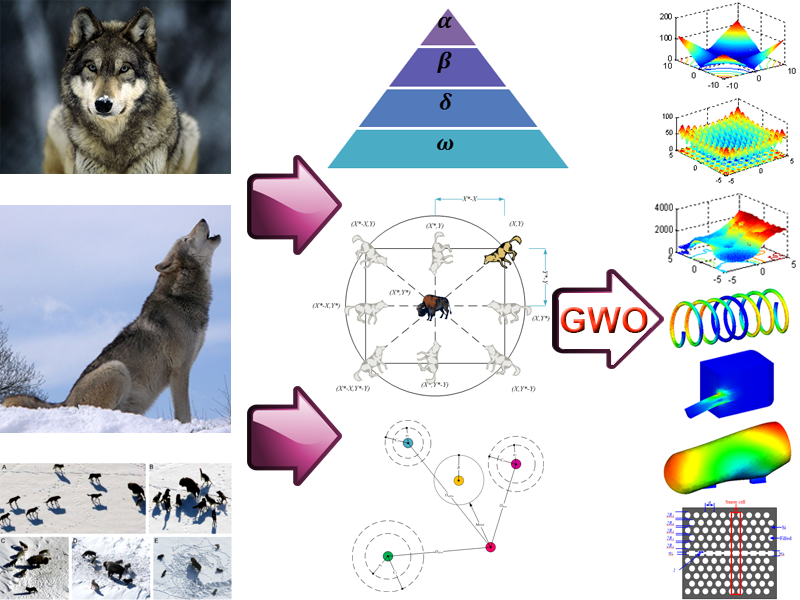
GWO算法模拟了自然界中灰狼的领导层级和捕猎机制。采用alpha、beta、delta、omega四种灰狼来模拟领导层级。此外,还实施了寻找猎物、包围猎物和攻击猎物三个主要步骤进行优化。
这是论文的源代码:S. Mirjalili, S. M. Mirjalili, A. Lewis,灰狼优化器,Advances in Engineering Software,卷69,2014年3月,46-61页,ISSN 0965-9978。http://dx.doi.org/10.1016/j.advengsoft.2013.12.007.
更多资料可浏览:http://www.alimirjalili.com/GWO.html
你可以在这里找到灰狼优化工具箱://www.tatmou.com/matlabcentral/fileexchange/47258-grey-wolf-optimizer-toolbox
其他相关意见书:https://au.mathworks.com/matlabcentral/fileexchange/49772-grey-wolf-optimizer-for-training-multi-layer-perceptrons
我在这方面有很多相关的课程。您可透过以下连结报名,享受九五折优惠:
*******************************************************************************************************************************************
《优化问题与算法:如何理解、表述和解决优化问题》课程:
https://www.udemy.com/optimisation/?couponCode=MATHWORKSREF
“遗传算法导论:理论与应用”课程
https://www.udemy.com/geneticalgorithm/?couponCode=MATHWORKSREF
*******************************************************************************************************************************************
引用作为
塞耶达利·米贾利利(2020)。灰狼优化(GWO)(//www.tatmou.com/matlabcentral/fileexchange/44974-grey-wolf-optimizer-gwo), MATLAB中央文件交换。检索.
评论及评分(41)
更新
| 1.6 | 链接补充道: |
|
| 1.6.0.0 | 输入错误 |
|
| 1.6.0.0 | 描述中添加链接 |
|
| 1.5.0.0 | 该提交现在可以在R2014b中作为工具箱文件使用。 |
|
| 1.4.0.0 | 错误修复 |
|
| 1.3.0.0 | 论文已包含在提交的文件中。 |
|
| 1.2.0.0 | 添加了到GWO工具箱的链接。 |
|
| 1.1.0.0 | 边界检查中的一个问题已解决,源文件已更新。 |
我想知道它是否可以适用于机器人路径规划,但我还没有找到代码
查看我的github,我在Python (Numpy)中实现了这个算法,以获得更好的性能。
https://github.com/thieunguyen5991/metaheuristics
嘿,亲爱的,我怎么能使用GWO微电网优化,如果你能发送源代码比你的支持金宝app
如何在这个程序中加入约束
你好先生,
在图像融合(频域)中是否可以应用GWO,如果可以,如何裁剪?
你好,先生
为什么每次运行程序时Best_pos的结果都不同?期待您的回复!
你好,先生
为什么每次运行程序时Best_pos的结果都不同?期待您的回复!
清除所有
clc
SearchAgents_no = 20;%搜索座席数
func_name =“DG1”;%可从F1到F23的测试函数名称(文中表1、2、3)
Max_iteration = 100;%最大迭代次数
%加载所选基准函数的详细信息
[磅,乌兰巴托,昏暗,fobj] = Get_Functions_details(“DG1”);
[Best_score, Best_pos GWO_cg_curve] =拥有(SearchAgents_no Max_iteration,磅,乌兰巴托,昏暗,fobj);
图('Position',[500 500 660 290])
绘制搜索空间
次要情节(1、2、1);
% func_plot (func_name);
标题(“参数空间”)
包含(x_1);
ylabel (x_2);
Zlabel ([func_name,'(x_1, x_2)'])
%
% %绘制客观空间
%次要情节(1、2、2);
% semilogy (GWO_cg_curve,“颜色”,“r”)
% title('目标空间')
%包含(“迭代”);
% ylabel('迄今为止获得的最佳分数');
轴紧度%
%栅格
% box on
%的传说(“拥有”)
display([' GWO获得的最佳解为:',num2str(Best_pos)]);
display([' GWO找到的目标函数的最优值为:',num2str(Best_score,'%10.9e\n')]);
这是第47行错误,有人能告诉我吗
你好,
我在IEEE-14,33和69总线系统工作,我想申请GWO,谁能告诉我如何在matlab实验室中实现GWO的价值
查看GWO和PSO的混合代码https://in.mathworks.com/matlabcentral/fileexchange/68776-hybrid-gwopso-optimization为了更好的性能
你好先生,
请,我想用GWo选择最佳的RBF (sigma,c)参数的SVM分类器。
但我不知道如何修改代码来解决我的问题。
请问,你能给我一些提示或密码吗?
我的问候。
你好,所有人
我将这种GWO技术应用于LFC问题。
我得到的错误是
???下标索引必须是实正整数或逻辑整数。
==> GWO在50时出错
健身= fobj(职位(我,:));
有谁能解决我的错误,使它对我有帮助吗
我使用GWO,但我想添加约束,所有变量的总和应该是一个…我不知道如何在GWO实现约束?
您好,Seyedali,您能将GWO应用于海上结构优化吗?如果是这样,你如何调整它?
亲爱的GWO主matlab文件不接受fobj。那是什么?是'F1','F2' .....?
你好
我想要的代码为灰狼算法写在语言MATLAB,请。
先生如何输入目标函数
如何计算GWO中猎物的x_p ?以及xp在GWO中的作用。
您好seyedali先生,感谢您的代码,我想纳入平等约束,例如,如果需求pd=100兆瓦,发电应该是100兆瓦,你能提供这个问题的解决方案吗?谢谢先生,我会等待您的回复。
先生你好,这个GWO能解决经济调度问题吗?他们有什么matlab代码吗??
你好先生,首先恭喜你!为了这个很棒的技巧。一个问题:当我在这段代码中使用目标函数时。全局最佳分数不会随着迭代而改变。例如,如果我进行了100次迭代,那么第一次迭代的值、迭代之间的值和最后一次迭代的值保持不变。有什么建议吗,先生?
嗨,先生
源代码尚未更新
我需要尽快拿到它
嗨。先生
我想问一下GWO-EPD的代码是什么?
先生您好,这个GWO能解决经济负荷调度问题吗?
嗨,海森先生,
感谢您发现这个问题。你说得对。每次更新,我们都要更新和。我会考虑并尽快更新文件。
嗨,谢谢你的代码。好工作Beta_score =健身;%更新测试版Delta_score =健身;%更新增量
只有一个问题。如果我说错了,请纠正我。更新Alpha, Beta和Delta位置和分数时
(引用)
健身= fobj(职位(我,:));%Amr: best_tour =计算在tsp中的行程长度
%更新Alpha, Beta和Delta
如果健身< Alpha_score
Alpha_score =健身;%更新alpha
Alpha_pos =位置(我:);
结束
如果fitness>Alpha_score && fitness
Beta_pos =位置(我:);
结束
如果fitness>Alpha_score && fitness>Beta_score && fitness
Delta_pos =位置(我:);
结束
(/报价)
这不能正确更新Beta和Delta。考虑这个场景:
例如,在第三次迭代之后,alpha_score=1000, Beta_score=1200, Delta_score=1500
如果第四次迭代的适应度是800,那么alpha_score将被更新,beta_score将保持1200,而它应该是1000,delta_score也是如此
提出了修正,
(引用)Delta_score = Beta_score;Delta_score =健身;%更新增量
健身= fobj(职位(我,:));%Amr: best_tour =计算在tsp中的行程长度
%更新Alpha, Beta和Delta
如果健身< Alpha_score
Beta_score = Alpha_score;
Beta_pos = Alpha_pos;
Alpha_score =健身;%更新alpha
Alpha_pos =位置(我:);
结束
如果fitness>Alpha_score && fitness
Delta_pos = Beta_pos;
Beta_score =健身;%更新测试版
Beta_pos =位置(我:);
结束
如果fitness>Alpha_score && fitness>Beta_score && fitness
Delta_pos =位置(我:);
结束
(/报价)
一种基于灰狼行为的启发式算法。哇。哇。
嗨Dalia,
这个问题源于你的F5函数。
O =(100*(x(2:dim)-(x(1:dim-1).^2)).^2+(1-x(1:dim-1)).^2)返回一个向量,而每个搜索代理应该有一个单一的适应度值。
F5函数的公式在表达式前面加一个和,如下所示:
o =总和(100 * (x(2:昏暗的)——(x (1: dim-1)。^ 2))^ 2 + (x (1: dim-1) 1) ^ 2);
一般来说,每个搜索代理应该只分配一个适应度值。
改变你的F5函数,使它为每个输入向量返回一个单一的值,给它一个尝试,让我知道。
阿里
我试着解这个方程
函数0 = F5(x)
昏暗的=大小(x, 2);
o = (100 * (x(2:昏暗的)——(x (1: dim-1)。^ 2))^ 2 + (1 - x (1: dim-1)) ^ 2);
结束
例“F5”
fobj = @F5;
磅= - [-1.5,2];
乌兰巴托= (2,2);
昏暗的= 2;
给我一个错误
||和&&操作符的操作数必须转换为逻辑标量值。
GWO中的错误(第51行)
如果fitness>Alpha_score && fitness
main中出现错误(第45行)
[Best_score, Best_pos GWO_cg_curve] =拥有(SearchAgents_no Max_iteration,磅,乌兰巴托,昏暗,fobj);
请帮帮我
丹尼尔,
你是对的,一些搜索代理在最后一次迭代中可能会超出搜索空间的边界,并且没有更多的机会将它们返回到搜索空间。我将位置边界检查移动到第二个for循环的末尾(就在更新位置之后)。我也相应地更新了源文件。
谢谢,如果还有其他问题,请告诉我。
当您进入循环进行第一次运行时,您的数据处于先验边界中(因为它刚刚生成)。当你做_last_循环迭代时你可能会有一些搜索代理不在边界内,所以当你看最终位置时,你可能会发现不正确的数据。
当我试图使用整数值的搜索代理时,我发现了这一点:我的界限是1..10,但在最后一次循环迭代之后,我得到了几个0的代理。也许对于实际值,它不是很重要。
嗨,丹尼尔,
谢谢你的称赞和评论。我认为当前的代码是正确的,因为当你想要计算它们的“适应度”时,返回超出边界的搜索代理是很重要的。我同意你的观点,我们可以在第二个for循环结束时更新位置,或者在第一个for循环的顶部这样做。然而,这里重要的问题是,边界检查应该在更新适应度之前完成。我希望这些是有意义的。再次感谢你的警惕和指出这件事。
问候,
阿里
嗨。伟大的优化器。谢谢你!
我发现了一个问题:我们需要在“for”循环的底部执行“返回超出搜索边界的粒子”,而不是在顶部。