基于小波时间散射的音乐类型分类
这个例子展示了如何使用小波时间散射和音频数据存储对音乐节录的类型进行分类。在小波散射中,数据通过一系列小波变换、非线性和平均来产生数据的低方差表示。然后将这些低方差表示用作分类器的输入。
GTZAN数据集
本例中使用的数据集是GTZAN Genre Collection[7][8]。数据以压缩后的tar存档文件的形式提供,大约有1.2 GB。未压缩的数据集需要大约3gb的磁盘空间。从参考文献中提供的链接中提取压缩的tar文件将创建一个包含10个子文件夹的文件夹。每个子文件夹都以它所包含的音乐样本类型命名。音乐类型有:蓝调、古典、乡村、迪斯科、嘻哈、爵士、金属、流行、雷鬼和摇滚。每种类型都有100个例子,每个音频文件包含大约30秒的22050赫兹采样数据。在最初的论文中,作者使用了大量的时域和频域特征,包括从每个音乐示例中提取的梅尔-频率倒谱(MFC)系数和高斯混合模型(GMM)分类,达到了61%[7]的准确率。随后,深度学习网络被应用到这些数据中。在大多数情况下,这些深度学习方法是由卷积神经网络(CNN)组成,以MFC系数或谱图作为深度CNN的输入。 These approaches have resulted in performance of around 84% [4]. An LSTM approach with spectrogram time slices resulted in 79% accuracy and time-domain and frequency-domain features coupled with an ensemble learning approach (AdaBoost) resulted in 82% accuracy on a test set [2][3]. Recently, a sparse representation machine learning approach achieved approximately 89% accuracy [6].
下载数据
第一步是下载GTZAN Genre Collection[7][8]。本例中的说明假设您将数据集下载到临时目录,tempdir在MATLAB®。如果您选择在不同的文件夹中下载数据tempdir,请在后续说明中修改目录名称。使用gunzip下载并解压缩数据集。然后使用解压提取tar文件的内容。的文件夹类型中创建tempdir在…内类型有十个子文件夹,每个音乐类型一个。
dataURL =“http://opihi.cs.uvic.ca/sound/genres.tar.gz”;gunzip (dataURL tempdir)在tempdir中创建genre .taruntar(完整文件(临时目录),“genres.tar”), tempdir)%创建流派文件夹
小波散射的框架
在小波时间散射网络中,唯一要指定的参数是时不变的持续时间、小波滤波器组的数目和每倍频程的小波数目。对于大多数应用来说,将数据级联到两个小波滤波器组就足够了。在这个例子中,我们使用默认的散射网络,它使用两个小波滤波器组。第一个滤波器组每八度有8个小波,第二个滤波器组每八度有1个小波。对于本例,将不变比例设置为0.5秒,这对应于给定采样率略多于11000个样本。建立小波时间散射分解网络。
sn = waveletScattering (“SignalLength”,2^19,“SamplingFrequency”, 22050,...“不变性刻度”, 0.5);
为了理解不变性尺度的作用,从第一滤波器组中,取最粗尺度小波的实部和虚部,在时间上绘制尺度滤波器。注意,按设计,缩放滤波器的时间支持基本金宝app上是0.5秒。此外,最粗尺度小波的时间支持不超过小金宝app波散射分解的不变尺度。
[fb,f,filterparams]=filterbank(sn);phi=ifftshift(ifft(fb{1}.phift));psiL1=ifftshift(ifft(fb{2}.psift(:,end));dt=1/22050;time=-2^18*dt:dt:2^18*dt;shopplt=plot(time,phi,“线宽”, 1.5);持有在网格在Ylimits = [-3e-4 3e-4];ylim (ylimits);ylimits情节([-0.25 - -0.25],“k——”);ylimits情节([0.25 - 0.25],“k——”);xlim ([-0.6 - 0.6]);包含(“秒”);伊莱贝尔(“振幅”);wavplt = plot(time,[real(psiL1) imag(psiL1)]);传奇([scalplt wavplt (1) wavplt (2)),...{“扩展功能”,“Wavelet-Real部分”,“Wavelet-Imaginary部分”});标题({“扩展功能”;“最粗尺度小波第一滤波器组”})举行从

音频数据存储
音频数据存储使您能够管理音频数据文件的集合。对于机器或深度学习,音频数据存储不仅管理来自文件和文件夹的音频数据流,音频数据存储还管理标签与数据的关联,并提供将数据随机划分到不同集的能力,以进行训练、验证和测试。在本例中,使用音频数据存储来管理GTZAN音乐类型集合。回忆一下,集合中的每个子文件夹都是以它所代表的类型命名的。设置“IncludeSubFolders”财产真正的来指示音频数据存储使用子文件夹并设置“LabelSource”财产“foldernames”根据子文件夹名称创建数据标签。这个例子假设顶级目录在MATLAB中tempdir目录,称为“流派”。确保位置是计算机上顶级数据文件夹的正确路径。你机器上的顶级数据文件夹应该包含10个子文件夹,每个文件夹都以10种类型命名,并且必须只包含与这些类型相对应的音频文件。
位置=完整文件(tempdir,“流派”);广告= audioDatastore(位置,“IncludeSubFolders”是的,...“LabelSource”,“foldernames”);
运行以下命令获取数据集中音乐类型的计数。
countEachLabel(广告)
ans =10×2表标签数_________ _____蓝调100古典100乡村100迪斯科100嘻哈100爵士100金属100流行乐100雷鬼100摇滚100
如前所述,有10种类型,每个类型有100个文件。
培训和测试集
创建训练和测试集来开发和测试我们的分类器。我们使用80%的数据进行训练,并保留剩下的20%进行测试。的洗牌音频数据存储的函数随机洗牌数据。在按标签分割数据之前执行此操作以随机化数据。在本例中,我们设置随机数生成器种子以实现再现性。使用音频数据存储splitEachLabel函数执行80-20分割。splitEachLabel确保所有类都是平等的。
Rng (100) ads = shuffle(ads);[adsTrain, adsTest] = splitEachLabel(广告,0.8);countEachLabel (adsTrain)
ans =10×2表标签数_________ _____蓝调80古典80乡村80迪斯科80嘻哈80爵士80金属80流行乐80雷鬼80摇滚80
计数标签(adsTest)
ans =10×2表标签数_________ _____蓝调20古典20乡村20迪斯科20嘻哈20爵士20金属20流行20雷鬼20摇滚20
您可以看到训练数据中有800条记录,测试数据中有200条记录。此外,训练集中每种类型有80个例子,测试集中每种类型有20个例子。
要获得散射特性,请使用辅助函数,helperbatchscatfeatures,得到散射特性的自然对数
每个音频文件的样本和子样本的数量散射窗口6。的源代码helperbatchscatfeatures列在附录中。小波散射特征的计算使用批处理大小的64个信号。
如果你有并行计算工具箱™ 和一个受支持的GPU集金宝appuseGPU来真正的在下面的代码和散射变换将使用GPU计算。使用64个批量大小的NVIDIA Titan V GPU,本例中的散射特性的计算速度大约是使用CPU的9倍。
N=2^19;batchsize=64;scTrain=[];useGPU=false;%设置为true,使用图形处理器而hasdata(adsTrain)sc=助手bachscat特征(adsTrain,sn,N,batchsize,useGPU);scTrain=cat(3,scTrain,sc);结束
记录散射变换中用于创建标签的时间窗口的数目。
numTimeWindows=大小(scTrain,2);
在这个例子中,每个散射路径有43个时间窗口或帧。
对测试数据重复相同的特征提取过程。
sct = [];而hasdata(adsTest) sc = helperbatchscatfeatures(adsTest,sn,N,batchsize,useGPU);sct =猫(3 sct sc);结束
确定散射网络中的路径数,将训练和测试特征重塑为二维矩阵。
[~, npaths] = sn.paths ();Npaths =总和(Npaths);TrainFeatures = permute(scTrain,[2 3 1]);[], TrainFeatures =重塑(TrainFeatures Npaths, 1);TestFeatures = permute(scTest,[2 3 1]);[], TestFeatures =重塑(TestFeatures Npaths, 1);
每一行的TrainFeatures和测试特性是每个音频信号散射变换中334条路径上的一个散射时间窗口。对于每个音乐样本,我们有43个这样的时间窗口。相应地,训练数据的特征矩阵为34400×334。行数等于训练示例数(800)乘以每个示例(43)的散射窗口数。同样,测试数据的散射特征矩阵为8600-x-334。每个示例有200个测试示例和43个窗口。为训练数据的小波散射特征矩阵中的43个窗口中的每一个创建类型标签。
列车标签=adsTrain.标签;numTrainSignals=numel(列车标签);trainLabels=repmat(trainLabels,1,numTimeWindows);列车标签=重塑(列车标签’,numTrainSignals*numTimeWindows,1);
对测试数据重复上述过程。
testLabels=adsTest.Labels;numTestSignals=numel(testLabels);testLabels=repmat(testLabels,1,numTimeWindows);testLabels=Reformat(testLabels,1,numTestSignals*numTimeWindows,1);
在本例中,使用具有三次多项式核的多类支持向量机(SVM)分类器。将SV金宝appM与训练数据相匹配。
模板= templateSVM (...“KernelFunction”,多项式的,...“PolynomialOrder”3,...“KernelScale”,“汽车”,...“BoxConstraint”, 1...“标准化”,真正的);类= {“蓝调”,“经典”,“国家”,“迪斯科”,“嘻哈”,“爵士乐”,...“金属”,“流行”,“雷鬼”,“岩石”};classificationSVM = fitcecoc (...TrainFeatures,...trainLabels,...“学习者”模板,...“编码”,“一对一”,“类名”分类(类));
测试集预测
使用SVM模型拟合训练数据的散射变换来预测测试数据的音乐类型。回想一下散射变换中每个信号都有43个时间窗。使用简单多数投票来预测类型。辅助函数helperMajorityVote获得所有43个散射窗口的类型标签模式。如果没有唯一的模式,helperMajorityVote返回由指示的分类错误“NoUniqueMode”.这将导致混淆矩阵中多出一列。的源代码helperMajorityVote列在附录中。
predLabels=预测(classificationSVM、TestFeatures);[TestVotes,TestCounts]=HelperMajorityNote(predLabels,adsTest.Labels,Category(Class));testAccuracy=sum(等式(testvots,adsTest.Labels))/numTestSignals*100
testAccuracy = 87.5000
测试精度,测试准确性大约是88%。这种精度可与GTZAN数据集的最新技术相媲美。
显示混淆矩阵以检查不同类型的准确率。回想一下,每节课有20个例子。
confusionchart(TestVotes、adsTest.Labels)
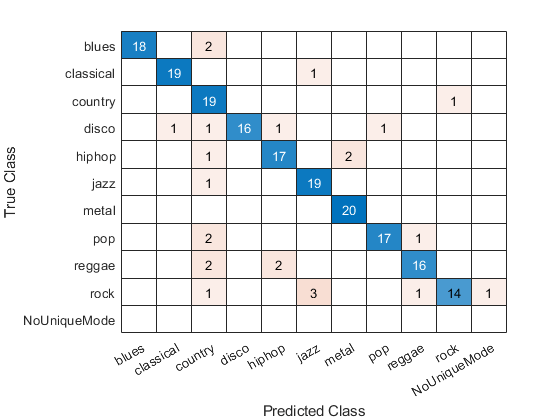
从混淆矩阵图的对角线可以看出,分类准确率总体上很好。分别提取这些体裁的准确性和情节。
厘米= confusionmat (TestVotes adsTest.Labels);厘米(:,结束)= [];genreAccuracy =诊断接头(cm)。/ 20 * 100;图;栏(genreAccuracy)集(gca,“XTickLabels”、类);甘氨胆酸xtickangle (30);标题(“按类型划分的正确率-测试集”);

总结
这个例子演示了小波时间散射和音频数据存储在音乐类型分类中的使用。在这个例子中,小波时间散射达到了与GTZAN数据集的最新性能相当的分类精度。与其他需要提取大量时域和频域特征的方法不同,小波散射只需要指定一个参数,即时不变的尺度。音频数据存储使我们能够有效地管理从磁盘到MATLAB的大数据集的转移,并允许我们随机化数据,并通过分类工作流准确地保留随机数据的类型成员。
参考文献
Anden,J.和Mallat,S.2014.深散射光谱。IEEE信号处理学报,第62卷,第16页,第4114-4128页。
Bergstra,J.,Casagrande,N.,Erhan,D.,Eck,D.,和Kegl,B.《音乐分类的聚合特征和AdaBoost》。机器学习,第65卷,第2-3期,第473-484页。
欧文,J.,查托克,E.和霍兰德,N. 2016。注意类型分类的递归神经网络。https://www.semanticscholar.org/paper/Recurrent-Neural-Networks-with-Attention-for-Genre-Irvin/6da301817851f19107447e4c72e682e3f183ae8a
李涛、陈雅博和陈雅博。2010。基于卷积神经网络的音乐模式特征自动提取。国际会议数据挖掘和应用。
Mallat。美国2012年。集团不变的散射。《纯粹和应用数学通讯》,第65卷,第10页,1331-1398。
Y.Panagakis.,Kotropoulos,C.L.和Arce,G.R.2014.通过音频特征的联合稀疏低阶表示进行音乐类型分类。IEEE音频、语音和语言处理交易,22,12,第1905-1917页。
Tzanetakis, G.和Cook, P. 2002。音频信号的音乐类型分类。《IEEE语音和音频处理汇刊》,第10卷,第5期,293-302页。
GTZAN类型集合.
http://marsyas.info/downloads/datasets.html
附录—支持功能金宝app
helperMajorityVote——这个函数返回在许多特征向量上预测的类标签的模式。在小波时间散射中,我们为每个时间窗口取一个类标签。如果没有找到唯一模式,则为“NoUniqueMode”返回以表示分类错误。
类型helperMajorityVote
函数[ClassVotes,ClassCounts]=HelperMajorityNote(predLabels,origLabels,classes)%此函数仅支持小波散射示例。它可能会%更改或在将来的版本中删除。金宝app%n如果标签尚未分类,则创建分类数组predLabels=Category(predLabels);origLabels=Category(origLabels);%期望predLabels和origLabels都是分类向量Npred=numel(predLabels);Norig=numel(origLabels);Nwin=Npred/Norig;predLabels=Reformate(predLabels,Nwin,Norig);ClassCounts=COUNTCTS(predLabels);[mxcount,idx]=max(ClassCounts);CLASSVOUTS=classes(idx);%检查最大值中的任何关联,如果模式出现多次,则确保它们标记为%error tmpsum=sum(ClassCounts==mxcount);CLASSOVERS(tmpsum>1)=分类({'NONUNIQUEMODE'});CLASSOVERS=CLASSOVERS(:);
helperbatchscatfeatures-该函数返回给定输入信号的小波时间散射特征矩阵。在这种情况下,我们使用小波散射系数的自然对数。计算了散射特征矩阵
信号的样本。散射特征以6的因子进行二次采样。如果useGPU被设置为真正的,在GPU上计算散射变换。
函数sc=HelperBachScatFeatures(ds、sn、N、批次大小、使用GPU)%此函数仅用于支持小波中的示例金宝app%工具箱。它可能会在将来的版本中更改或删除。%从音频数据存储读取批数据批= helperReadBatch (ds, N, batchsize);如果useGPU批次=gpuArray(批次);结束获得散射特征S = sn.featureMatrix(批处理,“转变”,“日志”);聚集(批);S=聚集;%对特征进行子采样1:6 sc = S (::,:);结束
helperReadBatch-该函数从数据存储中读取指定大小的批量数据,并以单精度返回输出。输出的每一列都是来自数据存储的一个单独的信号。如果数据存储没有足够的记录,输出的列可能少于批处理大小。
函数batchout = helperReadBatch (N, ds batchsize)%这个函数只支持小波工具箱的例子。金宝app它可能%更改或在未来的版本中删除。%% batchout = readReadBatch(ds,N,batchsize),其中ds是数据存储% ds是数据存储%batchsize是batchsizekk = 1;而(hasdata(ds)) && kk <= batchsize tmpRead = read(ds);batchout (:, kk) =投(tmpRead (1: N),“单一”);% #好< AGROW >kk = kk + 1;结束结束
另请参阅
相关的话题
你也可以从以下列表中选择一个网站: