创建用于分类的简单文本模型
这个例子展示了如何使用单词袋模型训练一个简单的文本分类器的单词频率计数。
您可以创建一个简单的分类模型,使用单词频率计数作为预测因素。这个例子训练了一个简单的分类模型来使用文本描述预测工厂报告的类别。
加载和提取文本数据
加载示例数据factoryReports.csv包含工厂报告,包括每个报告的文本描述和分类标签。
文件名=“factoryReports.csv”; 数据=可读性(文件名,“文本类型”,“字符串”);总目(数据)
ans =8×5表UUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUU“机械故障”“介质”“重新调整机器”45“装配机活塞发出巨大的卡嗒卡嗒声和砰砰声。”“机械故障”“中等”“重新调整机器”35“启动设备时电源中断。”“电子故障”“高”“完全更换”16200“装配机中的油炸电容器。”“电子故障”“高”“更换部件”352“混合器使保险丝跳闸。”“电子故障”“低”“添加到观察列表”“55”“施工剂中的爆裂管正在喷射冷却剂”“泄漏”“高”“更换部件”“371”“混合器中的保险丝熔断”“电子故障”“低”“更换部件”“441”“皮带继续脱落”“机械故障”“低”“重新调整机器”38
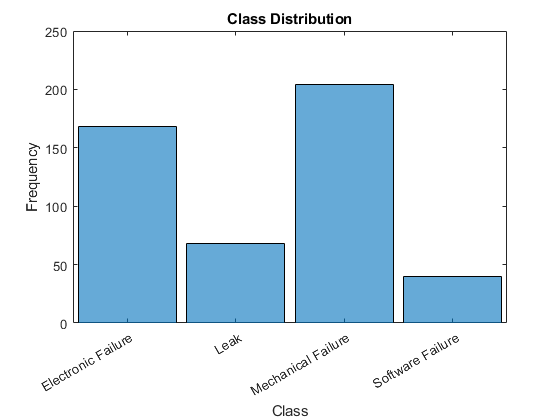
中的标签转换类别将表中的列分类,并使用直方图查看数据中类的分布。
data.Category=分类(data.Category);图形直方图(data.Category)xlabel(“类”) ylabel (“频率”)标题(“阶级分布”)
将数据划分为训练分区和保留测试集。指定保留百分比为10%。
cvp=cvpartition(data.Category,“坚持”, 0.1);dataTrain =数据(cvp.training:);人数(=数据(cvp.test:);
从表中提取文本数据和标签。
textDataTrain=dataTrain.Description;textDataTest=dataTest.Description;YTrain=数据列车。类别;YTest=dataTest.Category;
准备文本数据进行分析
创建一个函数,用于标记和预处理文本数据,以便用于分析。这个函数preprocessText,依次执行以下步骤:
使用标记文本
tokenizedDocument.使用删除停止词列表(如“and”、“of”和“the”)
removeStopWords.使使用的词义化
正常化森林.删除标点符号使用
erasePunctuation.使用删除包含2个或更少字符的单词
removeShortWords.使用删除包含15个或更多字符的单词
removeLongWords.
使用示例预处理函数preprocessText准备文本数据。
文件= preprocessText (textDataTrain);文档(1:5)
ans=5×1标记文档:6个标记:项目偶尔会卡住扫描仪滑阀7个标记:响亮的嘎嘎声传来装配机活塞4个标记:切断电源启动设备3个标记:油炸电容器装配机3个标记:混合器跳闸保险丝
从标记化的文档创建单词袋模型。
袋= bagOfWords(文档)
bag=bagOfWords和properties:Counts:[432×336 double]词汇:[1×336字符串]NumWords:336 NumDocuments:432
从单词袋模型中删除总出现次数不超过两次的单词。从单词袋模型中删除任何不包含单词的文档,并删除标签中相应的条目。
bag=删除常用词(bag,2);[bag,idx]=删除的空文档(bag);YTrain(idx)=[];纸袋
bag=bagOfWords,属性:Counts:[432×155 double]词汇:[1×155字符串]NumWords:155 NumDocuments:432
训练监督分类器
使用单词袋模型和标签中的单词频率计数训练监督分类模型。
利用遗传算法训练多类线性分类模型fitcecoc。指定计数属性作为预测器,事件类型标签作为响应。指定学习者是线性的。这些学习者支持稀疏数据输入。金宝app
XTrain = bag.Counts;mdl = fitcecoc (XTrain YTrain,“学习者”,“线性”)
mdl=CompactClassificationCoC ResponseName:'Y'类名称:[电子故障泄漏机械故障软件故障]ScoreTransform:'none'二进制读取器:{6×1单元}编码矩阵:[4×6双]属性、方法
为了更好地匹配,您可以尝试指定线性学习器的不同参数。有关线性分类学习器模板的更多信息,请参阅模板线性.
测试分类器
使用训练好的模型预测测试数据的标签,并计算分类精度。分类精度是模型正确预测的标签的比例。
使用与训练数据相同的预处理步骤对测试数据进行预处理。根据单词袋模型,将生成的测试文档编码为单词频率计数矩阵。
documentsTest=预处理文本(textDataTest);XTest=编码(包,documentsTest);
利用训练好的模型对测试数据进行标签预测,并计算分类精度。
YPred=预测(mdl,XTest);acc=总和(YPred==YTest)/numel(YTest)
acc=0.8542
使用新数据进行预测
对新工厂报告的事件类型进行分类。创建包含新工厂报告的字符串数组。
str = [“冷却剂在分拣机下面汇集。”“分类器在启动时烧断保险丝。”“从组装器里传出很响的咔哒声。”];documentsNew=预处理文本(str);XNew=编码(bag,documentsNew);labelsNew=预测(mdl,XNew)
新标签=3×1范畴泄漏电子故障机械故障
例子预处理功能
这个函数preprocessText,依次执行以下步骤:
使用标记文本
tokenizedDocument.使用删除停止词列表(如“and”、“of”和“the”)
removeStopWords.使使用的词义化
正常化森林.删除标点符号使用
erasePunctuation.使用删除包含2个或更少字符的单词
removeShortWords.使用删除包含15个或更多字符的单词
removeLongWords.
函数文件= preprocessText (textData)标记文本。文件= tokenizedDocument (textData);删除一个停止词列表,然后对这些词进行lemmalize。改善%词源化,首先使用addpartfspeech details。= addPartOfSpeechDetails文件(文档);= removeStopWords文件(文档);文档= normalizeWords(文档,“风格”,“引理”);%擦掉标点符号。= erasePunctuation文件(文档);%删除2个或更少字符的单词,以及15个或更多字符的单词%字符。文件= removeShortWords(文件,2);= removeLongWords文档(文档、15);终止
另见
erasePunctuation|tokenizedDocument|巴格沃兹|removeStopWords|removeLongWords|removeShortWords|正常化森林|wordcloud|addPartOfSpeechDetails|编码
相关的话题
你也可以从以下列表中选择一个网站:
