演讲者日记使用x向量
讲话者日记是根据讲话者身份将音频信号分成若干段的过程。它在不知道说话者的情况下回答了“谁在什么时候说话”的问题,根据应用程序,也不知道说话者的数量。
讲话者日记有很多应用,包括:根据主动讲话者组织文本,增强语音转录,视频字幕,内容检索(简说了什么?)及扬声器计数(有多少人在会上发言?).
在本例中,您使用预先训练的x向量系统进行说话人日记[1]用凝聚层次聚类(AHC)对相似的音频区域进行分组[2].要了解x向量系统是如何定义和训练的,请参见使用x向量的说话人识别。
加载音频信号
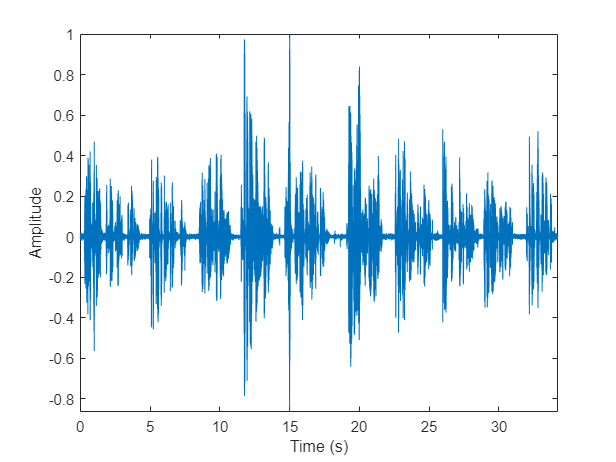
加载一个音频信号和一个包含ground truth注释的表。这个信号由五个扬声器组成。听音频信号并绘制其时域波形。
[audioIn, fs] = audioread (“exampleconversation.flac”);负载(“exampleconversationlabels.mat”) audioIn = audioIn./max(abs(audioIn));sound(audioIn,fs) t = (0:size(audioIn,1)-1)/fs;图(1)情节(t, audioIn)包含(“时间(s)”) ylabel (“振幅”)轴紧
提取x-vectors
在这个例子中,您使用了一个预先训练好的x向量系统。x矢量系统是一个轻量级版本的原始x矢量系统描述[1].要了解x向量系统是如何定义和训练的,请参见使用x向量的说话人识别。
加载预训练的x-矢量系统
装载轻型预训练的x矢量系统。x-向量系统包括:
afe——一个audioFeatureExtractor目的提取mel频率倒谱系数(MFCCs)。因素-一个结构,包含从一个代表性数据集确定的mfc的平均值和标准偏差。这些因素被用来对mfc进行标准化。器-包含用于提取x向量的神经网络的参数和状态的结构体。的xvecModel函数执行实际的x向量提取。的xvecModel函数被放置在当前文件夹中。分类器一个结构,包含训练有素的投影矩阵来降低x向量的维数,以及训练有素的PLDA模型来评分x向量。
负载(“xvectorSystem.mat”)
提取标准化声学特征
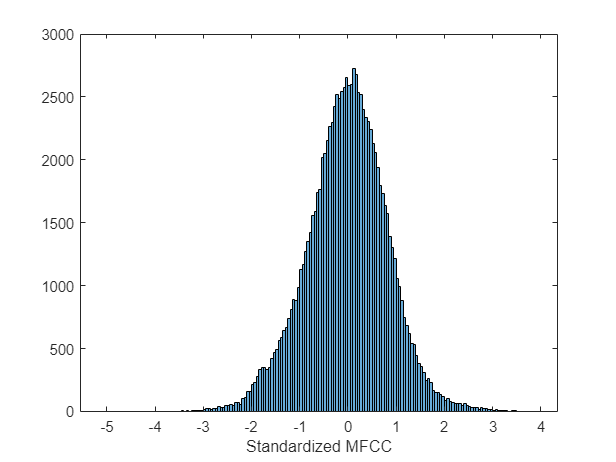
从音频数据中提取标准化的MFCC特性。查看特征分布,确认从一个单独的数据集学到的标准化因素大致标准化了本例中派生的特征。标准分布的均值为0,标准差为1。
特点=单((提取(afe, audioIn) -factors.Mean)。/ factors.STD);图(2)直方图(特性)包含(“标准化MFCC”)
提取x-Vectors
每个声学特征向量代表大约0.01秒的音频数据。将这些特征分成大约2秒的片段,片段之间有0.1秒的跳跃。
featureVectorHopDur = (numel(afe.Window) - afe.OverlapLength)/afe.SampleRate;segmentDur =2;segmentHopDur =
0.1;segmentLength =圆(segmentDur / featureVectorHopDur);segmentHop =圆(segmentHopDur / featureVectorHopDur);idx = 1: segmentLength;featuresSegmented = [];而idx(end) < size(features,1) featuressegved = cat(3, featuressegved,features(idx,:)));idx = idx + segmentHop;结束


从每段中提取x向量。x向量对应于使用x向量训练的说话人识别x向量模型中第7层的输出。对时间膨胀的帧级层进行统计后,第7层为第一段级层。形象化x向量随时间的变化。
outputLayer = 7;xvecs = 0(元素个数(extractor.Parameters。(“俱乐部”+ outputLayer) .Bias)、大小(featuresSegmented, 3));为dlX = dlarray(feature segmentation (:,:,sample)),“渣打银行”);xvecs(:,示例)= extractdata (xvecModel (dlX、extractor.Parameters extractor.State,“DoTraining”假的,“OutputLayer”outputLayer));结束图(3)冲浪(xvecs ',“EdgeColor”,“没有”视图([90,-90])轴([1 size(xvecs,1) 1 size(xvecs,2)]) xlabel(“特性”) ylabel (“段”)
应用预先训练的线性判别分析(LDA)投影矩阵来降低x向量的维数,然后将x向量随时间的变化可视化。
x = classifier.projMat * xvecs;图(4)冲浪(x ',“EdgeColor”,“没有”)视图((90、-90))轴([1大小(x, 1) 1大小(x, 2)])包含(“特性”) ylabel (“段”)
集群x-vectors
x向量系统学习提取扬声器的紧凑表示(x向量)。使用凝聚层次聚类将x向量聚类到音频的相似区域(clusterdata(统计学和机器学习工具箱))或k-means聚类(kmeans(统计学和机器学习工具箱)).[2]建议使用聚类分层聚类与PLDA评分作为距离度量。使用余弦相似度评分的k -均值聚类也常用。假设预先知道音频中扬声器的数量。将最大聚类设置为已知发言者的数量+ 1,以便背景独立聚类。
knownNumberOfSpeakers =元素个数(独特(groundTruth.Label));maxclusters = knownNumberOfSpeakers + 1;clusterMethod ='凝聚- PLDA评分';开关clusterMethod情况下'凝聚- PLDA评分'T = clusterdata (x ',“标准”,“距离”,“距离”@ (a, b) helperPLDAScorer (a, b,分类器),“链接”,“平均”,“maxclust”, maxclusters);情况下'凝聚- CSS评分'T = clusterdata (x ',“标准”,“距离”,“距离”,的余弦,“链接”,“平均”,“maxclust”, maxclusters);情况下'kmeans - CSS评分'maxclusters T = kmeans (x ',“距离”,的余弦);结束

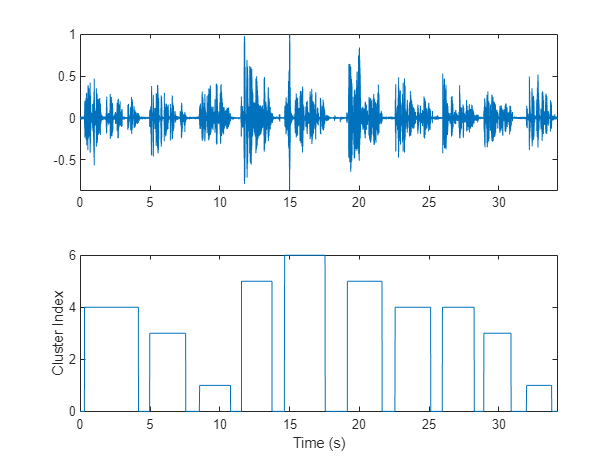
绘制随时间变化的集群决策。
图(5)tiledlayout(2,1) nexttile plot(t,audioIn)轴紧ylabel (“振幅”)包含(“时间(s)”) nexttile plot(T) axis紧ylabel (“集群指数”)包含(“段”)
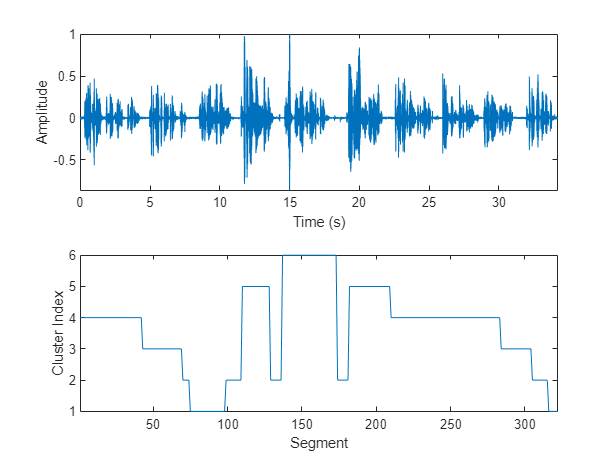
为了分离与聚类对应的语音片段,将这些片段映射回音频样本。策划的结果。
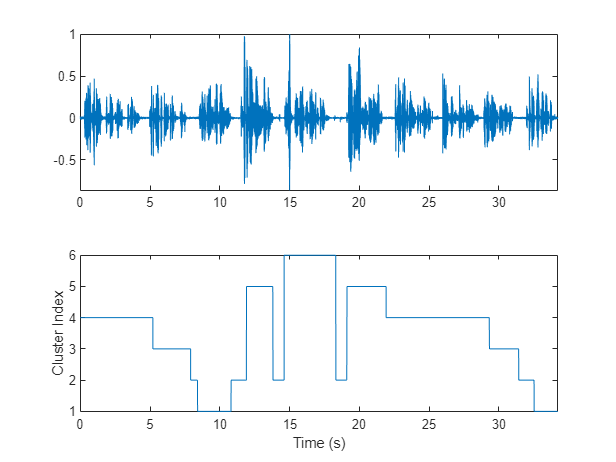
掩码= 0(大小(audioIn, 1), 1);开始=圆((segmentDur / 2) * fs);segmentHopSamples =圆(segmentHopDur * fs);面具(1:开始)= T (1);Start = Start + 1;为ii = 1:numel(T) finish = start + segmentHopSamples;mask(start:start + segmentHopSamples) = T(ii);Start = finish + 1;结束面具(完成:结束)= T(结束);图(6)tiledlayout(2,1) nexttile plot(t,audioIn)轴紧nexttile情节(t,面具)ylabel (“集群指数”)轴紧包含(“时间(s)”)
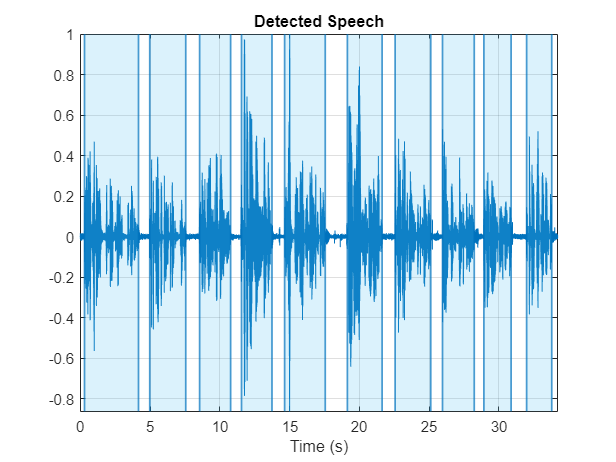
使用detectSpeech来确定语音区域。使用sigroi2binmask将语音区域转换为二进制语音活动检测(VAD)掩码。调用detectSpeech第二次不带任何参数来绘制检测到的语音区域。
mergeDuration =0.5;VADidx = detectSpeech (audioIn fs,“MergeDistance”fs * mergeDuration);VADmask = sigroi2binmask (VADidx元素个数(audioIn));图(7)detectSpeech (audioIn fs,“MergeDistance”, fs * mergeDuration)

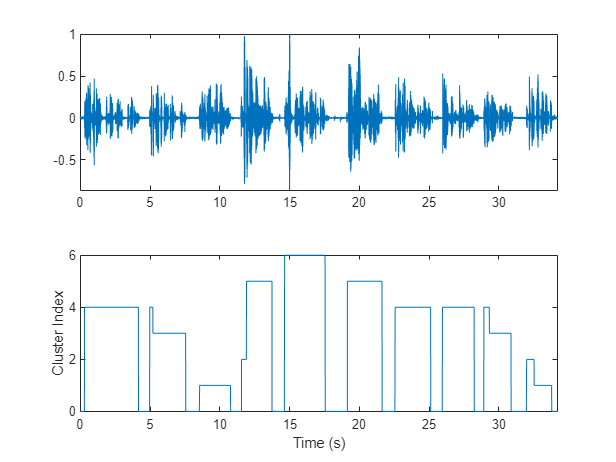
将VAD掩码应用于扬声器掩码,并绘制结果。聚类索引为0表示无语音区域。
掩码=面具。* VADmask;图(8)tiledlayout(2,1) nexttile plot(t,audioIn)轴紧nexttile情节(t,面具)ylabel (“集群指数”)轴紧包含(“时间(s)”)
在本例中,假定每个检测到的语音区域都属于一个单独的说话者。如果一个语音区域中有两个以上的标签,将它们合并到最常出现的标签中。
maskLabels = 0(大小(VADidx, 1), 1);为maskLabels(ii) = mode(mask(VADidx(ii,1):VADidx(ii,2)),“所有”);面具(VADidx (2, 1): VADidx (2, 2)) = maskLabels (ii);结束图(9)tiledlayout(2,1) nexttile plot(t,audioIn)轴紧nexttile情节(t,面具)ylabel (“集群指数”)轴紧包含(“时间(s)”)
计算剩下的发言者集群的数量。
uniqueSpeakerClusters =独特(maskLabels);numSpeakers =元素个数(uniqueSpeakerClusters)
numSpeakers = 5
可视化Diarization结果
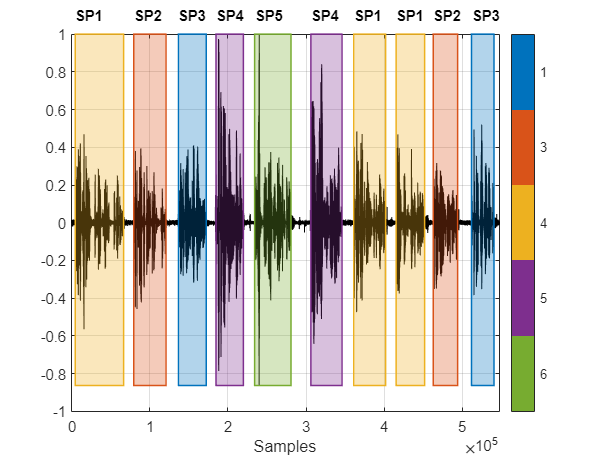
创建一个signalMask对象,然后画出说话者群。给情节贴上真实的标签。集群标签用颜色编码,在图的右侧有一个键。真正的标签印在图的上方。
msk = signalMask(表(VADidx分类(maskLabels)));图(10)plotsigroi(msk,audioIn,true) axis([0 numel(audioIn) -1 1]) trueLabel = groundTruth.Label;为text(VADidx(ii,1),1.1,trueLabel(ii)),“FontWeight”,“大胆”)结束
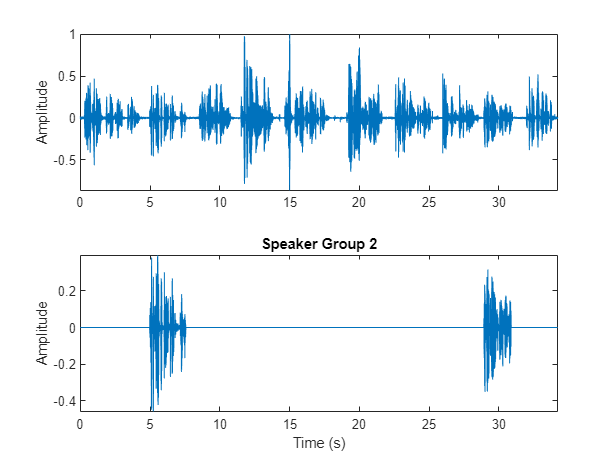
选择要检查并使用的集群binmask孤立说话者。画出孤立的语音信号,并听讲话者群。
speakerToInspect =2;cutOutSilenceFromAudio =
真正的;bmsk = binmask (msk的元素个数(audioIn));audioToPlay = audioIn;如果cutOutSilenceFromAudio audioToPlay(~bmsk(:,speakerToInspect)) = [];结束sound(audioToPlay,fs) figure(11) tiledlayout(2,1) nexttile plot(t,audioIn) axis紧ylabel (“振幅”) nexttile plot(t,audioIn.*bmsk(:,speakerToInspect))轴紧包含(“时间(s)”) ylabel (“振幅”)标题(“议长集团”+ speakerToInspect)


Diarization系统评估
扬声器日记系统的常用度量是日记错误率(DER)。DER是缺失率(将语音分类为非语音)、误报率(将非语音分类为语音)和说话人错误率(将一个说话人的语音混淆为另一个说话人的语音)的总和。
在这个简单的例子中,漏报率和误报率都是微不足道的问题。你只评估说话者的错误率。
将每个真正的扬声器映射到相应的最适合的扬声器集群。为了确定说话人的错误率,计算真实说话人与最适合的说话人簇之间的不匹配数量,然后除以真实说话人区域的数量。
uniqueLabels =独特(trueLabel);guessLabels = maskLabels;uniqueGuessLabels =独特(guessLabels);totalNumErrors = 0;为ii = 1:numel(uniquelabel) isSpeaker = uniquelabel (ii)==trueLabel;minNumErrors =正;为jj = 1:numel(uniqueGuessLabels) groupCandidate = uniqueGuessLabels(jj) == guessLabels;numErrors = nnz (isSpeaker-groupCandidate);如果numErrors < minNumErrors minNumErrors = numErrors;bestCandidate = jj;结束minNumErrors = min (minNumErrors numErrors);结束uniqueGuessLabels (bestCandidate) = [];totalNumErrors = totalNumErrors + minNumErrors;结束SpeakerErrorRate = totalNumErrors /元素个数(trueLabel)
SpeakerErrorRate = 0
参考文献
[1] Snyder, David等,《x -向量:用于说话人识别的鲁棒DNN嵌入》。2018 IEEE声学、语音和信号处理国际会议(ICASSP), IEEE, 2018,第5329-33页。DOI.org (Crossref), doi: 10.1109 / ICASSP.2018.8461375。
Sell, G., Snyder, D., McCree, A., Garcia-Romero, D., Villalba, J., Maciejewski, M., Manohar, V., Dehak, N., Povey, D., Watanabe, S., Khudanpur, S. (2018) Diarization is Hard: Some Experiences and Lessons Learned for the JHU Team in the首届DIHARD挑战赛。Interspeech.2018, 2808-2812, DOI: 10.21437/Interspeech.2018-1893。
你也可以从以下列表中选择一个网站: