classifySound
对音频信号中的声音进行分类
语法
描述
[还返回一个包含结果详细信息的表。听起来,时间戳,resultsTable) = classifySound (___)
classifySound (___)如果没有输出参数,则在音频信号中创建一个识别声音的词云。
此功能需要音频工具箱™和深度学习工具箱™。
例子
下载classifySound
下载并解压缩音频工具箱™对YAMNet的支持。金宝app
如果没有安装对YAMNet的Audio T金宝appoolbox支持,那么对该函数的第一次调用将提供到下载位置的链接。要下载模型,请单击链接。解压文件到MATLAB路径上的一个位置。
或者,执行以下命令将YAMNet模型下载并解压缩到临时目录。
downloadFolder = fullfile (tempdir,“YAMNetDownload”);loc = websave (downloadFolder,“https://ssd.mathworks.com/金宝appsupportfiles/audio/yamnet.zip”);YAMNetLocation = tempdir;YAMNetLocation解压(loc)目录(fullfile (YAMNetLocation,“yamnet”))
识别颜色的噪音
假设采样率为16khz,生成1秒的粉色噪声。
fs = 16 e3;x = pinknoise (fs);
调用classifySound用粉色噪声信号和采样率。
identifiedSound = classifySound (x, fs)
identifiedSound = "粉红噪音"
及时识别和定位声音
读入音频信号。调用classifySound返回检测到的声音和相应的时间戳。
[audioIn, fs] = audioread (“multipleSounds-16-16-mono-18secs.wav”);(声音、时间戳)= classifySound (audioIn fs);
绘制音频信号并标记检测到的声音区域。
t =(0:元素个数(audioIn) 1) / fs;情节(t, audioIn)包含(“时间(s)”)轴([t(1),t(end),-1,1]) textHeight = 1.1;为patch([timeStamps(idx,1),timeStamps(idx,1),timeStamps(idx,2),timeStamps(idx,2)],...(1, 1, 1, 1),...(0.3010 0.7450 0.9330),...“FaceAlpha”, 0.2);文本(时间戳(idx, 1), textHeight + 0.05 * (1) ^ idx,声音(idx))结束

选择区域,只收听所选区域。
sampleStamps =地板(时间戳* fs) + 1;soundEvent =3.;isolatedSoundEvent = audioIn (sampleStamps (soundEvent 1): sampleStamps (soundEvent 2));声音(isolatedSoundEvent, fs);显示器('检测到的声音= '+声音(soundEvent))

“检测到声音=打鼾”
只识别特定的声音
读入包含多个不同声音事件的音频信号。
[audioIn, fs] = audioread (“multipleSounds-16-16-mono-18secs.wav”);
调用classifySound与音频信号和采样率。
(声音,~,soundTable) = classifySound (audioIn fs);
的听起来字符串数组包含每个区域中最可能的声音事件。
听起来
听起来=1×5弦“流水”“机关枪”“打鼾”“吠叫”“喵”
的soundTable包含关于在每个区域检测到的声音的详细信息,包括分析信号的得分均值和最大值。
soundTable
soundTable =5×2表时间戳的结果 ________________ ___________ 0 3.92}{4×3表4.0425 - 6.0025}{3×3表10.658 - 12.373 6.86 - 9.1875{表2×3}}{4×3表12.985 - 16.66{4×3表}
查看最近检测到的区域。
soundTable。结果{end}
ans =4×3表听起来AverageScores MaxScores ________________________ _____________ _________ " 动物“0.79514 - 0.99941”家畜、宠物“0.80243 - 0.99831”猫喵“0.8048 - 0.99046 0.6342 - 0.90177
调用classifySound一次。这一次,IncludedSounds来动物所以这个函数只保留了动物检测到声音类。
(声音、时间戳、soundTable) = classifySound (audioIn fs,...“IncludedSounds”,“动物”);
声音数组只返回指定为包含声音的声音。的听起来数组现在包含两个实例动物对应于声明为树皮和猫叫之前。
听起来
听起来=1×2字符串“动物”“动物”
声音表只包含检测到指定声音类的区域。
soundTable
soundTable =2×2表时间戳的结果 ________________ ___________ 12.985 - 16.66 10.658 - 12.373{4×3桌}{4×3表}
中最后检测到的区域soundTable.结果表仍然包含该区域中所有检测到的声音的统计数据。
soundTable。结果{end}
ans =4×3表听起来AverageScores MaxScores ________________________ _____________ _________ " 动物“0.79514 - 0.99941”家畜、宠物“0.80243 - 0.99831”猫喵“0.8048 - 0.99046 0.6342 - 0.90177
来研究支持哪些声音类金宝appclassifySound,使用yamnetGraph.
排除特定的声音
读入音频信号然后呼叫classifySound检查按探测时间顺序排列的最可能的声音。
[audioIn, fs] = audioread (“multipleSounds-16-16-mono-18secs.wav”);听起来= classifySound (audioIn fs)
听起来=1×5弦“流水”“机关枪”“打鼾”“吠叫”“喵”
调用classifySound再次,ExcludedSounds来猫叫排除声音猫叫从结果。之前分类为猫叫现在被归类为猫,这是它在AudioSet本体中的直接前身。
听起来= classifySound (audioIn fs,“ExcludedSounds”,“喵喵”)
听起来=1×5弦“流水”“机关枪”“呼噜”“吠叫”“猫”
调用classifySound再次,ExcludedSounds来猫.当您排除一个声音时,所有后继者也将被排除。这意味着排除声音猫也不包括声音猫叫.这个片段最初被归类为猫叫现在被归类为家畜、宠物的直接前身猫在AudioSet本体中。
听起来= classifySound (audioIn fs,“ExcludedSounds”,“猫”)
听起来=1×5弦“流水”“机关枪”“打呼”“吠叫”“家畜、宠物”
调用classifySound再次,ExcludedSounds来家畜、宠物.声音类,家畜、宠物是两者的前身吗树皮和猫叫,所以通过排除它,之前被识别为树皮和猫叫现在都被认为是家畜、宠物,这是动物.
听起来= classifySound (audioIn fs,“ExcludedSounds”,“国内的动物,宠物”)
听起来=1×5弦“流水”“机关枪”“打呼噜”“动物”“动物”
调用classifySound再次,ExcludedSounds来动物.声音类动物没有前辈。
听起来= classifySound (audioIn fs,“ExcludedSounds”,“动物”)
听起来=1×3的字符串“流水”“机关枪”“鼾声”
如果你想避免被发现猫叫和它的前任,但继续检测继任者在相同的前任,使用IncludedSounds选择。调用yamnetGraph获取所有受支持类的列表。金宝app删除猫叫和它的前任类数组中的所有类,然后调用classifySound一次。
(~、类)= yamnetGraph;classesToInclude = setxor(类,“喵喵”,“猫”,“国内的动物,宠物”,“动物”]);听起来= classifySound (audioIn fs,“IncludedSounds”classesToInclude)
听起来=1×4弦“流水”“机关枪”“打鼾”“吠叫”
生成词云
读入音频信号并收听它。
[audioIn, fs] = audioread (“multipleSounds-16-16-mono-18secs.wav”);声音(audioIn fs)
调用classifySound没有输出参数来生成检测到的声音的字云。
classifySound (audioIn fs);

修改的默认参数classifySound探究对词云的影响。
阈值=0.1;minimumSoundSeparation =
0.92;minimumSoundDuration =
1.02;classifySound (audioIn fs,...“阈值”阈值,...“MinimumSoundSeparation”minimumSoundSeparation,...“MinimumSoundDuration”, minimumSoundDuration);




输入参数
输出参数
算法
的classifySound函数使用YAMNet将音频片段分类为AudioSet本体所描述的声音类。的classifySoundfunction对音频进行预处理,使其符合YAMNet所要求的格式,并使用常见任务对YAMNet的预测进行后处理,使结果更易于解释。
后处理
通过每个521置信信号通过一个窗长为7的移动平均滤波器。
将每个信号通过窗长为3的移动中值滤波器。
使用指定的值将置信信号转换为二进制掩码
阈值.丢弃任何短于
MinimumSoundDuration.合并距离小于
MinimumSoundSeparation.
将已识别的重叠50%或更多的声音区域合并为单个区域。区域开始时间是组内所有声音中最小的开始时间。区域结束时间是组内所有声音中最大的结束时间。函数返回时间戳、声音类以及区域内声音类的平均置信度和最大置信度resultsTable.
属性可以设置声音分类的特异性级别SpecificityLevel选择。例如,假设在一个声音组中有四个声音类,它们在声音区域的平均分数如下:
水- - -0.82817流- - -0.81266细流,运球- - -0.23102倒- - -0.20732
声音类,水,流,细流,运球,倒位于AudioSet本体中,如图所示:
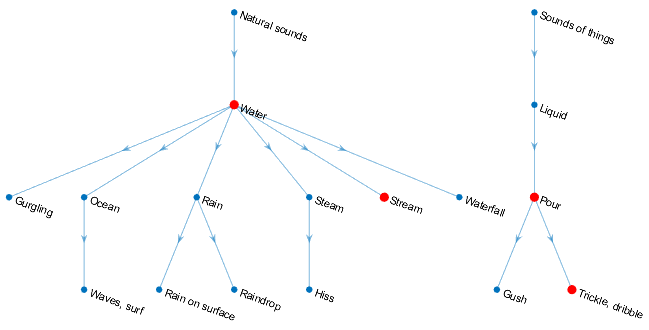
类中的声音组返回声音类听起来的输出参数SpecificityLevel:
“高”(默认)——在此模式下,流是首选水,细流,运球是首选倒.流在区域上的平均分数更高,那么函数返回流在听起来该区域的输出。“低”—在此模式中,返回对区域具有最高平均置信度的声音类的最一般的本体论类别。为细流,运球和倒,最普遍的类别是声音的东西.为流和水,最普遍的类别是自然的声音.因为水是否在声音区域有最高的平均置信度,函数返回自然的声音.“没有”——在此模式下,函数返回具有最高平均置信度的声音类,在本例中为水.
参考文献
[1] Gemmeke, Jort F., et al. <音频集:用于音频事件的本体和人类标记数据集>。2017 IEEE声学、语音和信号处理国际会议(ICASSP), IEEE, 2017, pp. 776-80。DOI.org (Crossref), doi: 10.1109 / ICASSP.2017.7952261。
Hershey, Shawn, et al. < CNN大规模音频分类架构>。2017 IEEE声学、语音和信号处理国际会议(ICASSP), IEEE, 2017,第131-35页。DOI.org (Crossref), doi: 10.1109 / ICASSP.2017.7952132。
扩展功能
另请参阅
应用程序
块
功能
你也可以从以下列表中选择一个网站: