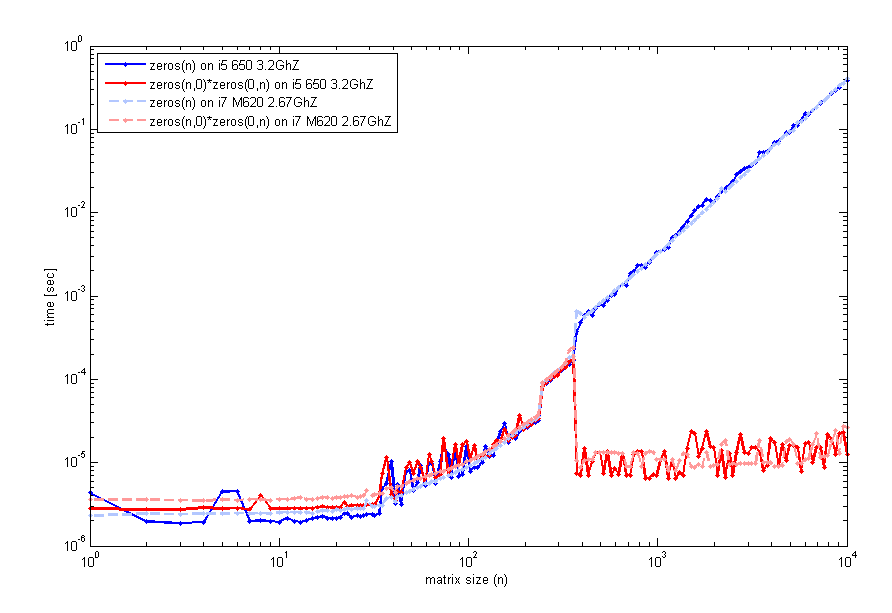
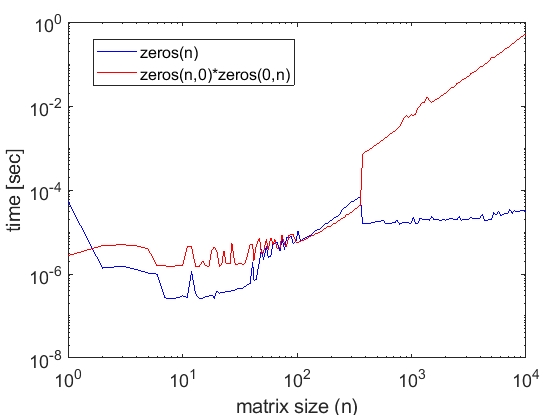
另一个(可能相关的)观察是MATLAB做一些pre 0填充背景的墨西哥人例程。例如,我运行下面的测试:
——通过mxMalloc分配一块很大的内存
——与非0的数据填补这一块
——还记得块地址
——自由与mxFree块
,立即再次与mxMalloc分配另一个非常大的块
——检查地址和内容
我发现第二个mxMalloc调用,返回相同的地址作为第一个电话,结果在数据块被设置为0。
这是设置数据块为0在后台调用mxFree和mxMalloc之间。如果一个定时的墨西哥人的例程可以探测到的努力为零的数据块的背景。但如果m文件层面上也有类似的事情发生(例如,有一个pre-0-filled数据块可供分配)它可能很难检测在计时。如果整件事是在一个循环中也许认为时机优势只会消失(如马特的例子)。
编辑
完成我对这个线程的墨西哥人相关的评论,我将提到有一个无证API调用“快0”函数mxFastZeros显然吸引了从以前分配内存并“0”了内存块,因为它非常快,可比时机0 (m, 0) * 0 (0, n)方法(我所知道的这种方法可能在后台调用mxFastZeros)。基本的墨西哥人程序实现如下:
/ / mxFastZeros。c生成一个零2 d双矩阵
/ /语法:z = mxFastZeros (ComplexFlag, M, N)
/ /地点:
/ / ComplexFlag = 0(真正的)或1(复杂的)
/ / M =行大小
/ / N =列的大小
/ /程序员:詹姆斯Tursa
#包括“mex.h”
mxArray* mxFastZeros (mxComplexity ComplexFlag, mwSize m, mwSize n);
mxArray* mxCreateSharedDataCopy (mxArray * mx);
无效mexFunction (int nlhs mxArray * plhs [], int nrhs, const mxArray * prhs [])
{
mxArray * mx;
mxComplexity ComplexFlag;
mwSize m, n;
如果(nrhs ! = 3) {
mexErrMsgTxt (“语法:mxFastZeros (ComplexFlag, M, N)”);
}
如果(nlhs > 1) {
mexErrMsgTxt (“太多的输出”。);
}
ComplexFlag = mxGetScalar (prhs [0]);
m = mxGetScalar (prhs [1]);
n = mxGetScalar (prhs [2]);
mx = mxFastZeros (ComplexFlag, m, n);
plhs [0] = mxCreateSharedDataCopy (mx);
mxDestroyArray (mx);
}
注意高级程序员:需要共享数据复制的东西因为mxFastZeros产生正常mxArray
(
不
在垃圾收集名单上),而不是一个临时mxArray
(
在
垃圾收集列表)记录API函数。使用mxCreateSharedDataCopy函数允许墨西哥人的例程返回一个临时mxArray和防止内存泄漏,会发生如果mxFastZeros的结果直接返回plhs [0]。