pitchnn
深度学习神经网络估算音高
句法
描述
pitchnn (___的)没有输出参数随时间绘制估计的基频。
例子
下载Crepe Network.
下载并解压缩绉纱的音频工具箱™型号。
类型绉在命令窗口。如果未安装repe的音频工具箱模型,则该函数提供了链接到网络权重的位置。要下载模型,请单击链接并将文件解压缩到MATLAB路径上的位置。
或者,执行这些命令以将Crepe模型下载并解压缩到临时目录。
downloadfolder = fullfile(tempdir,“crepeDownload”);loc = websave (downloadFolder,'https://ssd.mathwands.com/金宝appsupportfiles/audio/crepe.zip');crepeLocation = tempdir;crepeLocation解压(loc)目录(fullfile (crepeLocation,'绉'))
输入以下命令,检查安装是否成功绉在命令窗口。如果安装了网络,则该函数返回aDagnetwork.(深度学习工具箱)对象。
绉
ANS =具有属性的Dagnetwork:图层:[34×1 nnet.cnn.layer.layer]连接:[33×2表] InputNames:{'输入'} OutputNames:{'音高'}
距估计与pitchnn
Crepe网络要求您预处理音频信号以生成可以用作网络输入的缓冲,重叠和归一化的音频帧。这个例子演示了pitchnn功能为您执行所有这些步骤。
在音频信号中读取音高估计。可视化并收听音频。音频剪辑中有九个声音。
[audioIn, fs] = audioread (“SingingAMajor-16-mono-18secs.ogg”);Soundsc(AudioIn,FS)T = 1 / FS;T = 0:T :(长度(AUDION)* T) - T;绘图(t,audioin);网格在轴紧包含(“时间(s)”) ylabel (“Ampltiude”)标题(“在一个专业中唱歌”的)

使用pitchnn函数使用CREPE网络产生基音估计ModelCapacity.设置为小和Concidencethreshold.禁用。调用pitchnn没有输出参数随时间绘制音高估计。如果你打电话pitchnn在下载模型之前,一个错误被打印到带有下载链接的命令窗口。
pitchnn (audioIn fs,'modelcapacity'那'微小的'那'ConcidenceThreshold', 0)
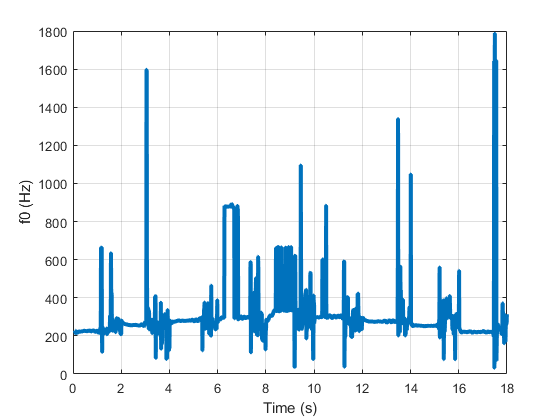
禁用自信地禁用,pitchnn为每个帧提供音高估计。增加Concidencethreshold.到0.8.
pitchnn (audioIn fs,'modelcapacity'那'微小的'那'ConcidenceThreshold', 0.8)

称呼pitchnn与ModelCapacity.设置为满的.有九个主要间距估计分组,每个组与九个声音话语之一对应。
pitchnn (audioIn fs,'modelcapacity'那“全部”那'ConcidenceThreshold', 0.8)

称呼谱图并将信号的频率内容与音高估计进行比较pitchnn.使用帧大小250.样本和重叠的225样品或90%。利用4096.变换的DFT点。
光谱图(fs audioIn, 250225年,4096年,“桠溪”的)

输入参数
输出参数
参考文献
[1] Kim,Jong Wook,Justin Salamon,Peter Li和Juan Pablo Bello。“绉纱:音高估计的卷积象征。”在2018 IEEE音响,语音和信号处理国际会议(ICASSP), 161 - 65。卡尔加里,AB: IEEE, 2018。https://doi.org/10.1109/ICASSP.2018.8461329。
扩展能力
你也可以从以下列表中选择一个网站: