集群评估
此示例显示了如何识别Fisher虹膜数据中的簇。
加载Fisher的虹膜数据集。
加载渔业x = meas;y =分类(物种);
X是一个数字矩阵,其中包含150个虹膜的两个花瓣测量。y是包含相应虹膜物种的字符矢量的细胞阵列。
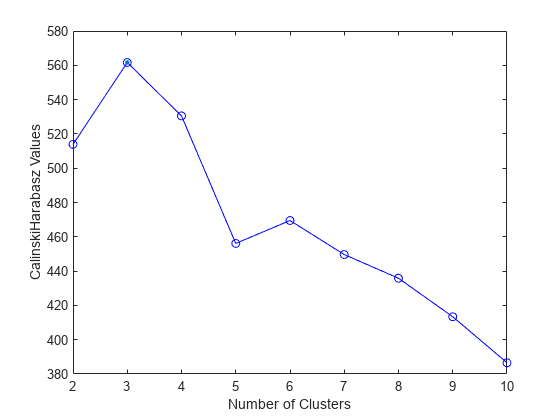
评估多个簇从1到10。
eva = estarclusters(x,'kmeans',,,,'Calinskiharabasz',,,,'klist',1:10)
eva =具有特性的Calinskiharabaszeveruation:Numobservations:150 theckedk:[1 2 3 4 5 6 7 8 9 10] CriterionValues:[NAN 513.9245 561.6278 530.4871 456.1279 456.1279 469.5068 ...] 469.5068 ... 3
这Optimalk值表明,基于Calinski-Harabasz标准,最佳簇数为三个。
可视化伊娃查看每个簇数量的结果。
情节(EVA)
大多数聚类算法都需要对集群数量的先验知识。当此信息不可用时,请使用群集评估技术来确定基于指定度量的数据中存在的簇数。
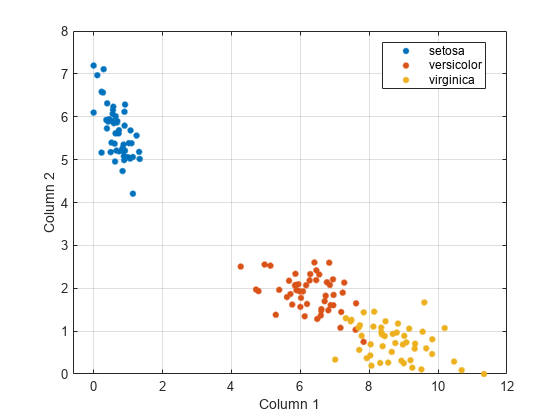
三个簇与数据中的三个物种一致。
类别(y)
ans =3x1单元{'setosa'} {'versicolor'} {'virginica'}
计算数据的非负级别两个近似值,以实现可视化目的。
Xred = nnmf(x,2);
原始功能将降低到两个功能。由于没有任何功能是负的,NNMF还可以保证这些功能是无负的。
使用散点图在视觉上确认三个簇。
gScatter(Xred(:,1),Xred(:,2),Y)Xlabel('第1列')ylabel(“第2列”) 网格上
也可以看看
您还可以从以下列表中选择一个网站:
美洲
- AméricaLatina(Español)
- 加拿大(英语)
- 美国(英语)