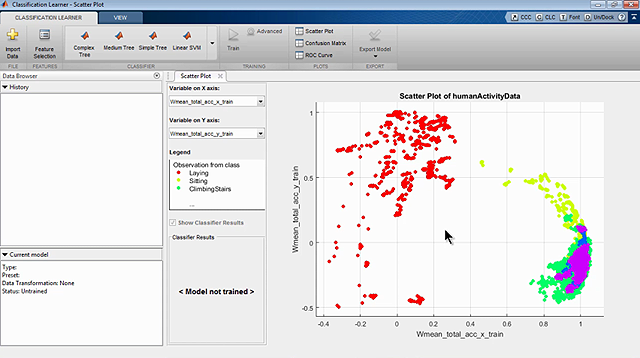
机器学习就是将模型与数据相匹配。模型由参数组成,我们通过拟合过程找到这些参数的值。该过程通常涉及某种类型的迭代算法,以最小化模型误差。该算法具有控制其工作方式的参数,我们称之为超参数。
在深度学习中,我们也将决定图层特征的参数称为超参数。今天,我们将讨论这两种参数的技术。
那么,我们为什么要关心超参数呢?事实证明,大多数机器学习问题都是非凸的。这意味着,根据我们为超参数选择的值,我们可能会得到完全不同的模型。通过改变超参数的值,我们可以找到不同的,希望更好的模型。
好的,我们知道我们有超参数,我们知道我们想要调整它们,但是我们怎么做呢?有些超参数是连续的,有些是二进制的,而另一些可能具有任意数量的离散值。这导致了一个棘手的优化问题。对超参数空间进行彻底的搜索几乎总是不可能的,因为它花费的时间太长了。
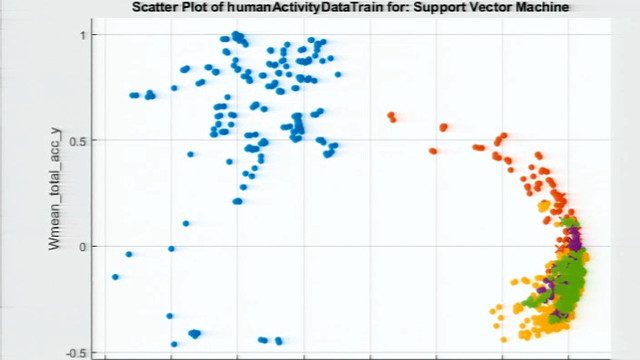
因此,传统上,工程师和研究人员使用网格搜索和随机搜索等超参数优化技术。在这个例子中,我使用网格搜索方法来改变SVM模型的两个超参数——框约束和核尺度。如您所见,对于超参数的不同值,结果模型的误差是不同的。经过100次试验,研究发现12.8和2.6是这些超参数最有希望的值。
最近,随机搜索比网格搜索更受欢迎。
“这怎么可能?”你可能会问。
网格搜索在均匀地探索超参数空间方面不是做得更好吗?
假设有两个超参数,“A”和“B”。您的模型对“A”非常敏感,但对“B”不敏感。如果我们进行3x3网格搜索,我们只会评估“A”的3个不同值。但是如果我们进行随机搜索,我们可能会得到9个不同的“A”值,尽管有些值可能很接近。因此,我们有更好的机会为“a”找到一个好的值。在机器学习中,我们通常有许多超参数。有些对结果有很大影响,有些则没有。因此,随机搜索通常是更好的选择。
网格搜索和随机搜索很好,因为它们很容易理解发生了什么。但是,它们仍然需要许多函数求值。它们也没有利用这样一个事实,即当我们求值越来越多的超参数组合时,我们了解这些值如何影响我们的结果。因此,您可以使用t创建一个代理模型,或作为超参数函数的误差近似值。
贝叶斯优化就是这样一种技术。这里我们看到一个运行贝叶斯优化算法的示例,其中每个点对应于不同的超参数组合。我们还可以看到该算法的代理模型,这里显示为曲面,用于拾取下一组超参数。
关于贝叶斯优化的另一个非常酷的事情是,它不仅仅关注模型的准确性。它还可以考虑训练所需的时间。可能有一组超参数会导致训练时间增加100倍或更多,如果我们试图在最后期限前完成训练,这可能不会太好。您可以通过多种方式配置贝叶斯优化,包括每秒的预期改善,这会惩罚预计需要很长时间训练的超参数值。
现在,进行超参数优化的主要原因是改进模型。而且,尽管我们还可以做其他事情来改进它,但我喜欢将超参数优化视为一种低工作量、高计算量的方法。这与特征工程(featureengineering)形成对比,在特征工程中,您需要更大的努力来创建新的特征,但您需要更少的计算时间。哪项活动的影响最大并不总是显而易见的,但超参数优化的好处在于它很适合“夜间运行”,这样你就可以在电脑工作时睡觉了。
这是超参数优化的一个快速解释。有关更多信息,请查看说明中的链接。