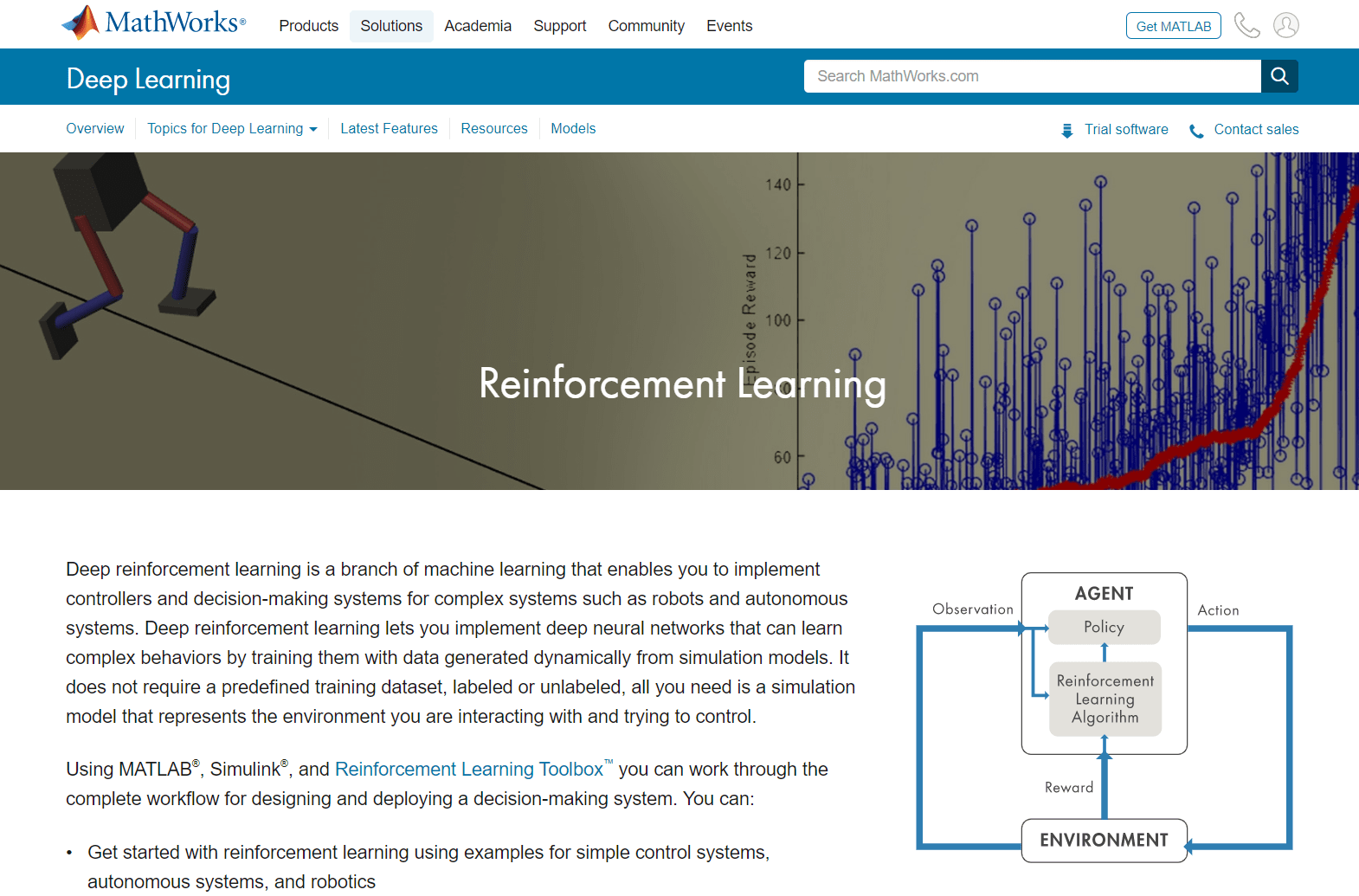
强化学习是一种机器学习技术,计算机代理学习通过重复的试验和与动态环境的错误交互来执行任务。这种学习方法使代理能够做出一系列决策,可以最大化任务的奖励度量,而没有人为干预,而不明确地编程以实现任务。
AI计划培训,加强学习击败人类参与者在棋盘游戏中,如加入和国际象棋,以及视频游戏。虽然强化学习绝不是一个新的概念,但最近的深度学习和计算能力的进步使得可以在人工智能领域实现一些显着的结果。
加固学习与机器学习与深度学习
强化学习是机器学习的分支(图1)。与无监督和监督的机器学习不同,加固学习不依赖于静态数据集,但在动态环境中运营并从收集的经验中学习。在培训期间通过环境和软件代理之间的试错交互来收集数据点或经验。强化学习的这一方面很重要,因为它减轻了在训练前需要进行数据收集,预处理和标签,否则在监督和无监督的学习中必要。实际上,这意味着,鉴于正确的激励,加强学习模型可以在没有(人)监督的情况下开始学习行为。
深度学习涵盖了所有三种类型的机器学习;强化学习和深度学习并不是相互排斥的。复杂的加强学习问题往往依赖于深度神经网络,这是一种被称为深度加强学习的领域。
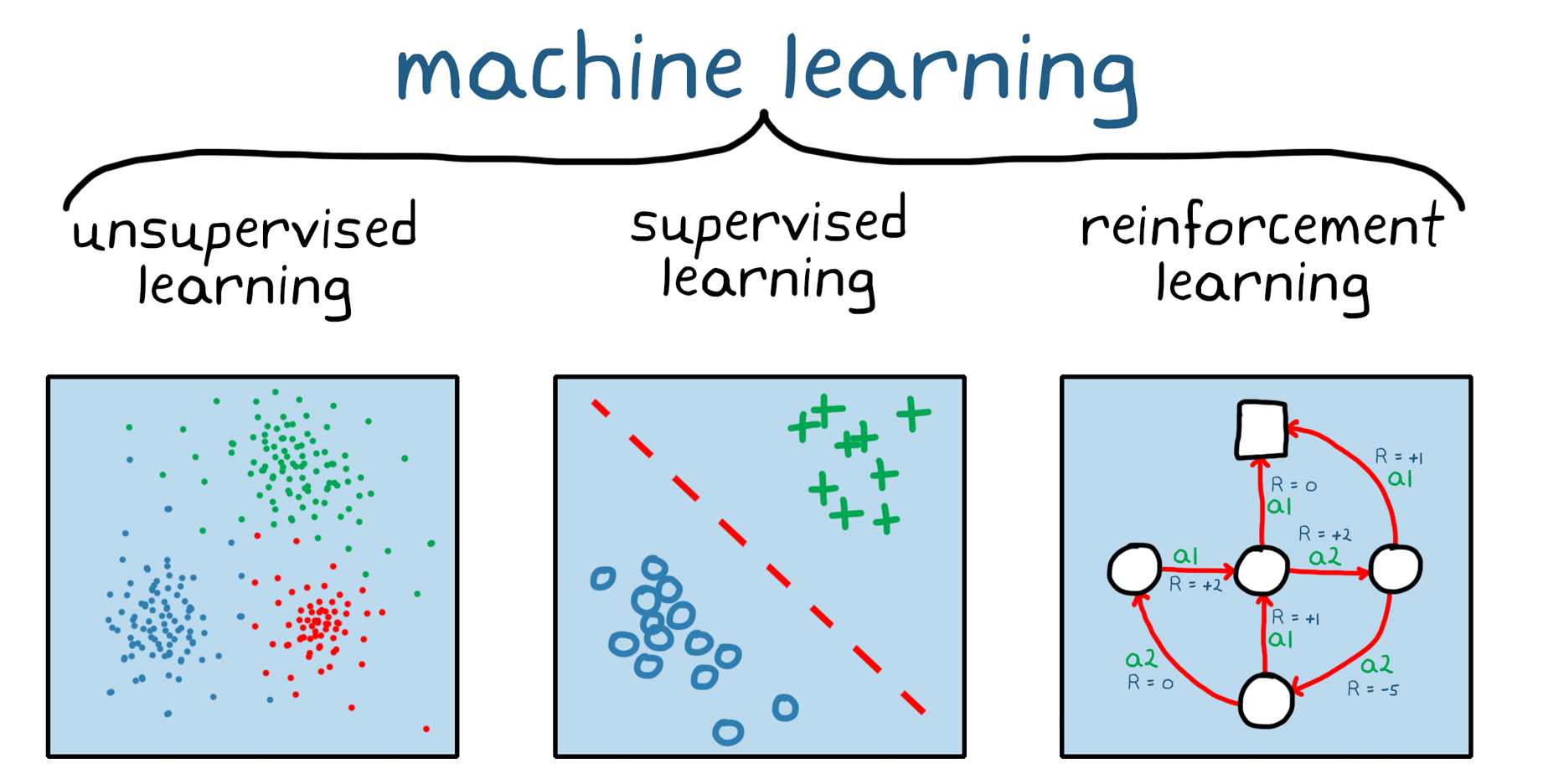
图1.三种广泛类别的机器学习:无监督学习,监督学习和加强学习。


强化学习应用的例子
深神经网络有钢筋学习培训可以编码复杂的行为。这允许替代方法对否则难以应变或更具挑战来解决更传统的方法的应用。例如,在自动驾驶中,神经网络可以通过同时查看诸如相机帧和激光雷达测量的多个传感器来决定如何通过同时查看转向轮。没有神经网络,问题通常会在较小的块中分解,如从相机帧中提取特征,过滤激光雷达测量,融合传感器输出,并根据传感器输入制作“驾驶”决策。
虽然作为一种方法的加固学习仍然在生产系统的评估中,一些工业应用是这种技术的良好候选者。
先进的控件:控制非线性系统是一个具有挑战性的问题,通常通过在不同的操作点线性化系统来解决。增强学习可以直接应用于非线性系统。
自动驾驶:根据相机输入制作驾驶决策是强化学习适用于考虑图像应用中深神经网络成功的领域。
机器人:加固学习可以帮助掌控抓获等应用,例如教导机器人手臂如何操纵各种对象进行拾取应用。其他机器人应用包括人机和机器人机器人协作。
安排:调度问题出现在许多场景中,包括交通灯控制和工厂地板上的协调资源朝向某些目标。强化学习是解决这些组合优化问题的进化方法的良好替代方法。
校准:涉及手动校准参数的应用,例如电子控制单元(ECU)校准,可能是加强学习的良好候选者。
钢筋学习背后的培训机制反映了许多现实世界的情景。考虑,例如,通过积极的加强培训。

图2.狗训练中的加强学习。
使用钢筋学习术语(图2),在这种情况下学习的目标是训练狗(代理)在环境中完成一项任务,包括狗的周围和培训师。首先,培训师发出命令或提示,狗观察(观察)。然后狗采取行动响应。如果该行动接近所需的行为,培训师可能会提供奖励,例如食物治疗或玩具;否则,将不提供奖励。在培训开始时,当给出的命令是“坐下”时,狗可能需要更多随机的动作,如“坐下”的命令,因为它试图将特定的观察与动作和奖励联系起来。此关联或映射在观察和操作之间称为策略。从狗的角度来看,理想的案例将是它将正确响应每个提示的理想情况,以便它尽可能多的零食。因此,加强学习培训的整个意义是“调整”狗的政策,以便它学会最大化一些奖励的所需行为。培训完成后,狗应该能够观察所有者并采取适当的行动,例如,当使用它开发的内部政策命令“坐下”时坐着。 By this point, treats are welcome but, theoretically, shouldn’t be necessary.
请记住狗训练示例,考虑使用自动化驱动系统停放车辆的任务(图3)。目标是将车辆计算机(代理)教授与加强学习的正确停车位停放。与狗训练案一样,环境是代理以外的一切,并且可以包括车辆的动态,可能在附近,天气条件等车辆。在培训期间,代理商使用传感器的读数,例如摄像机,GPS和LIDAR(观察结果)来产生转向,制动和加速命令(动作)。要了解如何生成从观察(策略调整)的正确操作(策略调整),代理重复尝试使用试验和错误过程停止车辆。可以提供奖励信号来评估试验的良善度并指导学习过程。
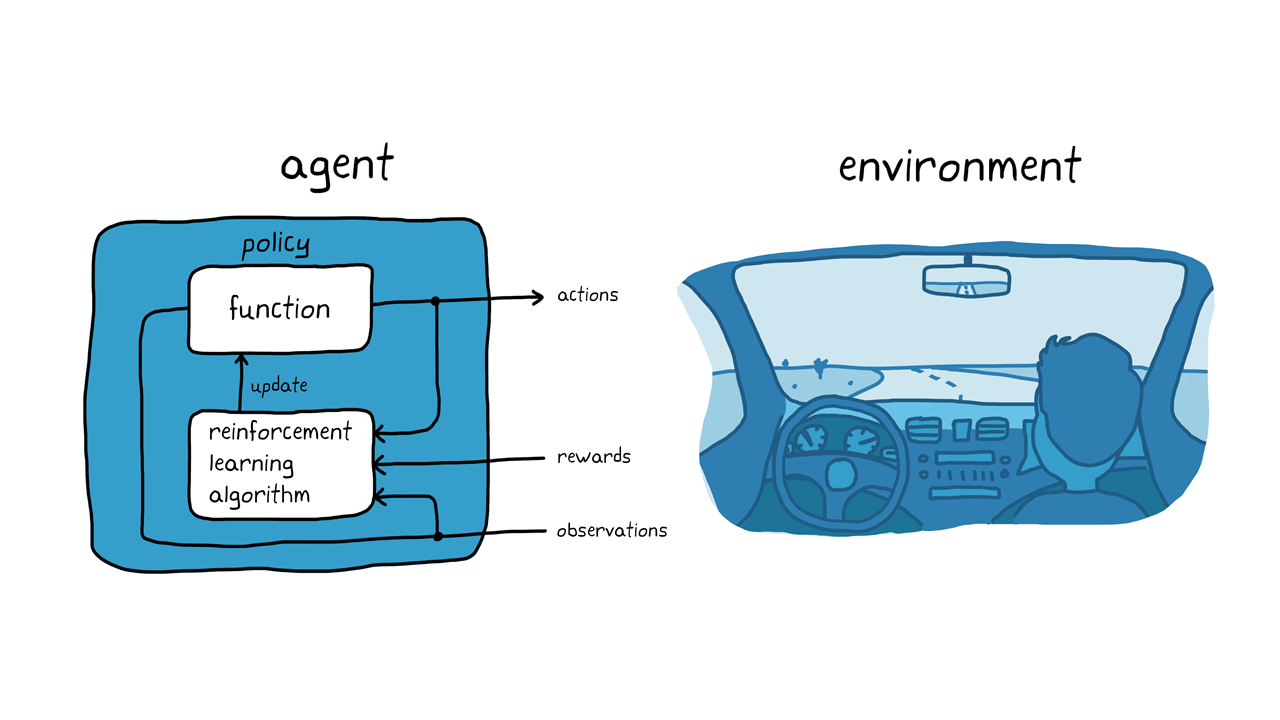
图3.自动停车处的加强学习。
在狗训练的例子中,训练正在发生在狗的大脑里面。在自动停车示例中,培训由培训算法处理。培训算法负责根据收集的传感器读数,操作和奖励调整代理的策略。培训完成后,车辆的计算机应该只能使用调谐策略和传感器读数停放。
要记住的一件事是加强学习不是效率。也就是说,它需要代理和环境之间的大量交互来收集培训的数据。作为一个例子,首先是在去游戏中击败世界冠军的第一台计算机程序的alphago在几天的游戏中训练了一段时间,积累了数千年的人类知识。即使对于相对简单的应用,培训时间也可以在几分钟到几小时或几天。此外,正确设置问题可能是具有挑战性的,因为有需要进行的设计决策列表,这可能需要几个迭代来实现正确。这些包括例如选择适当的神经网络,调整超参数和奖励信号的整形。
加强学习工作流程
使用强化学习培训代理的一般工作流程包括以下步骤(图4):

图4.加强学习工作流程。
1.创建环境
首先,您需要定义强化学习代理的操作,包括代理和环境之间的接口。环境可以是仿真模型,或实际物理系统,但模拟环境通常是良好的第一步,因为它们更安全并允许实验。
2.定义奖励
接下来,指定代理用于根据任务目标测量其性能的奖励信号以及如何从环境中计算该信号。奖励塑造可能是棘手的,可能需要一些迭代来实现它。
3.创建代理
然后您创建代理,该代理包括策略和加强学习培训算法。所以你需要:
a)选择代表策略的方法(例如使用神经网络或查找表)。
b)选择适当的训练算法。不同的表示通常与特定类别的培训算法相关联。但总的来说,大多数现代化的加强学习算法依赖神经网络,因为它们是大状态/行动空间和复杂问题的良好候选者。
4.培训并验证代理人
设置培训选项(如停止标准)并培训代理商调整政策。培训结束后确保验证培训的策略。如有必要,请重新审视设计选择,如奖励信号和政策架构和策略再次列车。众所周知,增强学习是样本效率;培训可以在几分钟内到几天,具体取决于申请。对于复杂的应用程序,在多个CPU,GPU和计算机集群上并行化培训将速度速度(图5)。
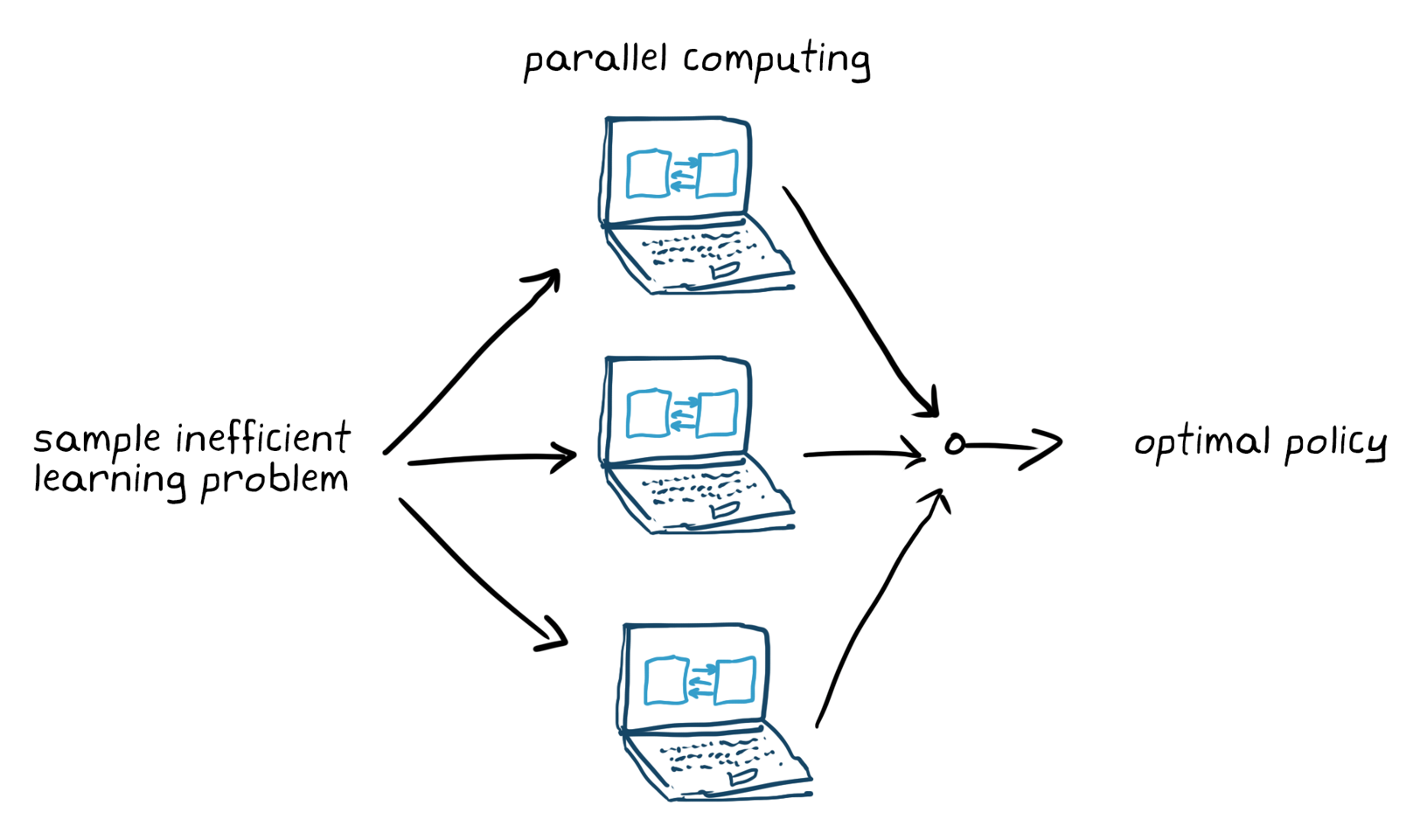
图5.并行计算训练样本效率低效学习问题。
5.部署策略
使用例如生成的C / C ++或CUDA代码部署训练策略表示。此时,该政策是独立的决策系统。
使用强化学习培训代理商是一个迭代过程。决策和结果在以后的阶段可以要求您在学习工作流程中返回早期阶段。例如,如果培训过程在合理的时间内不会收敛到最佳策略,则可能必须在刷新代理之前更新以下任何内容:
- 培训设置
- 强化学习算法配置
- 政策代表性
- 奖励信号定义
- 动作和观察信号
- 环境动态
马铃薯®和强化学习工具箱™简化强化学习任务。您可以通过通过加强学习工作流程的每一步,为机器人和自主系统等复杂系统实施控制器和决策算法。具体来说,你可以:
1.使用matlab和simulink创建环境和奖励函数金宝app®
2.使用深神经网络,多项式和查找表来定义强化学习策略
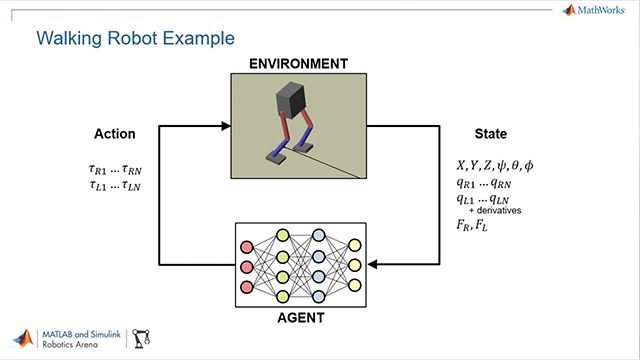
图6教授一款双层机器人与钢筋学习工具箱™一起行走
3.切换,评估和比较流行的强化学习算法,如DQN,DDPG,PPO和SAC,只有次要代码更改,或创建自己的自定义算法
4.使用并行计算工具箱™和MATLAB并行服务器™通过利用多个GPU,多个CPU,计算机集群和云资源来培训加固学习策略
5.使用Matlab Coder™和GPU编码器™生成代码并部署嵌入式设备的嵌入式设备
6.使用加强学习开始使用参考例子。
快速开始

加固学习ondramp.
开始加固学习方法进行控制问题。






30天免费试用

问题?
您还可以从以下列表中选择一个网站: