癌症检测
这个例子展示了如何训练神经网络使用于蛋白质谱质谱数据,以检测癌症。
介绍
血清蛋白组学模式诊断学可用于区分患者与非患者的样本。利用表面增强激光解吸和电离(SELDI)蛋白质质谱分析生成剖面模式。这项技术有可能改善癌症病理的临床诊断测试。
问题:癌症检测
目标是建立一个分类器,可以区分癌症和控制病人从质谱数据。
本例中所采用的方法是选择一组简化的测量值或“特征”,这些特征可用于使用分类器区分癌症患者和对照组患者。这些特征是离子强度水平在特定的质量/电荷值。
格式化数据
在本实施例中使用的数据是从FDA-NCI临床蛋白质组学程序资料库:https://home.ccr.cancer.gov/ncifdaproteomics/ppatterns.asp
要重新创建数据ovarian_dataset.mat在这个例子中,用于下载并解压缩从FDA-NCI网站的原始质谱数据。创建数据文件OvarianCancerQAQCdataset.mat按照以下步骤操作使用顺序和并行计算对光谱进行批处理(生物信息学工具箱)。新文件包含变量ÿ,MZ,GRP。
在每一列ÿ表示取自患者的测量。有216在列ÿ代表216病人,从哪来的121是卵巢癌患者和95是正常的病人。
每一行中ÿ表示在特定的质量电荷值的离子强度水平中指示MZ。有15000质荷值MZ每一行ÿ表示病人在特定质量电荷值下的离子强度水平。
的变量GRP保存这些样本中哪些代表癌症患者,哪些代表正常患者的索引信息。
这个数据集的详细描述可以在[1]和[2]中找到。
排名关键特性
该任务是一个典型的分类问题,特征的数量远远大于观测值的数量,但单个特征可以实现正确的分类。因此,我们的目标是找到一个分类器,它能适当地学习如何对多个特征进行加权,同时产生一个不过度拟合的广义映射。
查找显著特征的简单的方法是假设每个M / Z值是独立的,并且计算的双向t检验。rankfeatures返回一个索引到最显著M / Z值,例如100个指数排名由检验统计量的绝对值。
以完成对数据的重新创建ovarian_dataset.mat,加载OvarianCancerQAQCdataset.mat和rankfeatures从生物信息学工具箱中选择100个排名最高的测量值作为输入X。
印第安纳州= rankfeatures (Y, grp,'标准',的tt,'NumberOfIndices',100);:x = Y(印第安纳州);
定义目标Ť对于这两个类,如下所示:
双(t = strcmp ('癌症',GRP));T = [T;1-T];
上面列出的脚本和示例的预处理步骤是为了演示一组有代表性的可能的预处理和特性选择过程。使用不同的步骤或参数可以得到不同的、甚至可能更好的结果。
[X,T] = ovarian_dataset;谁是XŤ
名称大小字节类属性牛逼2x216 3456双X 100x216 172800双
在每一列X代表216个不同的病人中的一个。
每一行中X表示在用于每个患者的100个特定质荷值之一的离子强度水平。
的变量Ť有两行与216点的值的每一个或者是[1; 0],表示癌症患者,或[0; 1]对于正常患者。
分类使用前馈神经网络
现在您已经确定了一些重要的特征,您可以使用这些信息来对癌症和正常样本进行分类。
由于神经网络是用随机初始权值初始化的,所以每次运行示例时,训练后的网络结果略有不同。为了避免这种随机性,随机种子被设置为每次复制相同的结果。但是,在您自己的应用程序中不需要设置随机种子。
setdemorandstream (672880951)
A 1-隐藏层的前馈神经网络,用5层隐藏层的神经元被创建和训练。输入和目标样本自动分成训练,验证和测试集。训练集用于网络教学。培训只要网络不断完善的验证组仍在继续。测试集提供了网络精度的独立测量。
的输入和输出具有0尺寸,因为网络还没有被配置为匹配所述输入数据和目标数据。当你训练网络,这种配置情况。
网= patternnet (5);视图(净)
现在这个网络已经准备好接受培训了。这些样本被自动分为训练集、验证集和测试集。训练集用于网络教学。只要网络在验证集上不断改进,训练就会继续进行。测试集提供了对网络准确性的独立度量。
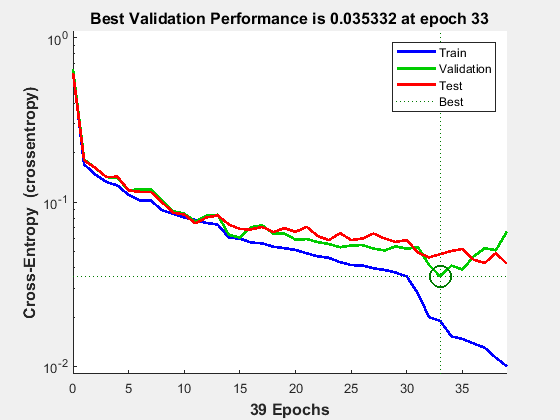
神经网络的训练工具显示网络被训练和算法用来训练它。它还训练过程中显示训练状态并停止训练的标准用绿色高亮显示。
在此期间可以和训练后,打开底部开有用地块的按钮。旁边的算法名称和情节按钮就这些议题进行开放文档链接。
(净,tr) =火车(净,x, t);
若要查看网络在培训期间的性能改进情况,请单击培训工具中的“性能”按钮,或使用plotperform功能。
性能是用平均平方误差来衡量的,并以对数刻度表示。随着网络的训练,它迅速减少。
性能给出了每个培训,验证和测试集的。
plotperform (tr)

训练的神经网络现在可以用我们从主数据集分区的测试样本进行测试。测试数据未在训练中使用任何方式,并因此提供了一个“外的样品”的数据集来测试在网络上。这给出了如何当来自真实世界的数据测试的网络将执行的估计。
网络输出的范围是0-1。阈值输出,得到1和0分别表示癌症或正常患者。
testX = x (:, tr.testInd);testT = t (:, tr.testInd);暴躁的=净(testX);testClasses = testY > 0.5
testClasses = 2 x32逻辑数组列1到19 0 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1列20通过32 0 0 0 1 0 0 0 0 0 0 0 0 0 1 1 1 0 1 1 1 1 1 1 1 1 1
的神经网络有多么合适的数据的一个措施是混乱的情节。
混淆矩阵显示了正确和错误分类的百分比。正确的分类是矩阵对角线上的绿色方块。红色方块代表不正确的分类。
如果网络是准确的,那么红色方块中的百分比就很小,表明错误分类很少。
如果网络不准确,那么你可以尝试训练更长的时间,或者训练一个有更多隐藏神经元的网络。
plotconfusion(testT,暴躁)
以下是正确和错误分类的总体百分比。
并[c,厘米] =混乱(testT,暴躁);fprintf中(正确分类百分比:%f%%\n',100 *(1-C));fprintf中('错误分类百分比:%f%%\n',100 * c);
百分比正确分类:90.625000%的百分比不正确的分类:9.375000%
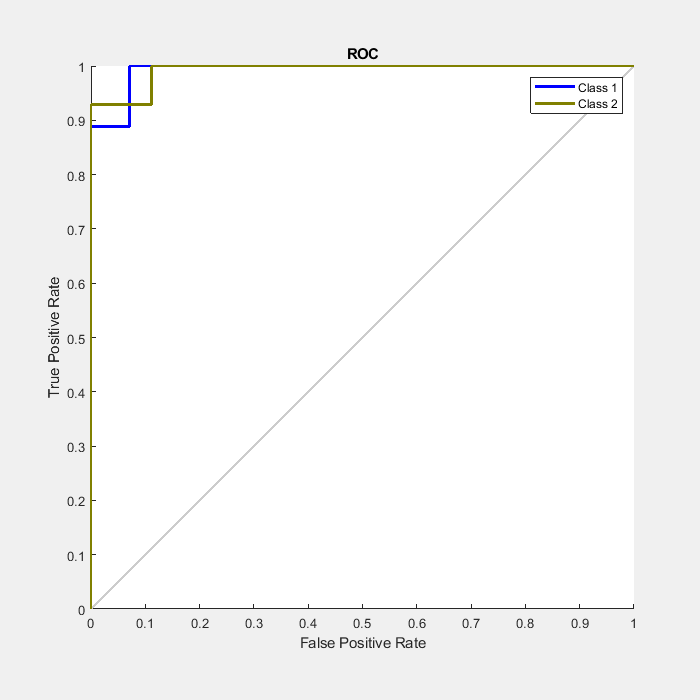
另一个衡量神经网络拟合数据好坏的方法是接收器工作特性图。此图显示了输出的阈值在0到1之间变化时假阳性和真阳性率之间的关系。
这条线越左越高,为了获得较高的真实阳性率,假阳性需要接受的次数就越少。最好的分类器有一条从左下角,到左上角,到右上角,或接近于此的线。
类1指示癌症患者和2级表示正常的患者。
plotroc (testT暴躁的)

这个例子演示了神经网络如何被用作癌症检测的分类器。为了提高分类器的性能,您还可以尝试使用主成分分析等技术来降低用于神经网络训练的数据的维数。
参考文献
[1] T.P.康拉德斯,等人,“高分辨率血清蛋白质组特征为卵巢检测”,内分泌相关癌症,11,2004,第163-178。
张建平,“血清蛋白质组学模式在卵巢癌诊断中的应用”,中华检验医学杂志,2002年,第572-577页。
你也可以从以下列表中选择一个网站:
