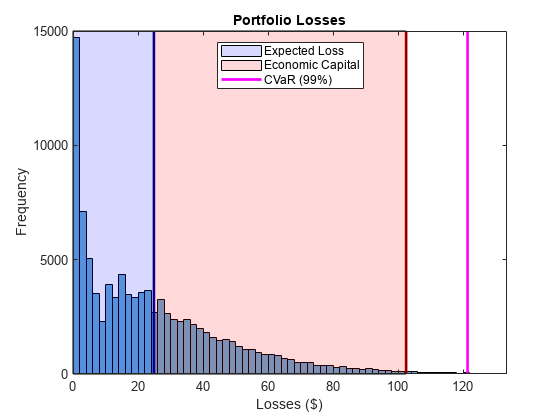
找出交易对手的集中度风险
使用riskContribution函数。riskContribution返回每个交易对手对投资组合EL和CVaR的贡献。这些附加贡献之和对应的总投资组合风险度量。
rc = riskContribution (cc);%报告了EL和CVaR的风险贡献。rc (1:5,:)
ans =5×5表ID EL Std VaR CVaR __________ __________ _________ _________ 1 0.036031 0.022762 0.083828 0.13625 2 0.068357 0.039295 0.23373 0.24984 3 1.2228 0.60699 2.3184 2.3775 4 0.002877 0.00079014 0.0024248 0.0013137 5 0.12127 0.037144 0.18474 0.24622
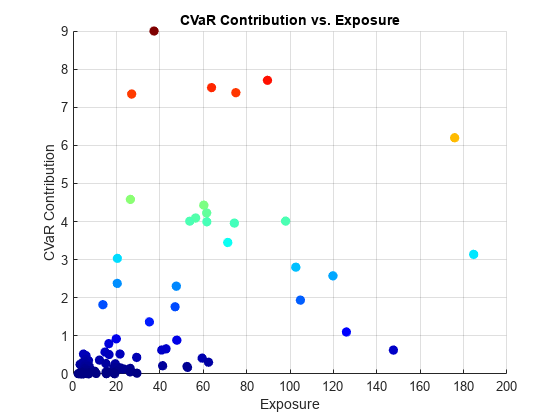
通过CVaR供款找到风险最高的交易对手。
[rc_sorted, idx] = sortrows (rc,“CVaR”,“下”);: rc_sorted (1:5)
ans =5×5表ID EL Std VaR CVaR 2.2647 2.2063 8.2676 8.9997 1.3515 1.6514 6.6157 7.7062 66 0.90459 1.474 6.4168 7.5149 22 1.5745 1.8663 6.0121 7.3814 16 1.6352 1.5288 6.04 347.62
绘制交易对手风险敞口和CVaR贡献。CVaR贡献最高的交易对手用红色和橙色表示。
图;pointSize = 50;colorVector = rc_sorted.CVaR;散射(cc.Portfolio (idx:)。含铅,rc_sorted。CVaR,...点大小,颜色向量,“填充”) colormap (“喷气机”)标题(“CVaR贡献vs.暴露”)包含(“曝光”) ylabel (“CVaR贡献”网格)在
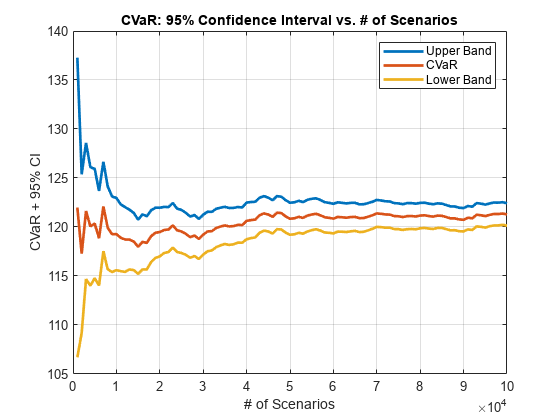
研究具有置信带的仿真收敛
使用confidenceBands函数来研究仿真的收敛性。默认情况下,报告CVaR置信区间,但是使用可选参数支持所有风险度量的置信区间金宝appRiskMeasure论点。
cb=置信区间(cc);%置信带存储在表中。cb (1:5,:)
ans =5×4表numscenario Lower CVaR Upper ____________ ____________ ______ 1000 106.7 121.99 137.28 2000 109.18 117.28 125.38 3000 114.68 121.63 128.58 4000 114.02 120.06 126.11 5000 114.77 120.36 125.94
绘制置信带,看看估计收敛的速度有多快。
图(...cb。NumScenarios,...cb{:{“上”“CVaR”“低”}},...“线宽”,2);头衔(“CVaR:95%置信区间vs.各种情况”);xlabel(#各种情景");伊莱贝尔(“CVaR + 95% CI”)传奇(“上层乐队”,“CVaR”,“低乐队”);网格在
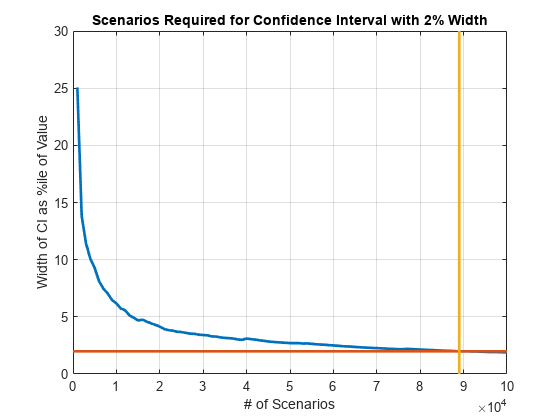
找到必要数量的场景,以达到特定的置信区间宽度。
宽度= (cb。/ cb.CVaR;图(cb。NumScenarios,宽度* 100,“线宽”,2);头衔(“CVaR:95%置信区间宽度vs.情景”);xlabel(#各种情景");伊莱贝尔(' CI宽度为值的%ile '网格)在找到置信区间在该区间的1%(两侧)以内的点%CVaR。打= 0.02;scenIdx = find(width <= thresh,1,)“第一”);scenValue = cb.NumScenarios (scenIdx);widthValue =宽度(scenIdx);持有在plot(xlim,100 * [widthValue widthValue],...[scenValue scenValue], ylim,...“线宽”,2);头衔(“宽度为2%的置信区间所需的场景”);
比较高斯和T连接词
切换到TCopula增加了交易对手之间的违约相关性。这导致了投资组合损失的一个更肥的尾部分布,在压力情景下的潜在损失更高。
使用。重新运行模拟Tcopula并计算新的投资组合风险度量T连系动词是5。
cc_t =模拟(cc, 1 e5,连系动词的,“不”);pr_t = portfolioRisk (cc_t);
查看投资组合风险如何随时间变化T连接词。
fprintf(高斯关联的投资组合风险:\n');
高斯关联组合风险:
disp (pr)
EL标准VaR CVaR 24.876 23.778 102.4 121.28
fprintf(“\n\n带有t连接的投资组合风险(dof=5):\n”);
关联系数为t的投资组合风险(dof = 5):
disp (pr_t)
EL性病VaR CVaR ______ ______ ______ ______ 24.808 38.749 186.08 250.59
比较每个模型的尾部损失。
%绘制高斯copula尾部。图;subplot(2,1,1) p1 = histogram(cc.PortfolioLosses);持有在情节(公关。VaR,[1 0.5 0.5]) plotline(pr.CVaR,[1 0 0]) xlim([0.8 * pr.VaR 1.2 * pr_t.CVaR]); ylim([0 1000]); grid在传奇(损失分布的,“VaR”,“CVaR”)标题(“高斯Copula组合损失”);xlabel(的损失(美元));伊莱贝尔(“频率”);绘制t形连接尾。子批次(2,1,2)p2=直方图(cc_t.Portfolioloss);保持在情节(pr_t。VaR,[1 0.5 0.5]) plotline(pr_t.CVaR,[1 0 0]) xlim([0.8 * pr.VaR 1.2 * pr_t.CVaR]); ylim([0 1000]); grid在传奇(损失分布的,“VaR”,“CVaR”);标题(“t Copula(dof=5)组合损失”);xlabel(的损失(美元));伊莱贝尔(“频率”);
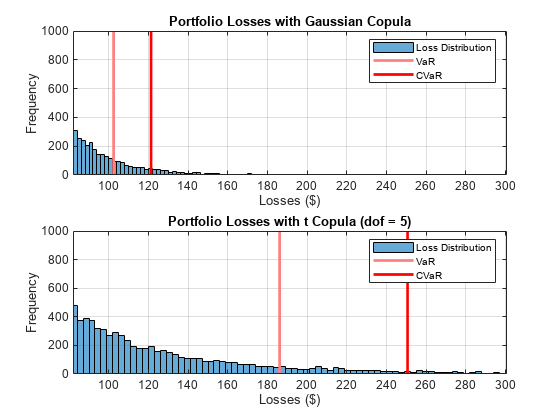
尾部风险度量VaR和CVaR显著高于使用T有五个自由度的Copula。默认的相关性较高Tcopula,因此有更多的情况,多个对手违约。自由度的数目起着重要的作用。对于非常高的自由度,结果是Tcopula与Gaussian copula的结果相似。5是一个非常低的自由度,因此,结果显示出显著的差异。此外,这些结果强调,极端损失的可能性对copula的选择和自由度的数量非常敏感。
另见
连词|模拟|portfolioRisk|riskContribution|confidenceBands|获取场景
相关实例
更多关于
你也可以从以下列表中选择一个网站:
