このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
GPUパフォーマンスの測定
この例では,GPUの主なパフォーマンス上の特徴をいくつか測定する方法を示します。
GPUは,特定タイプの計算を高速化するために使用できます。しかしGPUのパフォーマンスには,異なるGPUデバイス間で大きな違いがあります。GPUのパフォーマンスを数量化するために,3つのテストが使用されます。
GPUへのデータ送信やそこからの再読み取りを,どの程度速く実行できるか
GPUカーネルがどの程度速くデータの読み取りと書き込みを実行できるか
GPUはどの程度速く計算を実行できるか
これらを測定した後,GPUのパフォーマンスをホストCPUと比較できます。これによってGPUがCPUと比べ有利となるにはどれ程のデータや計算が必要なのかについて,指針が与えられます。
設定
gpu = gpuDevice ();流('使用%s GPU。\n', gpu.Name) sizeOfDouble = 8;%每个双精度数需要8字节的存储空间size = power(2, 14:28);
使用特斯拉K40c GPU。
ホスト/ GPU帯域幅のテスト
最初のテストでは,GPUへのデータ送信とGPUからの読み取りの速さを推定します。GPUはPCIバスに接続されているため,この値は,PCIバスの速さとバスを使用する他の要素の数によって大きく左右されます。しかし,特に関数呼び出しオーバーヘッドと配列割り当て時間など,いくつかのオーバーヘッドも測定には含まれます。こうした値はGPUの”実際の”使用には付き物なので,これを含めるのは理に適っています。
以下のテストでは,関数gpuArrayを使用して,GPUへのメモリ割り当てとデータ送信が行われます。收集を使用して,ホストメモリへのメモリ割り当てとデータ再転送が行われます。
このテストで使用されているPCI Express v3では,帯域幅の理論値がレーンあたり0.99 GB / sです。つまり,NVIDIAの演算カードで使用される16レーンのスロット(PCIe3)の場合,理論値は15.75 GB / sとなります。
sendTimes =正(大小(尺寸));gatherTimes =正(大小(尺寸));为ii=1: nummel (size) numElements = size (ii)/sizeOfDouble;hostData = randi([0 9], numElements, 1);gpuData = randi([0 9], numElements, 1,“gpuArray”);发送到GPU的时间sendFcn = @() gpuArray(hostData);sendTimes (ii) = gputimeit (sendFcn);时间从GPU收集回来gatherFcn = @() gather(gpuData);gatherTimes (ii) = gputimeit (gatherFcn);结束sendBandwidth = (sizes. / sendTimes) / 1 e9;[maxSendBandwidth, maxSendIdx] = max (sendBandwidth);流('达到峰值发送速度%g GB/s\n',maxSendBandwidth) gatherBandwidth = (size ./gatherTimes)/1e9;[maxGatherBandwidth, maxGatherIdx] = max (gatherBandwidth);流(达到峰值采集速度%g GB/s\n马克斯(gatherBandwidth))
达到峰值发送速度6.18519 GB/s达到峰值采集速度3.31891 GB/s
下記のプロットでは,それぞれの場合のピークに丸印が付けられています。データセットのサイズが小さいと,オーバーヘッドの影響が大きく出ます。データの量が大きくなると,PCIバスが制限要因となります。
持有从semilogx(大小、sendBandwidth“b -”、大小、gatherBandwidth' r . - ')举行在maxSendBandwidth semilogx(大小(maxSendIdx),“bo - - - - - -”,“MarkerSize”10);maxGatherBandwidth semilogx(大小(maxGatherIdx),“ro - - - - - -”,“MarkerSize”10);网格在标题(的数据传输带宽)包含(的数组大小(字节)) ylabel (传输速度(GB / s)的)传说(发送到GPU的,“从GPU收集”,“位置”,“西北”)

メモリ使用量の多い演算のテスト
多くの演算では配列の各要素を使った計算は極めて少なく,したがって,データをメモリから取得するまたはそれを書き込むために要する時間が大半となります。的、0、南、真正的などの関数は出力の書き込みのみを行います。一方、转置、下三角阵などの関数は読み取りと書き込みの両方を行いますが,計算を一切行いません。+、-、mtimesなどの単純な演算子も要素あたりの計算量は少なく,メモリアクセス速度によってのみ制限を受けます。
関数+は,各浮動小数点演算につき1回のメモリ読み取りと1回のメモリ書き込みを行います。したがって,メモリへのアクセス速度によって制限を受け,読み取りと書き込み操作の速度の優れた指標となります。
memoryTimesGPU =正(大小(尺寸));为ii=1: nummel (size) numElements = size (ii)/sizeOfDouble;gpuData = randi([0 9], numElements, 1,“gpuArray”);plusFcn = @() + (gpuData, 1.0);memoryTimesGPU (ii) = gputimeit (plusFcn);结束memoryBandwidthGPU = 2 * (sizes. / memoryTimesGPU) / 1 e9;[maxBWGPU, maxBWIdxGPU] = max(memoryBandwidthGPU);流(在GPU上达到峰值读写速度:%g GB/s\nmaxBWGPU)
GPU上达到峰值读写速度:186.494 GB/s
ここで,同じコードをCPUで実行した場合と比較します。
memoryTimesHost =正(大小(尺寸));为ii=1: nummel (size) numElements = size (ii)/sizeOfDouble;hostData = randi([0 9], numElements, 1);plusFcn = @() + (hostData, 1.0);memoryTimesHost时间(ii) = (plusFcn);结束memoryBandwidthHost = 2 * (sizes. / memoryTimesHost) / 1 e9;[maxBWHost, maxBWIdxHost] = max(memoryBandwidthHost);流('在主机上达到峰值读写速度:%g GB/s\n'maxBWHost)%绘制CPU和GPU结果。持有从semilogx(大小、memoryBandwidthGPU“b -”,...大小、memoryBandwidthHost' r . - ')举行在maxBWGPU semilogx(大小(maxBWIdxGPU),“bo - - - - - -”,“MarkerSize”10);maxBWHost semilogx(大小(maxBWIdxHost),“ro - - - - - -”,“MarkerSize”10);网格在标题(“阅读+写作带宽”)包含(的数组大小(字节)) ylabel (“速度(GB / s)”)传说(“图形”,“主机”,“位置”,“西北”)
主机读写速度达到峰值:40.2573 GB/s

このプロットを上記のデータ転送プロットと比較すると,通常GPUでは,ホストからデータを取得するよりずっと速くメモリからの読み取りとメモリへの書き込みができることは明らかです。したがって,ホストからGPUへ,またはGPUからホストへのメモリ転送の数を最小化することが重要です。理想としては,プログラムによってデータをGPUに転送し,GPU内でできるだけの処理を行って,完了したときにだけホストに戻すことが望まれます。さらに望ましいのは,最初からGPUでデータを作成することです。
計算量の多い演算のテスト
メモリから読み取られる,またはメモリに書き込まれる各要素に対し浮動小数点計算が数多く実行される演算では,メモリ速度の重要性はずっと低くなります。この場合は,浮動小数点演算装置の数と速度が制限要因となります。こうした演算は”計算密度”が高いと言われます。
計算パフォーマンスのテストに適しているのは行列と行列の乗算です。2つの![]() 行列を乗算する場合,浮動小数点計算の合計数は次になります。
行列を乗算する場合,浮動小数点計算の合計数は次になります。
![]()
入力行列が2つ読み取られ,結果の行列が1つ書き込まれるため,合計で![]() 個の要素の読み取りまたは書き込みが行われます。したがって,計算密度は
個の要素の読み取りまたは書き込みが行われます。したがって,計算密度は(2 n - 1) / 3フロップ/要素となります。先に使用した+の計算密度が1/2フロップ/要素であることと比較してください。
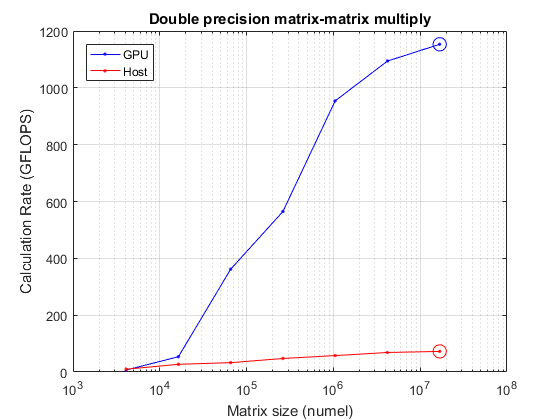
size = power(2, 12:2:24);N = sqrt(大小);mmTimesHost =正(大小(尺寸));mmTimesGPU =正(大小(尺寸));为2 = 1:元素个数(大小)%首先在主机上执行A = rand(N(ii), N(ii));B = rand(N(ii), N(ii));mmTimesHost(ii) = timeit(@() A*B);%现在在GPU上= gpuArray ();B = gpuArray (B);mmTimesGPU(ii) = gputimeit(@() A*B);结束mmGFlopsHost = (2 * N。^ 3 - n ^ 2)。/ mmTimesHost / 1 e9;[maxGFlopsHost, maxGFlopsHostIdx] = max (mmGFlopsHost);mmGFlopsGPU = (2 * N。^ 3 - n ^ 2)。/ mmTimesGPU / 1 e9;[maxGFlopsGPU, maxGFlopsGPUIdx] = max (mmGFlopsGPU);流([“达到峰值计算率”,...'%1.1f GFLOPS(主机),%1.1f GFLOPS (GPU)\n'],...maxGFlopsHost maxGFlopsGPU)
达到峰值计算率72.5 GFLOPS(主机),1153.3 GFLOPS (GPU)
ここでプロットを行い,ピークがどこにくるかを確認します。
持有从semilogx(大小、mmGFlopsGPU“b -”、大小、mmGFlopsHost' r . - ')举行在maxGFlopsGPU semilogx(大小(maxGFlopsGPUIdx),“bo - - - - - -”,“MarkerSize”10);maxGFlopsHost semilogx(大小(maxGFlopsHostIdx),“ro - - - - - -”,“MarkerSize”10);网格在标题('双精度矩阵-矩阵乘法')包含(的矩阵大小(元素个数)) ylabel (“计算率(GFLOPS)”)传说(“图形”,“主机”,“位置”,“西北”)
まとめ
以上のテストで,GPUパフォーマンスの重要な特徴がいくつか明らかになります。
ホストメモリとGPUメモリ間の転送は比較的低速である。
優れたGPUのメモリ読み取り/書き込みは,ホストCPUのメモリ読み取り/書き込みよりもずっと高速である。
データのサイズが十分大きい場合,GPUはホストCPUよりもずっと速く計算を実行できる。
それぞれのテストにおいて,GPUをメモリ面で,または計算面で完全に飽和状態にするにはかなり大きな配列が必要であるという点は注目に値します。GPUの利用は,何百万もの要素を同時に扱う際に最も有利となります。
さまざまなGPU間の比較を含む,より詳細なGPUベンチマークは,中央のMATLAB®文件交换のGPUBenchで入手できます。
你也可以从以下列表中选择一个网站: